



In this article we’ll build a simple convolutional neural network in PyTorch and train it to recognize handwritten digits using the MNIST dataset.
在本文中,我们将在PyTorch中构建一个简单的卷积神经网络,并使用MNIST数据集训练它来识别手写数字。
Figuring out this sequence of numbers is easy, even though the resolution is distorted and the shape of the digits is irregular. Thanks to our brains, which made this process feel natural. We should, of course, also be thankful to ourselves, having spent years learning and applying the numbers in our day-to-day lives.
即使分辨率失真并且数字的形状不规则,也很容易弄清楚数字的顺序。 多亏了我们的大脑,这使这一过程变得自然。 当然,我们也应该感谢自己,花了多年的时间学习并将这些数字应用到我们的日常生活中。
第1步-了解您的数据 (Step 1 — Know Your Data)
Data can tell you a lot if you ask the right questions.
如果您提出正确的问题,数据可以告诉您很多信息。
To understand data, data scientists spends most of their time gathering datasets and preprocessing them. Further tasks are comparatively easy.
为了理解数据,数据科学家花费大量时间来收集数据集并进行预处理。 进一步的任务相对容易。
We will be using the popular MNIST database. It is a collection of 70000 handwritten digits split into training and test set of 60000 and 10000 images respectively. Before starting, we need to make all the necessary imports.
我们将使用流行的MNIST数据库。 它是70000个手写数字的集合,分别分为60000个图像和10000个图像的训练和测试集。 开始之前,我们需要进行所有必要的导入。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms第2步-准备数据集 (Step 2 — Preparing the Dataset)
Before downloading the data, let us define the hyperparameters and transformations we’ll be using for the experiment we want to perform on our data before feeding it into the pipeline. In other words, these samples are not the same size. Neural networks will require images to be of same dimensions and properties. We do it using torchvision.transforms. Here the number of epochs defines how many times we’ll loop over the complete training dataset, while learning_rate and momentum are hyperparameters for the optimizer we'll be using later on and batch_size is the number of images we want to read in one go.
在下载数据之前,让我们定义将要用于数据的超参数和转换,然后再将其输入管道。 换句话说,这些样本的大小不同。 神经网络将要求图像具有相同的尺寸和属性。 我们使用torchvision.transforms做到这torchvision.transforms 。 这里的时期数定义了我们将在整个训练数据集上循环多少次,而learning_rate和momentum是我们稍后将使用的优化程序的超参数,而batch_size是我们要一次性读取的图像数。
batch_size = 128
momentum_value = 0.9
epochs = 20
learning_rate = 0.01For repeatable experiments we have to set random seeds for anything using random number generation, so that when next time I come and run the code it will give me same output.
对于可重复的实验,我们必须使用随机数生成为任何对象设置随机种子,以便下次我运行该代码时,它会提供相同的输出。
torch.manual_seed(1)
kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True, **kwargs)test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True, **kwargs)datasets.MNIST we are downloading the MNIST dataset for training and testing at path ../data
datasets.MNIST我们正在下载的训练数据集MNIST和路径测试../data
transforms.Compose(): This clubs all the transforms provided to it. Compose is applied to the inputs one by one.
transforms.Compose() :这会将所有提供给它的转换合并在一起。 Compose一一应用于输入。
transforms.ToTensor() — converts the image into numbers, that are understandable by the system. It separates the image into three color channels (separate images): red, green & blue. Then it converts the pixels of each image to the brightness of their color between 0 and 255. These values are then scaled down to a range between 0 and 1. The image is now a Torch Tensor.
transforms.ToTensor() —将图像转换为系统可以理解的数字。 它将图像分为三个颜色通道(独立图像):红色,绿色和蓝色。 然后,它将每个图像的像素转换为0到255之间的颜色亮度。然后将这些值缩小到0到1之间的范围。图像现在是Torch Tensor。
transforms.Normalize() — normalizes the tensor with a mean and standard deviation which goes as the two parameters respectively.
transforms.Normalize() —使用均值和标准差对张量进行规格化,分别作为两个参数。
torch.utils.data.DataLoader we make Data iterable by loading it to a loader.
torch.utils.data.DataLoader我们通过将数据加载到加载器来使其可迭代。
shuffle=True Shuffle the training data to make it independent of the order
shuffle=True随机调整训练数据,使其与顺序无关
步骤3 —建立神经网络 (Step 3 — Building a Neural Network)
We will be building the following network, as you can see it contains seven Convolution layer, two Max pooling layer two Transition layer followed by Avg pooling layer.
我们将构建以下网络,您将看到它包含七个Convolution layer ,两个Max pooling layer两个Transition layer然后是Avg pooling layer 。
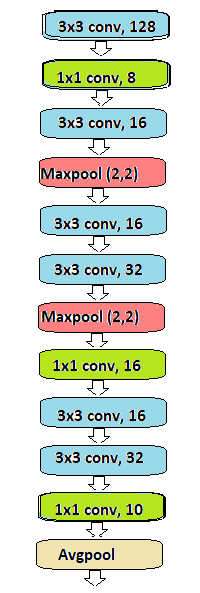
In PyTorch a nice way to build a network is by creating a new class. PyTorch’s torch.nn module allows us to build the above network very simply. It is extremely easy to understand as well.
在PyTorch中,建立网络的一种好方法是创建一个新类。 PyTorch的torch.nn模块使我们可以非常简单地构建上述网络。 这也是非常容易理解的。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()self.conv1 = nn.Conv2d(in_channels=1, out_channels=128,
kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(num_features=128)self.tns1 = nn.Conv2d(in_channels=128, out_channels=4,
kernel_size=1, padding=1)self.conv2 = nn.Conv2d(in_channels=4, out_channels=16,
kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(num_features=16)self.pool1 = nn.MaxPool2d(2, 2)self.conv3 = nn.Conv2d(in_channels=16, out_channels=16,
kernel_size=3, padding=1)
self.bn3 = nn.BatchNorm2d(num_features=16)
self.conv4 = nn.Conv2d(in_channels=16, out_channels=32,
kernel_size=3, padding=1)
self.bn4 = nn.BatchNorm2d(num_features=32)
self.pool2 = nn.MaxPool2d(2, 2)self.tns2 = nn.Conv2d(in_channels=32, out_channels=16,
kernel_size=1, padding=1)
self.conv5 = nn.Conv2d(in_channels=16, out_channels=16,
kernel_size=3, padding=1)
self.bn5 = nn.BatchNorm2d(num_features=16)
self.conv6 = nn.Conv2d(in_channels=16, out_channels=32,
kernel_size=3, padding=1)
self.bn6 = nn.BatchNorm2d(num_features=32)self.conv7 = nn.Conv2d(in_channels=32, out_channels=10,
kernel_size=1, padding=1)
self.gpool = nn.AvgPool2d(kernel_size=7)self.drop = nn.Dropout2d(0.1)def forward(self, x):
x = self.tns1(self.drop(self.bn1(F.relu(self.conv1(x)))))
x = self.drop(self.bn2(F.relu(self.conv2(x))))
x = self.pool1(x)
x = self.drop(self.bn3(F.relu(self.conv3(x))))
x = self.drop(self.bn4(F.relu(self.conv4(x))))
x = self.tns2(self.pool2(x))
x = self.drop(self.bn5(F.relu(self.conv5(x))))
x = self.drop(self.bn6(F.relu(self.conv6(x))))
x = self.conv7(x)
x = self.gpool(x)
x = x.view(-1, 10)
return F.log_softmax(x)We define our own class class Net(nn.Module) and we inherit nn.Module which is Base class for all neural network modules. Then we define initialize function __init__ after we inherit all the functionality of nn.Module in our class super(Net, self).__init__(). After that we start building our model.
我们定义了自己的类class Net(nn.Module)并继承了nn.Module,它是所有神经网络模块的基类。 然后,在继承类super(Net, self).__init__()的nn.Module的所有功能之后,定义初始化函数__init__ 。 之后,我们开始构建模型。
We’ll use 2-D convolutional layers. As activation function we’ll choose rectified linear units (ReLUs in short). We use Max pooling of kernel size 2x2 to reduce channel size into half.
我们将使用二维卷积层。 作为激活函数,我们将选择整流线性单位(简称ReLU)。 我们使用2x2内核大小的最大池将通道大小减小一半。
The forward() pass defines the way we compute our output using the given layers and functions.
forward()传递定义了使用给定层和函数计算输出的方式。
x.view(-1, 10) The view method returns a tensor with the same data as the self tensor (which means that the returned tensor has the same number of elements), but with a different shape. First parameter represent the batch_size in our case batch_size is 128 if you don't know the batch_size pass -1 tensor.view method will take care of batch_size for you. Second parameter is the column or the number of neurons you want. Look at the code below.
x.view(-1, 10) view方法返回一个张量,该张量具有与自张量相同的数据(这意味着返回的张量具有相同数量的元素),但形状不同。 第一个参数表示我们的情况下的batch_size,如果您不知道batch_size传递-1 tensor.view方法将为您处理batch_size,则batch_size为128。 第二个参数是所需的列数或神经元数。 看下面的代码。
步骤4 —检查GPU并总结模型 (Step 4 — Check for GPU and summerize the model)
Summarize the model help us to give better intuition about each layer of model we build.
汇总模型有助于我们更好地直观了解所构建模型的每一层。
from torchsummary import summary Torch-summary provides information complementary to what is provided by print(your_model) in PyTorch. summary(your_model, input_data)
from torchsummary import summary Torch-summary提供的信息与PyTorch中print(your_model)提供的信息互补。 summary(your_model, input_data)
torch.cuda.is_available() check for the GPU return True if GPU available else return False
torch.cuda.is_available()检查GPU返回True(如果GPU可用,否则返回False)
model = Net().to(device) load model to available device
model = Net().to(device)模型加载到可用设备
!pip install torchsummary
from torchsummary import summary
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
model = Net().to(device)
summary(model, input_size=(1, 28, 28))Now run the above code to get detailed view of model.
现在运行上面的代码以获取模型的详细视图。
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 128, 28, 28] 1,280
BatchNorm2d-2 [-1, 128, 28, 28] 256
Dropout2d-3 [-1, 128, 28, 28] 0
Conv2d-4 [-1, 8, 30, 30] 1,032
Conv2d-5 [-1, 16, 30, 30] 1,168
BatchNorm2d-6 [-1, 16, 30, 30] 32
Dropout2d-7 [-1, 16, 30, 30] 0
MaxPool2d-8 [-1, 16, 15, 15] 0
Conv2d-9 [-1, 16, 15, 15] 2,320
BatchNorm2d-10 [-1, 16, 15, 15] 32
Dropout2d-11 [-1, 16, 15, 15] 0
Conv2d-12 [-1, 32, 15, 15] 4,640
BatchNorm2d-13 [-1, 32, 15, 15] 64
Dropout2d-14 [-1, 32, 15, 15] 0
MaxPool2d-15 [-1, 32, 7, 7] 0
Conv2d-16 [-1, 16, 9, 9] 528
Conv2d-17 [-1, 16, 9, 9] 2,320
BatchNorm2d-18 [-1, 16, 9, 9] 32
Dropout2d-19 [-1, 16, 9, 9] 0
Conv2d-20 [-1, 32, 9, 9] 4,640
BatchNorm2d-21 [-1, 32, 9, 9] 64
Dropout2d-22 [-1, 32, 9, 9] 0
Conv2d-23 [-1, 10, 11, 11] 330
AvgPool2d-24 [-1, 10, 1, 1] 0
================================================================
Total params: 18,738
Trainable params: 18,738
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 3.08
Params size (MB): 0.07
Estimated Total Size (MB): 3.15
----------------------------------------------------------------第5步-训练和测试功能 (Step 5— Train and Test function)
As you can see our model have less than 20k parameters. Now let’s define the train and test function and run it to check whether we are able to achieve 99.5% accuracy within 20 epochs.
如您所见,我们的模型的参数少于20k。 现在,让我们定义训练和测试功能并运行它,以检查我们是否能够在20个纪元内达到99.5%的准确度。
from tqdm import tqdmdef train(model, device, train_loader, optimizer, epoch):
model.train()
pbar = tqdm(train_loader)
for batch_idx, (data, target) in enumerate(pbar):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
pbar.set_description(desc= f'epoch: {epoch} loss=
loss.item()} batch_id={batch_idx}')def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target,
reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True)
correct +=pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{}
({:.1f}%)\n'.format(test_loss, correct,
len(test_loader.dataset), 100. * correct /
len(test_loader.dataset)))tqdm which can mean "progress," Instantly make your loops show a smart progress meter — just wrap any iterable with tqdm(iterable), and you’re done!
tqdm可能表示“进度”,立即使您的循环显示一个智能进度表-只需用tqdm(iterable)包装任何可迭代的对象,就完成了!
model.train() By default all the modules are initialized to train mode (self.training = True). Also be aware that some layers have different behavior during train/and evaluation (like Batch Norm, Dropout) so setting it matters. Hence we mention in first line of train function i.e model.train() and in first line of test function i.e model.eval()
model.train()默认情况下,所有模块都初始化为训练模式(self.training = True)。 另请注意,某些层在训练/评估过程中会有不同的行为(例如Batch Norm,Dropout),因此进行设置很重要。 因此,我们在训练函数的第一行即model.train()和测试函数的第一行即model.eval()
zero_grad clears old gradients from the last step (otherwise you’d just accumulate the gradients from all loss.backward()
zero_grad从最后一步清除旧的渐变(否则,您将仅从所有损失中累积渐变。backward()
loss.backward() computes the derivative of the loss w.r.t. the parameters (or anything requiring gradients) using back propagation.
loss.backward()使用反向传播计算参数(或任何需要渐变的参数loss.backward()的损耗导数。
optimizer.step() causes the optimizer to take a step based on the gradients of the parameters.
optimizer.step()使优化器根据参数的梯度采取步骤。
To calculate losses in PyTorch, we will use the F.nll_loss we define the negative log-likelihood loss. It is useful to train a classification problem with C classes. Together the LogSoftmax() and NLLLoss() acts as the cross-entropy loss.
为了计算PyTorch中的损失,我们将使用F.nll_loss定义负对数似然损失。 用C类训练分类问题很有用。 LogSoftmax()和NLLLoss()一起充当交叉熵损失。
第6步-训练模型 (Step 6— Training Model)
This is where the actual learning happens. Your neural network iterates over the training set and updates the weights. We make use of torch.optim which is a module provided by PyTorch to optimize the model, perform gradient descent and update the weights by back-propagation. Thus in each epoch (number of times we iterate over the training set), we will be seeing a gradual decrease in training loss.
这是实际学习的地方。 您的神经网络遍历训练集并更新权重。 我们使用了torch.optim提供的模块torch.optim来优化模型,执行梯度下降并通过反向传播更新权重。 因此,在每个epoch (我们遍历训练集的次数),我们将看到训练损失的逐渐减少。
model = Net().to(device)
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum_value)
for epoch in range(1, epochs):
train(model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)Let’s run the above code and check the training logs.
让我们运行上面的代码并检查训练日志。
epoch: 1 loss=0.27045467495918274 batch_id=468: 100%|██████████| 469/469 [00:22<00:00, 20.58it/s]
0%| | 0/469 [00:00<?, ?it/s]
Test set: Average loss: 0.1221, Accuracy: 9685/10000 (96.8%)
epoch: 2 loss=0.09988906979560852 batch_id=468: 100%|██████████| 469/469 [00:22<00:00, 21.15it/s]
0%| | 0/469 [00:00<?, ?it/s]
Test set: Average loss: 0.0604, Accuracy: 9823/10000 (98.2%)
epoch: 3 loss=0.20125557482242584 batch_id=468: 100%|██████████| 469/469 [00:22<00:00, 20.85it/s]
0%| | 0/469 [00:00<?, ?it/s]
Test set: Average loss: 0.0480, Accuracy: 9843/10000 (98.4%)
epoch: 4 loss=0.0712851956486702 batch_id=468: 100%|██████████| 469/469 [00:22<00:00, 21.22it/s]
0%| | 0/469 [00:00<?, ?it/s]
Test set: Average loss: 0.0371, Accuracy: 9890/10000 (98.9%)
epoch: 5 loss=0.04961127042770386 batch_id=468: 100%|██████████| 469/469 [00:21<00:00, 21.45it/s]
0%| | 0/469 [00:00<?, ?it/s]
Test set: Average loss: 0.0321, Accuracy: 9897/10000 (99.0%)
epoch: 6 loss=0.054023560136556625 batch_id=468: 100%|██████████| 469/469 [00:22<00:00, 21.16it/s]
0%| | 0/469 [00:00<?, ?it/s]
Test set: Average loss: 0.0271, Accuracy: 9913/10000 (99.1%)
epoch: 7 loss=0.07397448271512985 batch_id=468: 100%|██████████| 469/469 [00:22<00:00, 21.32it/s]
0%| | 0/469 [00:00<?, ?it/s]
Test set: Average loss: 0.0273, Accuracy: 9909/10000 (99.1%)
epoch: 8 loss=0.05811620131134987 batch_id=468: 100%|██████████| 469/469 [00:22<00:00, 20.65it/s]
0%| | 0/469 [00:00<?, ?it/s]
Test set: Average loss: 0.0239, Accuracy: 9928/10000 (99.3%)
epoch: 9 loss=0.08609984070062637 batch_id=468: 100%|██████████| 469/469 [00:22<00:00, 20.86it/s]
0%| | 0/469 [00:00<?, ?it/s]
Test set: Average loss: 0.0222, Accuracy: 9930/10000 (99.3%)
epoch: 10 loss=0.10347550362348557 batch_id=468: 100%|██████████| 469/469 [00:22<00:00, 21.04it/s]
0%| | 0/469 [00:00<?, ?it/s]
Test set: Average loss: 0.0234, Accuracy: 9921/10000 (99.2%)
epoch: 11 loss=0.10419472306966782 batch_id=468: 100%|██████████| 469/469 [00:22<00:00, 20.88it/s]
0%| | 0/469 [00:00<?, ?it/s]
Test set: Average loss: 0.0196, Accuracy: 9930/10000 (99.3%)
epoch: 12 loss=0.004044002387672663 batch_id=468: 100%|██████████| 469/469 [00:22<00:00, 20.97it/s]
0%| | 0/469 [00:00<?, ?it/s]
Test set: Average loss: 0.0223, Accuracy: 9930/10000 (99.3%)
epoch: 13 loss=0.05143119767308235 batch_id=468: 100%|██████████| 469/469 [00:22<00:00, 20.56it/s]
0%| | 0/469 [00:00<?, ?it/s]
Test set: Average loss: 0.0201, Accuracy: 9930/10000 (99.3%)
epoch: 14 loss=0.03383662924170494 batch_id=468: 100%|██████████| 469/469 [00:22<00:00, 20.86it/s]
0%| | 0/469 [00:00<?, ?it/s]
Test set: Average loss: 0.0187, Accuracy: 9940/10000 (99.4%)
epoch: 15 loss=0.037076253443956375 batch_id=468: 100%|██████████| 469/469 [00:22<00:00, 20.42it/s]
0%| | 0/469 [00:00<?, ?it/s]
Test set: Average loss: 0.0209, Accuracy: 9935/10000 (99.3%)
epoch: 16 loss=0.009786871261894703 batch_id=468: 100%|██████████| 469/469 [00:22<00:00, 20.50it/s]
0%| | 0/469 [00:00<?, ?it/s]
Test set: Average loss: 0.0190, Accuracy: 9944/10000 (99.4%)
epoch: 17 loss=0.024468591436743736 batch_id=468: 100%|██████████| 469/469 [00:23<00:00, 20.36it/s]
0%| | 0/469 [00:00<?, ?it/s]
Test set: Average loss: 0.0177, Accuracy: 9946/10000 (99.5%)
epoch: 18 loss=0.030203601345419884 batch_id=468: 100%|██████████| 469/469 [00:22<00:00, 20.40it/s]
0%| | 0/469 [00:00<?, ?it/s]
Test set: Average loss: 0.0171, Accuracy: 9937/10000 (99.4%)
epoch: 19 loss=0.04640066251158714 batch_id=468: 100%|██████████| 469/469 [00:22<00:00, 20.72it/s]
Test set: Average loss: 0.0179, Accuracy: 9938/10000 (99.4%)HURRAY! We have over 99.5% accuracy. We don’t need to train the model every time. PyTorch has a functionality that can save our model so that in the future, we can load it and use it directly.
欢呼! 我们的准确率超过99.5%。 我们不需要每次都训练模型。 PyTorch具有可以保存我们的模型的功能,以便将来我们可以加载它并直接使用它。
torch.save(model, 'path/to/save/my_mnist_model.pth')结论 (Conclusion)
In summary we built a new environment with PyTorch and TorchVision, used it to classify handwritten digits from the MNIST dataset and hopefully developed a good intuition using PyTorch. For further information the official PyTorch documentation is really nicely written and the forums are also quite active!
总而言之,我们使用PyTorch和TorchVision构建了一个新环境,用它对MNIST数据集中的手写数字进行分类,并希望使用PyTorch可以开发出良好的直觉。 有关更多信息, PyTorch官方文档编写得非常好, 论坛也非常活跃!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









