



 本文探讨了在uni-app中如何进行数据清理,参考了数据清理的起点,旨在帮助开发者了解并实施缓存数据的管理。
本文探讨了在uni-app中如何进行数据清理,参考了数据清理的起点,旨在帮助开发者了解并实施缓存数据的管理。
uni-app清理缓存数据
It turns out that Data Scientists and Data Analysts will spend most of their time on data preprocessing and EDA rather than training a machine learning model. As one of the most important job, Data Cleansing is very important indeed.
事实证明,数据科学家和数据分析师将把大部分时间花在数据预处理和EDA上,而不是训练机器学习模型。 作为最重要的工作之一,数据清理确实非常重要。
We all know that we need to clean the data. I guess most people know that. But where to start? In this article, I will provide a generic guide/checklist. So, once we start on a new dataset, we can start the Data Cleansing as such.
我们都知道我们需要清理数据。 我想大多数人都知道。 但是从哪里开始呢? 在本文中,我将提供通用指南/清单。 因此,一旦我们开始一个新的数据集,我们就可以像这样开始数据清洗。
方法论(CRAI) (Methodology (C-R-A-I))
If we ask ourselves “why do we need to clean the data?”, I think it is obvious that it is because we want our data to follow some standards in order to be fed into some algorithm or visualised on a consistent scale. Therefore, let’s firstly summarise what are the “standards” that we want our data to have.
如果我们问自己“为什么需要清理数据?”,我认为很明显是因为我们希望我们的数据遵循某些标准,以便输入某种算法或以一致的规模可视化。 因此,让我们首先总结一下我们希望数据具有的“标准”。
Here, I summarised 4 major criteria/standards that a cleansed dataset should have. I would call it “CRAI”.
在这里,我总结了清洗后的数据集应具有的4个主要标准/标准。 我称之为“ CRAI”。
Consistency
一致性
Every column of the data should be consistent on the same scale.
数据的每一列都应在相同范围内保持一致。
Rationality
理性
All the values in each column should comply with common sense.
每列中的所有值均应符合常识。
Atomicity
原子性
The data entries should not be duplicated and the data column should not be dividable.
数据条目不应该重复,并且data列不能分开。
Integrity
廉洁
The data entries should have all the features available unless null value makes sense.
数据条目应具有所有可用功能,除非使用空值有意义。
OK. Just bear in mind with these 4 criteria. I will explain them with more examples so that hopefully they will become something that you can remember.
好。 只要记住这四个标准即可。 我将通过更多示例来说明它们,以便希望它们将成为您可以记住的东西。
一致性 (Consistency)

It will be helpful to plot a histogram of a column regardless it is continuous or categorical. We need to pay attention to the min/max values, average values and the shape of the distribution. Then, use common sense to find out whether there is any potential inconsistency.
无论列是连续的还是分类的,绘制柱状图都是有帮助的。 我们需要注意最小值/最大值,平均值和分布形状。 然后,使用常识找出是否存在任何潜在的不一致之处。
For example, if we sampled some people and one column of the data is for their weights. Let’s say the histogram is as follows.
例如,如果我们对一些人进行了抽样,则数据的一列是他们的体重。 假设直方图如下。
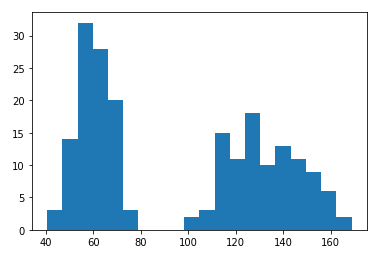
It is obvious that there is almost nothing between 80 and 100. Using our common sense is quite enough to find out the problem. That is, some of the weights are in kg while the others are in lbs.
显然,在80到100之间几乎没有任何东西。使用我们的常识就足以找出问题所在。 也就是说,一些重量以千克为单位,而另一些重量以磅为单位。
This kind of issue is commonly found when we have multiple data sources. Some of them might use different units for the same data fields.
当我们有多个数据源时,通常会发现这种问题。 他们中的一些人可能对相同的数据字段使用不同的单位。
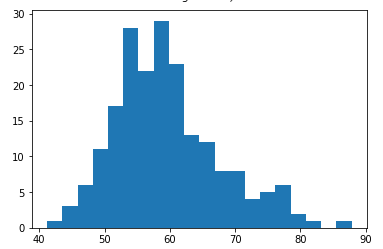
After cleansing, we may end up with distribution like this, which looks good.
清洗后,我们可能最终会得到这样的分布,看起来不错。
理性 (Rationality)

This also relies on our common sense, but it is usually easier to be found. Some common example:
这也依赖于我们的常识,但通常更容易找到。 一些常见的例子:
- Human age, weight and height should not be negative. 人的年龄,体重和身高不应为负数。
- Some categorical data such as gender will have a certain enumeration of values. otherwise, it is not valid. 一些分类数据(例如性别)将具有一定的值枚举。 否则无效。
- Most types of textual values such as human names and product names should not have leading and tailing spaces. 大多数类型的文本值(例如,人名和产品名)都不应使用前导和尾部空格。
- Sometimes we may also need to pay attention to special characters. Most of the time they should be stripped out. 有时我们可能还需要注意特殊字符。 在大多数情况下,应将其剥离。
原子性 (Atomicity)
This is easy to understand. We should not have any duplicated rows in our dataset. It happens commonly when we have multiple data sources, where different data source may store overlapped data.
这很容易理解。 我们的数据集中不应有任何重复的行。 当我们有多个数据源时,通常会发生这种情况,其中不同的数据源可能会存储重叠的数据。
It is important to leave uniqueness checking later than the consistency and rationality because it will difficult to find out the duplicated rows if we didn’t fix the consistency and rationality issues. For example, a person’s name might be presented in different ways in different data sources, such as González and Gonzalez. Once we realise that there are some non-English names existing, we need to pay attention to this kind of problems.
在一致性和合理性之后保留唯一性检查很重要,因为如果我们不解决一致性和合理性问题,将很难找出重复的行。 例如,可以在不同的数据源(例如González和Gonzalez以不同的方式显示一个人的名字。 一旦意识到存在一些非英语名称,就需要注意这种问题。
Therefore, although it is usually not difficult to get rid of duplicated rows, the other of doing it may impact the final quality of the cleansed data.
因此,尽管通常不难摆脱重复的行,但另一步可能会影响已清理数据的最终质量。
Another type of violation of the atomicity is that one column may be dividable, which means that there are actually multiple features hidden in one column. To maximise the value of the dataset, we should divide them.
违反原子性的另一种类型是,一列可能是可分割的,这意味着实际上一列中隐藏了多个特征。 为了最大化数据集的价值,我们应该将它们分开。
For example, we may have a column that represents customer names. Sometimes it might necessary to split it into first name and last name.
例如,我们可能有一个代表客户名称的列。 有时可能需要将其拆分为名字和姓氏。
廉洁 (Integrity)

Depending on the data source and how the data structure was designed, we may have some data missing in our raw dataset. This data missing sometimes doesn’t mean we lose some data entries, but we may lose some values for certain columns.
根据数据源以及数据结构的设计方式,原始数据集中可能会缺少一些数据。 有时丢失这些数据并不意味着我们会丢失一些数据条目,但是对于某些列,我们可能会丢失一些值。
When this happened, it is important to identify whether the “null” or “NaN” values make sense in the dataset. If it doesn’t, we may need to get rid of the row.
发生这种情况时,重要的是要确定数据集中“ null”或“ NaN”值是否有意义。 如果没有,我们可能需要摆脱该行。
However, eliminating the rows having missing values is not always the best idea. Sometimes we may use average values or other technique to fill the gaps. This is depending on the actual case.
但是,消除具有缺失值的行并不总是最好的主意。 有时我们可能会使用平均值或其他技术来填补空白。 这取决于实际情况。
CRAI方法论的使用 (Usage of CRAI Methodology)

Well, I hope the above examples explained what is “CRAI” respectively. Now, let’s take a real example to practice!
好吧,我希望以上示例分别解释什么是“ CRAI”。 现在,让我们以一个真实的例子进行练习!
Suppose we have an address column in our dataset, what should we do to make sure it is cleaned?
假设我们的数据集中有一个address列,应该怎么做才能确保它被清除?
C —一致性 (C — Consistency)
- The address might contain street suffixes, such as “Street” and “St”, “Avenue” and “Ave”, “Crescent” and “Cres”. Check whether we have both terms in those pairs. 该地址可能包含街道后缀,例如“街道”和“ St”,“大道”和“ Ave”,“新月”和“克雷斯”。 检查在这些对中是否同时存在这两个术语。
- Similarly, if we have state names in the address, we may need to make sure they are consistent, such as “VIC” and “Victoria”. 同样,如果地址中有州名,则可能需要确保它们是一致的,例如“ VIC”和“ Victoria”。
- Check the unit number presentation of the address. “Unit 9, 24 Abc St” should be the same as “9/24 Abc St”. 检查地址的单位编号显示。 “ 9号街24号Abc St”应与“ 9/24 Abc St”相同。
R-理性 (R — Rationality)
- One example would be that the postcode must follow a certain format in a country. For example, it must be 4 digits in Australia. 一个示例是邮政编码必须在某个国家/地区遵循某种格式。 例如,在澳大利亚必须为4位数字。
- If there is a country in the address string, we may need to pay attention to that. For example, the dataset is about all customers in an international company that runs its business in several countries. If an irrelevant country appears, we might need to further investigate. 如果地址字符串中有一个国家,我们可能需要注意。 例如,数据集涉及在多个国家/地区经营业务的一家国际公司中的所有客户。 如果出现无关的国家,我们可能需要进一步调查。
A —原子性 (A — Atomicity)
- The most obvious atomicity issue is that we should split the address into several fields such as the street address, suburb, state and postcode. 最明显的原子性问题是我们应该将地址分成几个字段,例如街道地址,郊区,州和邮政编码。
- If our dataset is about households, such as a health insurance policy. It might be worth to pay more attention to those duplicated addresses of different data entries. 如果我们的数据集是关于家庭的,例如健康保险单。 可能需要更多注意不同数据条目的那些重复地址。
我-诚信 (I — Integrity)
- This is about the entire data entry (row-wise) in the dataset. Of course, we need to drop the duplicated rows. 这是关于数据集中的整个数据条目(按行)。 当然,我们需要删除重复的行。
- Check whether there are any data entries that have their address missing. Depending on the business rules and data analysis objectives, we may need to eliminate the rows that miss addresses. Also, addresses should not be able to be derived usually, so we should not need to fill gaps because we cannot. 检查是否有任何数据条目的地址丢失。 根据业务规则和数据分析目标,我们可能需要消除丢失地址的行。 同样,地址通常不能被导出,因此我们不需要填补空白,因为我们不能。
- If in the Atomicity checking, we found that some rows having exactly the same addresses and based on the business rules this can be determined as duplicated, we may need to combine or eliminate them. 如果在原子性检查中发现某些地址具有完全相同的行,并且根据业务规则可以将其确定为重复行,则可能需要合并或消除它们。
摘要 (Summary)

Here is the “CRAI” methodology I usually follow myself when I first time gets along with a new dataset.
这是我初次接触新数据集时通常会遵循的“ CRAI”方法。
It turns out that this method is kind of generic, which means that it should be applicable in almost all the scenarios. However, it is also because of its universal, we should pay more attention to the domain knowledge that will influence how you apply CRAI to clean your datasets.
事实证明,这种方法是通用的,这意味着它应该适用于几乎所有场景。 但是,也是由于它的通用性,我们应该更加注意将影响您如何应用CRAI清理数据集的领域知识。
That’s all I want to share in this article. Hope it helps :)
这就是我要在本文中分享的全部内容。 希望能帮助到你 :)
翻译自: https://towardsdatascience.com/data-cleansing-where-to-start-90802e95cc5d
uni-app清理缓存数据

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









