



3g和4g的跨越时间
This post is a loving tribute to my daughter, whose eyes are shining stars in these dark and troubled nights.
这篇文章向我的女儿致以深深的敬意,在这片漆黑的夜晚中,她的眼睛闪耀着星星。
Names evolve. Parents would take a name from pop culture, history, sports, current events, or sacred texts and add their own spin to it. The act of naming both evokes the meaning of the original name but also leaves blank pages for the newborn to write.
名字在演变。 父母会从流行文化,历史,体育,时事或神圣文本中取一个名字,并为其添加一个名称。 命名不仅唤起了原始名称的含义,而且还留下了空白页供新生儿书写。
Take Cassandra for example. There are shorter variants such as Cass. Some consonants might be replaced. In some countries, ‘c’ can be replaced with ‘k’, like Kassandra. Interestingly, it is common in the Philippines, for example, to add an ‘h’ to the spelling (Cassandhra). Here’s a quick plot of the variants over time.
以卡桑德拉(Cassandra)为例。 有较短的变体,例如Cass。 一些辅音可能会被替换。 在某些国家/地区,可以将“ c”替换为“ k”,例如Kassandra。 有趣的是,例如在菲律宾很常见,在拼写上加上“ h”(Cassandhra)。 这是随时间变化的快速图表。
Read on to see how I did it! Here’s the Kaggle Notebook, if anyone’s interested.
继续阅读,看看我是如何做到的! 如果有人感兴趣,这是Kaggle笔记本。
识别变体 (Identifying Variants)
With data, we can see a glimpse of how names and their variants move in popularity over time. I used the US Baby Names dataset which is gathered from US Social Security data. I then use the Double Metaphone algorithm to group together words by their English pronunciation. Designed by Lawrence Phillips in 1990, the original Metaphone algorithm does its phonetic matching through complex rules for variations in vowel and consonant sounds. Since then, there have been two updates to the algorithm. Fortunately for us, there is a Python port from C/C++ code, the fuzzy library. The result is a grouping of words like:
通过数据,我们可以看到名称及其变体如何随时间流行。 我使用了从美国社会保障数据收集的美国婴儿名字数据集。 然后,我使用Double Metaphone算法将单词按其英语发音分组。 最初的Metaphone算法是由Lawrence Phillips在1990年设计的,它通过复杂的元音和辅音变化规则进行语音匹配。 从那时起,对该算法进行了两次更新。 对我们来说幸运的是,有一个来自C / C ++代码的Python端口,即模糊库。 结果是像这样的单词分组:
Mark -> MRK
Marc -> MRK
Marck -> MRK
Marco -> MRKIn the following code, we first get the fingerprint (a.k.a. hash code) of all the names in the data:
在下面的代码中,我们首先获取数据中所有名称的指纹(也称为哈希码):
names = df["Name"].unique()
fingerprint_algo = fuzzy.DMetaphone()
list_fingerprint = []
for n in names:
list_fingerprint.append(fingerprint_algo(n)[0])The result is having an index for each of the names. Then with simple filtering, we can extract variants of both Cassandra and Cass.
结果是每个名称都有一个索引。 然后,通过简单的过滤,我们可以提取Cassandra和Cass的变体。
def get_subset(df, df_fp, names):
fingerprint_candidates = []
for name in names:
matches = df_fp[df_fp["name"] == name]["fingerprint"]
fingerprint_candidates.extend(matches.values.tolist())
name_candidates = df_fp.loc[df_fp["fingerprint"].isin(
fingerprint_candidates), "name"]
df_subset = df[(df["Name"].isin(name_candidates)) & (df["Gender"] == "F")]
return df_subset
# using my function
df_fp_names = pd.DataFrame([list_fingerprint, names]).T df_fp_names.columns=["fingerprint", "name"] df_subset = get_subset(df, df_fp_names, ["Cass", "Cassandra"])卡桑德拉的变种 (Variants of Cassandra)
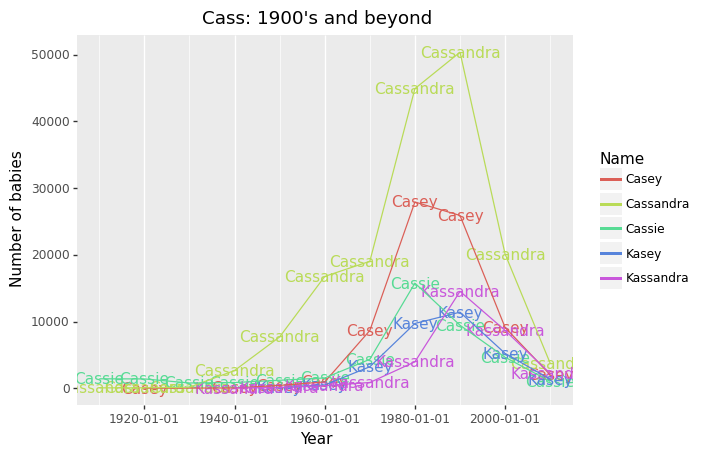
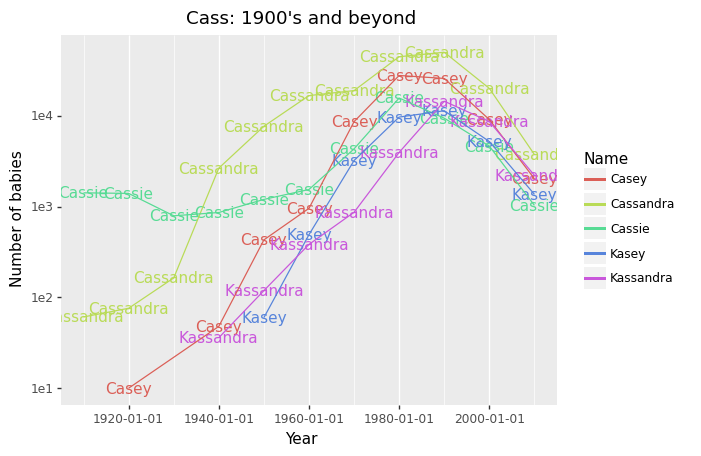
We can then plot the most popular variants of Cassandra throughout the 20th century. I also plot a log scale version so we can see better those in the middle of the pack. I’m using the plotnine library so I can do ggplot-style code.
然后,我们可以绘制整个20世纪最受欢迎的Cassandra变体。 我还绘制了对数刻度版本,以便我们可以更好地看到中间的那些版本。 我正在使用plotnine库,因此可以执行ggplot样式的代码。
ggplot(df_top_n_global,
aes(x = "Year", y = "Count", colour = "Name")) + \
geom_text(aes(label = "Name"), show_legend = False) +\
geom_line() +\
labs(y = 'Number of babies', title = 'Cass: 1900\'s and beyond') +\
scale_y_continuous(trans='log10') +\
theme(panel_grid_minor_y=element_blank(),
panel_grid_major_y=element_blank())It looks like the name Cassandra and nearly all its most popular variants have peaked in the ’90s but has since then decreased sharply. I have read that at one point, the name has even reached the top 70 in the United States in the ’90s. Other popular variants include Casey, Cassie, and Kassandra, all of which have been decreasing in popularity.
看起来像卡桑德拉(Cassandra)这个名字,几乎所有最受欢迎的变种都在90年代达到顶峰,但此后急剧下降。 我读过,这个名字曾经在90年代甚至达到美国前70名。 其他受欢迎的变体包括Casey,Cassie和Kassandra,所有这些变体的受欢迎程度都在下降。
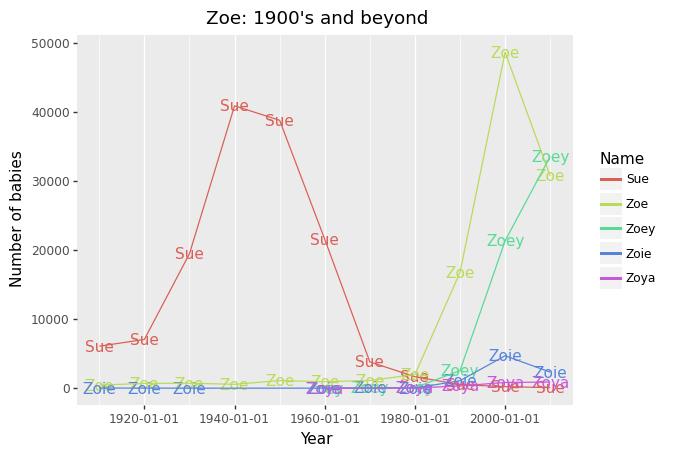
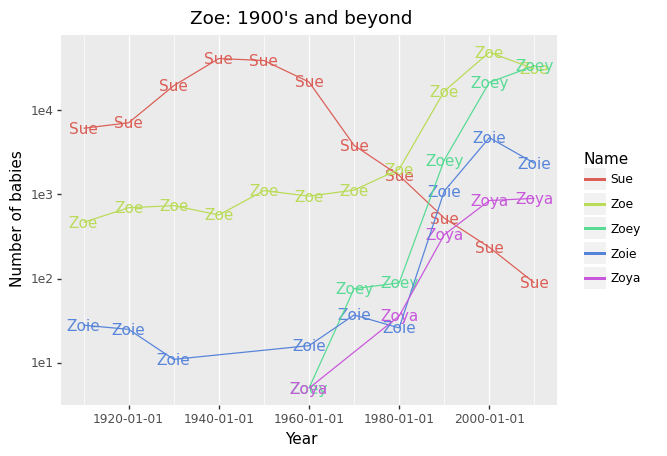
佐伊(Zoe)最受欢迎的变体 (Most Popular Variants of Zoe)
The story is different for Zoe, where we find a very sharp uptick in popularity in the 2000s. Perhaps the show Zoey 101 had to do with it? There is also that classic rom-com, 500 Days of Summer in 2009…
对于佐伊来说,情况就不同了,在2000年代,佐伊的人气急剧上升。 也许Zoey 101的演出与此有关? 还有经典的rom-com,2009年的夏季500天…
An identified variant, Sue, however, has sharply reduced in popularity since the 1950s. I’m quite sure that they have different pronunciations. Double Metaphone has mistakenly indexed them together.
但是,自1950年代以来,已确定的变体Sue的受欢迎程度急剧下降。 我很确定他们有不同的发音。 Double Metaphone错误地将它们索引在一起。
It’s very interesting to study how names evolve, get more popular, and become rarer over time. Famous people and events always have a hand in it so names become a reflection of the times. I remember a trend where parents were naming their children Danaerys or adding a Jon in the name somewhere. I’m guessing that as of the time of this post’s writing, there may be a lot of Anthony’s being born. Even X Æ A- 12 is a sign of the times.
研究名称如何随着时间演变,变得越来越流行以及变得越来越稀有非常有趣。 名人和事件总是有帮助的,因此名称成为时代的反映。 我记得有一种趋势,父母在给他们的孩子命名Danaerys或在某个地方添加一个Jon的名字。 我猜到撰写本文时,可能有很多安东尼出生。 甚至XÆA- 12也代表了时代。
Since I’m only using data from the US, it will be more fascinating to see each country’s trends and variants. What are each country’s naming styles? What does cross-pollination of naming styles look like? Are gender-neutral names becoming more in favor? These are all fascinating questions to explore!
由于我仅使用来自美国的数据,因此看到每个国家的趋势和变化会更令人着迷。 每个国家的命名方式是什么? 命名方式的异花授粉是什么样的? 不分性别的名字越来越受到青睐吗? 这些都是令人着迷的问题!
Originally published at http://itstherealdyl.com on September 19, 2020.
最初于2020年9月19日发布在http://itstherealdyl.com上。
翻译自: https://towardsdatascience.com/a-name-across-time-and-numbers-a9f432c3981b
3g和4g的跨越时间

















 2038
2038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









