





Scrapy framework to solve lots of common web scraping problems.
Scrapy框架可解决许多常见的Web抓取问题。
Today we are going to take a look at Selenium and BeautifulSoup (with Python ❤️ ) with a step by step tutorial.
今天,我们将通过逐步教程来学习Selenium和BeautifulSoup(使用Python❤️)。
是时候使用Selenium了 (It’s time to use Selenium)
Selenium refers to a number of different open-source projects used for browser automation. It supports bindings for all major programming languages, including our favorite language: Python.
Selenium是指用于浏览器自动化的许多不同的开源项目。 它支持所有主要编程语言的绑定,包括我们最喜欢的语言:Python。
The Selenium API uses the WebDriver protocol to control a web browser, like Chrome, Firefox or Safari. The browser can run either localy or remotely.
Selenium API使用WebDriver协议来控制Web浏览器,例如Chrome,Firefox或Safari。 该浏览器可以在本地或远程运行。
At the beginning of the project (almost 20 years ago!) it was mostly used for cross-browser end-to-end testing (acceptance tests).
在项目开始时(差不多20年前!),它主要用于跨浏览器的端到端测试(验收测试)。
Now it is still used for testing, but also as a general browser automation platform and of course, web scraping!
现在它仍然用于测试,还可以用作通用的浏览器自动化平台,当然还可以用作网络抓取!
Selenium is really useful when you have to perform action on a website such as:
当您必须在以下网站上执行操作时,Selenium确实很有用:
* clicking on buttons
* filling forms
* scrolling
* taking a screenshotIt is also very useful in order to execute Javascript code. Let’s say that you want to scrape a Single Page application, and that you don’t find an easy way to directly call the underlying APIs, then Selenium might be what you need.
这对于执行Javascript代码也非常有用。 假设您要抓取单页应用程序,而找不到直接调用底层API的简便方法,那么Selenium可能就是您所需要的。
安装 (Installation)
We will use Chrome in our example, so make sure you have it installed on your local machine:
我们将在示例中使用Chrome,因此请确保已将其安装在本地计算机上:
* Chrome download page
* Chrome driver binary
* selenium packageIn order to install the Selenium package, as always, I recommend that you create a virtual environnement, using virtualenv for example, and then:
为了像往常一样安装Selenium软件包,我建议您创建一个虚拟环境,例如,使用virtualenv,然后:
# !pip install selenium快速开始 (Quickstart)
Once you have downloaded both Chrome and Chromedriver, and installed the selenium package you should be ready to start the browser:
下载完Chrome和Chromedriver之后,并安装了Selenium包,您应该可以启动浏览器了:
from selenium import webdriver
DRIVER_PATH = './chromedriver' #the path where you have "chromedriver" file.
driver = webdriver.Chrome(executable_path=DRIVER_PATH)
driver.get('https://google.com')This will launch Chrome in headfull mode (like a regular Chrome, which is controlled by your Python code). You should see a message stating that the browser is controlled by an automated software.
这将以完全模式启动Chrome(就像由您的Python代码控制的常规Chrome一样)。 您应该看到一条消息,指出浏览器是由自动化软件控制的。
In order to run Chrome in headless mode (without any graphical user interface), to run it on a server for example:
为了以无头模式(没有任何图形用户界面)运行Chrome,例如在服务器上运行它:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.headless = True
options.add_argument("--window-size=1920,1200")
driver = webdriver.Chrome(options=options, executable_path=DRIVER_PATH)
driver.get("https://www.thewindpower.net/country_media_es_3_espana.php")
#print(driver.page_source)
driver.quit()The driver.page_source will return the full page HTML code.
driver.page_source将返回整页HTML代码。
Here are two other interesting webdriver properties:
这是另外两个有趣的webdriver属性:
* driver.title to get the page's title
* driver.current_url to get the current url (can be useful when there are redirections on the website and that you need the final URL)定位元素 (Locating elements)
Locating data on a website is one of the main use cases for Selenium, either for a test suite (making sure that a specific element is present/absent on the page) or to extract the data and save it for further analysis (web scraping).
在网站上查找数据是Selenium的主要用例之一,可以用于测试套件(确保页面上存在/不存在特定元素),也可以提取数据并将其保存以进行进一步分析(网页抓取) 。
There are many methods available in the Selenium API to select elements on the page. You can use:
Selenium API中提供了许多方法来选择页面上的元素。 您可以使用:
* Tag name
* Class name
* IDs
* XPath
* CSS selectorsAs usual, the easiest way to locate an element is to open your Chrome dev tools and inspect the element that you need. A cool shortcut for this is to highlight the element you want with your mouse, and then Ctrl + Shift + C or on macOS cmd + shift + c instead of having to right click + inspect each time:
通常,查找元素的最简单方法是打开Chrome开发工具并检查所需的元素。 一个很酷的捷径是用鼠标突出显示您想要的元素,然后按Ctrl + Shift + C或在macOS cmd + Shift + c上,而不必每次单击右键+检查:
开始干活 (Let´s work)
In this tutorial we will build a web scraping program that will scrape a Github user profile and get the Repository Names and the Languages for the Pinned Repositories.
在本教程中,我们将构建一个Web抓取程序,该程序将抓取Github用户配置文件并获取存储库名称和固定存储库的语言。
我们需要什么? (What will we require?)
For this project we will use Python3.x.
对于此项目,我们将使用Python3.x。
We will also use the following packages and driver:
我们还将使用以下软件包和驱动程序:
* selenium package — used to automate web browser interaction from Python
* ChromeDriver — provides a platform to launch and perform tasks in specified browser.
* Virtualenv — to create an isolated Python environment for our project.
* Extras: Selenium-Python ReadTheDocs Resource.项目设置 (Project SetUp)
Create a new project folder. Within that folder create an setup.py file. In this file, type in our dependency selenium.
创建一个新的项目文件夹。 在该文件夹中创建一个setup.py文件。 在此文件中,输入我们的依赖Selenium。
# Create the file using "shell-terminal"
! touch setup.py# Type the dependency selenium
! echo "selenium" > setup.pyOpen up your command line & create a virtual environment using the basic command:
使用基本命令打开命令行并创建虚拟环境:
#! pip install virtualenv# Create virtualenv
! virtualenv webscraping_examplecreated virtual environment CPython3.7.6.final.0-64 in 424ms
creator CPython3Posix(dest=/home/oscar/Documentos/Medium/Selenium/webscraping_example, clear=False, global=False)
seeder FromAppData(download=False, pip=bundle, setuptools=bundle, wheel=bundle, via=copy, app_data_dir=/home/oscar/.local/share/virtualenv)
added seed packages: pip==20.2.1, setuptools==49.2.1, wheel==0.34.2
activators BashActivator,CShellActivator,FishActivator,PowerShellActivator,PythonActivator,XonshActivatorActivate virtualenv
激活virtualenv

Next, install the dependency into your virtualenv by running the following command in the terminal:
接下来,通过在终端中运行以下命令将依赖项安装到您的virtualenv中:
#! pip install -r setup.py导入所需的模块 (Import Required Modules)
Within the folder we created earlier, create a webscraping_example.py file and include the following code snippets.
在我们之前创建的文件夹中,创建一个webscraping_example.py文件,并包含以下代码片段。
# Create the file using "shell-terminal"
! touch webscraping_example/webscraping_example.py# Use shell-terminal
#! vim webscraping_example/webscraping_example.py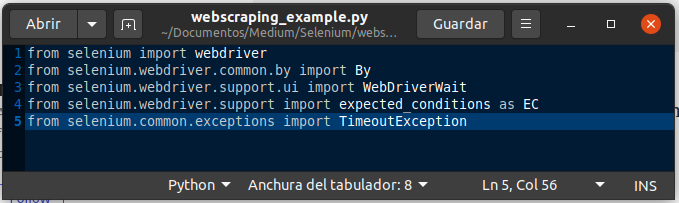
1st import: Allows you to launch/initialise a browser.
2nd import: Allows you to search for things using specific parameters.
3rd import: Allows you to wait for a page to load.
4th import: Specify what you are looking for on a specific page in order to determine that the webpage has loaded.
5th import: Handling a timeout situation.from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException在隐身模式下创建新的Chrome实例 (Create new instance of Chrome in Incognito mode)
First we start by adding the incognito argument to our webdriver.
首先,我们将隐身参数添加到我们的webdriver中。
options = Options()
options.add_argument("--incognito")Next we create a new instance of Chrome.
接下来,我们创建一个新的Chrome实例。
DRIVER_PATH = './chromedriver'
browser = webdriver.Chrome(options=options, executable_path=DRIVER_PATH)One thing to note is that the executable_path is the path that points to where you downloaded and saved your ChromeDriver.
需要注意的一件事是,executable_path是指向您下载和保存ChromeDriver的路径。
提出要求 (Make The Request)
When making the request we need to consider the following:
发出请求时,我们需要考虑以下几点:
* Pass in the desired website url.
* Implement a Try/Except for handling a timeout situation should it occur.In our case we are using “thewindpower.net” as the desired website url:
在我们的例子中,我们使用“ thewindpower.net”作为所需的网站URL:
browser.get("https://www.thewindpower.net/country_media_es_3_espana.php")通过页面检查找到元素并找到目标: (Locating elements & finding the target one by page inspection:)
items = len(browser.find_elements_by_class_name("lien_standard"))
items1232elems = browser.find_elements_by_class_name("lien_standard")Get URL
取得网址
links = [elem.get_attribute('href') for elem in elems]Show the first lines
显示第一行
links[:5]['https://www.thewindpower.net/windfarm_es_4418_cortijo-de-guerra-ii.php',
'https://www.thewindpower.net/windfarm_es_695_es-mila.php',
'https://www.thewindpower.net/windfarm_es_5281_la-castellana-(spain).php',
'https://www.thewindpower.net/windfarm_es_7024_valdeperondo.php',
'http://zigwen.free.fr/']# initializing start Prefix
start_letter = 'https://'
result = [x for x in links if x.startswith(start_letter)]result[0:20]['https://www.thewindpower.net/windfarm_es_4418_cortijo-de-guerra-ii.php',
'https://www.thewindpower.net/windfarm_es_695_es-mila.php',
'https://www.thewindpower.net/windfarm_es_5281_la-castellana-(spain).php',
'https://www.thewindpower.net/windfarm_es_7024_valdeperondo.php',
'https://www.thewindpower.net/windfarm_es_1922_a-capelada-i.php',
'https://www.thewindpower.net/windfarm_es_1919_a-capelada-ii.php',
'https://www.thewindpower.net/windfarm_es_10582_abuela-santa-ana.php',
'https://www.thewindpower.net/windfarm_es_19392_abuela-santa-ana-modificacion.php',
'https://www.thewindpower.net/windfarm_es_1920_adrano.php',
'https://www.thewindpower.net/windfarm_es_13465_aeropuerto-la-palma.php',
'https://www.thewindpower.net/windfarm_es_3865_aguatona.php',
'https://www.thewindpower.net/windfarm_es_2077_aibar.php',
'https://www.thewindpower.net/windfarm_es_9722_aibar.php',
'https://www.thewindpower.net/windfarm_es_2062_aizkibel.php',
'https://www.thewindpower.net/windfarm_es_2063_aizkibel.php',
'https://www.thewindpower.net/windfarm_es_21500_alaiz.php',
'https://www.thewindpower.net/windfarm_es_2083_alaiz.php',
'https://www.thewindpower.net/windfarm_es_2084_alaiz.php',
'https://www.thewindpower.net/windfarm_es_2106_alcarama-i.php',
'https://www.thewindpower.net/windfarm_es_2105_alcarama-i.php']len(result)603是时候使用BeautifulSoup (It’s time to use BeautifulSoup)
Once we have obtained the URLs where the data is stored, we will use the BeautifulSoup library.
一旦获得了存储数据的URL,我们将使用BeautifulSoup库。
加载库 (Load the libraries)
import pandas as pd
import requests
from bs4 import BeautifulSoup创建功能 (Create functions)
First, we create a function to get text from each websites and second we create another function to convert the list to dataframe
首先,我们创建一个从每个网站获取文本的函数,其次我们创建另一个将列表转换为数据框的函数
def obtener(url):
req = requests.get(url)
soup = BeautifulSoup(req.content, 'html.parser')
lista=[]
resulta = soup.find_all('li', {'class': 'puce_texte'})
for item in resulta:
text = item.text
text=str(text).replace("ó","o")
text=str(text).replace("Ã","i")
text=str(text).replace("ñ","n")
text=str(text).replace("í","i")
text=str(text).replace("°","°")
text=str(text).replace("é","e")
text=str(text).replace("á","a")
text=str(text).replace("\' ","' ")
text=str(text).replace("<br/>","")
text=str(text).replace("\n","")
text=str(text).replace("Operativo","Operativo : si")
text=str(text).replace("Parque eolico onshore","Parque eolico onshore : si")
text=str(text).replace("Imágenes de Google Maps","Imágenes de Google Maps : si")
lista.append(text)
return lista
def dataframe(lista):
datos= [i.split(': ', 1)[-1] for i in lista]
columna= [i.split(' :', 1)[0] for i in lista]
columnas =[career.lstrip('0123456789) ') for career in columna]
df = pd.DataFrame(datos).transpose()
df.columns=columnas
df = df.loc[:,~df.columns.duplicated()]
#df=df[['Nombre del parque eolico', 'Ciudad', 'Latitud','Longitud','Potencia nominal total' ]]
return dfLet’s see the result of the first 10 lines
让我们看一下前10行的结果
result_first = result[:10]
result_first['https://www.thewindpower.net/windfarm_es_4418_cortijo-de-guerra-ii.php',
'https://www.thewindpower.net/windfarm_es_695_es-mila.php',
'https://www.thewindpower.net/windfarm_es_5281_la-castellana-(spain).php',
'https://www.thewindpower.net/windfarm_es_7024_valdeperondo.php',
'https://www.thewindpower.net/windfarm_es_1922_a-capelada-i.php',
'https://www.thewindpower.net/windfarm_es_1919_a-capelada-ii.php',
'https://www.thewindpower.net/windfarm_es_10582_abuela-santa-ana.php',
'https://www.thewindpower.net/windfarm_es_19392_abuela-santa-ana-modificacion.php',
'https://www.thewindpower.net/windfarm_es_1920_adrano.php',
'https://www.thewindpower.net/windfarm_es_13465_aeropuerto-la-palma.php']获取数据框中的数据 (Get data in a Dataframe)
Finally, using the list of URLs obtained with the selenium library, we generate our dataset with all the data obtained
最后,使用通过Selenium库获得的URL列表,我们使用获得的所有数据生成数据集
DATA=pd.DataFrame()
for i in result:
lista=obtener(i)
DF=dataframe(lista)
DATA=DATA.append(DF,ignore_index=True)This is the result
这是结果
DATA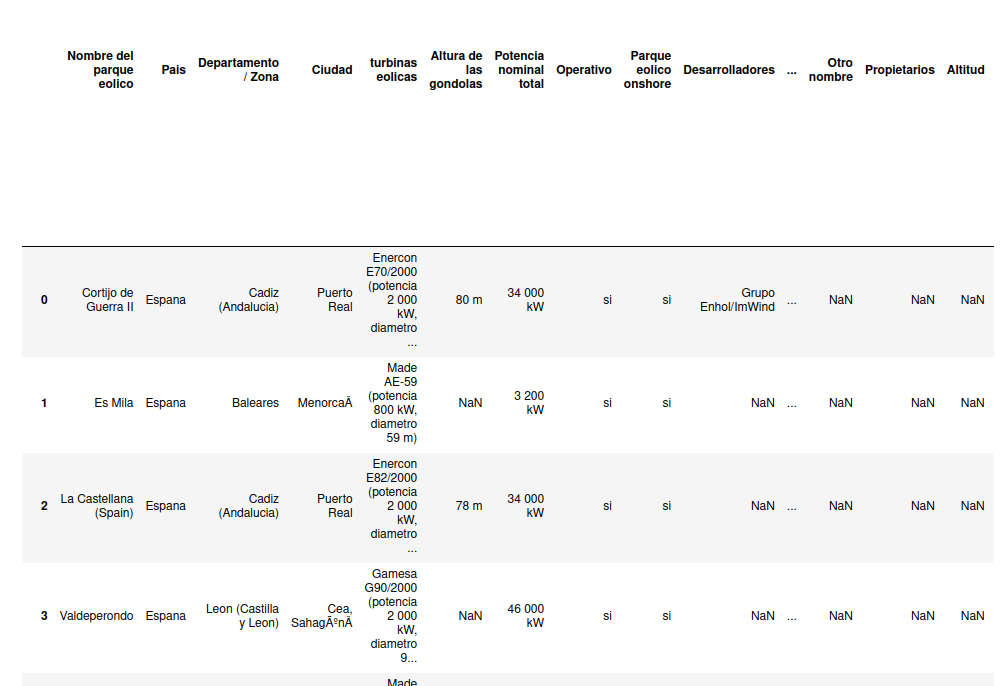
保存数据 (Save data)
And finally we save the data
最后我们保存数据
DATA.to_csv(r'datos_eolicos.csv')结论 (Conclusion)
As you can see with a couple of libraries we have been able to obtain the url and data of the wind farms located in Spain
如您所见,通过几个库,我们已经能够获得位于西班牙的风电场的网址和数据
I hope you enjoy this project
我希望你喜欢这个项目
No matter what books or blogs or courses or videos one learns from, when it comes to implementation everything might look like “Out of Syllabus”
无论从中学到什么书,博客,课程或视频,到实施时,一切都可能看起来像“课程提纲”
Best way to learn is by doing!Best way to learn is by teaching what you have learned!
Best way to learn is by doing!Best way to learn is by teaching what you have learned!
永不放弃! (Never give up!)
See you in Linkedin!
在Linkedin上见!
翻译自: https://medium.com/swlh/web-scraping-using-selenium-and-beautifulsoup-adfc8810240a


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









