





kafka 源码环境构建
Sending messages between components, reliably and quickly, is a core requirement for most distributed systems. Apache Kafka is a popular choice as it enables that — it offers low latency, high throughput and fault tolerance. This blog describes key configuration settings and testing approaches that enable you to build reliable applications with Kafka.
在组件之间可靠且快速地发送消息是大多数分布式系统的核心要求。 Apache Kafka是一个受欢迎的选择,因为它可以实现这一点-它提供了低延迟,高吞吐量和容错能力。 该博客介绍了关键的配置设置和测试方法,使您能够使用Kafka构建可靠的应用程序。
卡夫卡建筑的组成部分 (Components of Kafka Architecture)
The architecture, at a high level consists of Producers that produce messages to a Kafka cluster and consumers that consume these messages. A cluster has more than one broker and each broker contains certain topic partitions. Zookeeper is responsible for managing the brokers.
该架构在较高层次上由向Kafka集群产生消息的生产者和使用这些消息的使用者组成。 一个集群有多个代理,每个代理都包含某些主题分区。 Zookeeper负责管理经纪人。
经纪人,主题和分区 (Brokers, Topics and Partitions)
A topic in Kafka is broken up into partitions that sit on brokers. In order to ensure fault tolerant behavior, partitions are copied to different brokers. Kafka allocates partitions so they are evenly distributed among brokers and each partition is housed on a different broker. Partitions are allocated this way, so if a broker goes down, another broker has a copy of the partition and the cluster can operate normally.
卡夫卡(Kafka)中的一个主题分为多个经纪人分区。 为了确保容错行为,将分区复制到不同的代理。 Kafka分配分区,以便它们在代理之间平均分配,并且每个分区都位于不同的代理上。 通过这种方式分配分区,因此,如果代理发生故障,则另一个代理将拥有该分区的副本,并且群集可以正常运行。
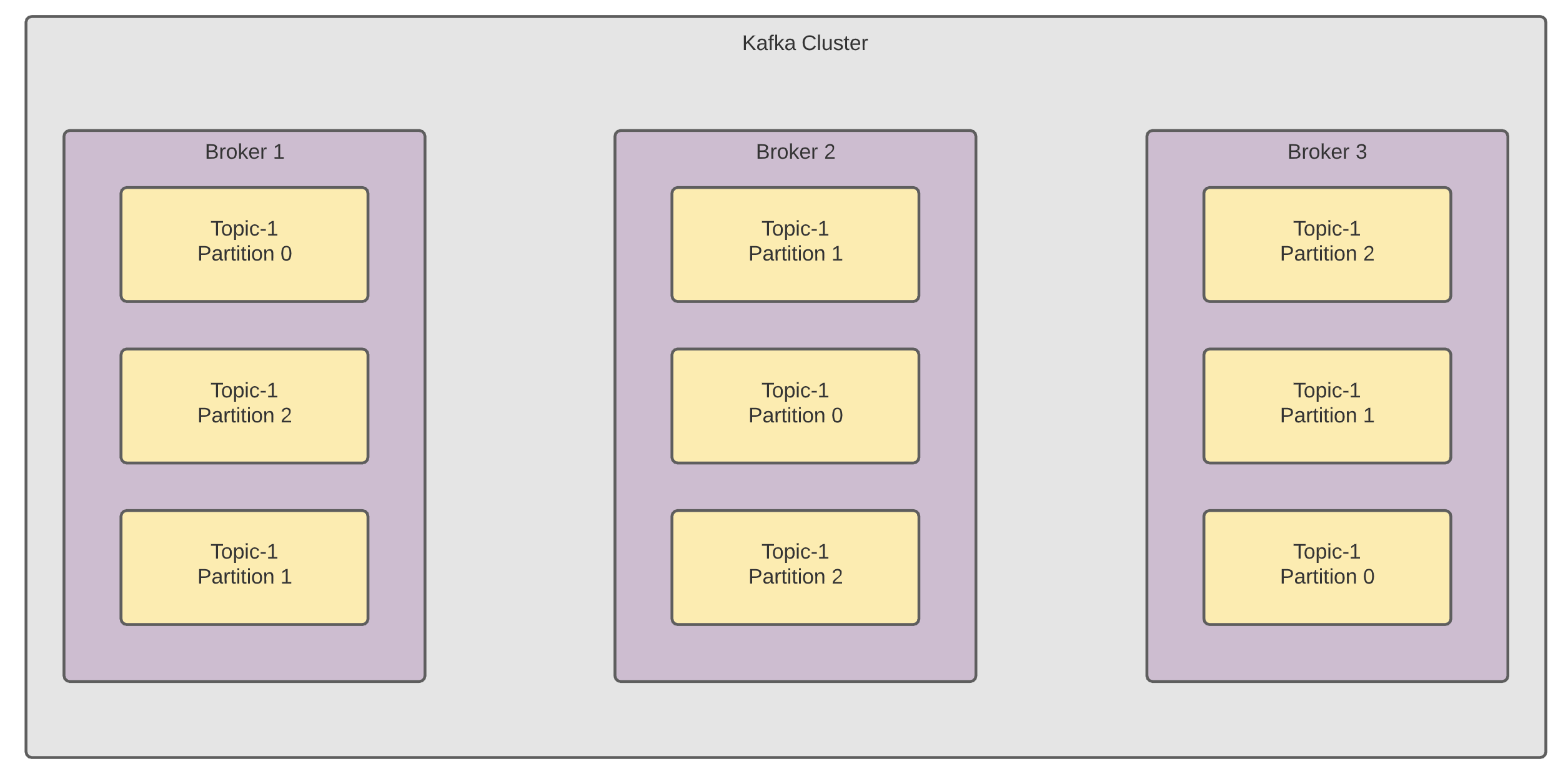
The diagram below shows the organization of Topics and Partitions in a 3 broker cluster with 3 partitions. A partition can either be a Leader or a Follower. The total number of replicas including the leader constitute a replication factor. In the diagram below, since each partition is copied twice, the replication factor is 3.
下图显示了在具有3个分区的3个代理群集中的主题和分区的组织。 分区可以是领导者或跟随者。 包括前导在内的副本总数构成一个复制因子。 在下图中,由于每个分区都被复制了两次,因此复制因子为3。
In the upcoming sections we will look at key configurations for the producer and consumer that help build reliable applications and approaches to enable ‘Exactly Once Processing’ within Kafka.
在接下来的部分中,我们将介绍针对生产者和消费者的关键配置,这些关键配置将帮助构建可靠的应用程序和方法,以在Kafka中启用“完全一次处理”。
生产者设置 (Producer settings)
When writing a producer, there are a few settings that one needs to be mindful of, to ensure data integrity and throughput.
编写生产者时,需要注意一些设置,以确保数据完整性和吞吐量。
min.insync.replicas: In the example from above, if min.insync.replicas is set to 2 it means the Leader and one follower should have gotten the data before the producer gets an acknowledgment for data it produced.
min.insync.replicas :在上面的示例中,如果将min.insync.replicas设置为2,则意味着Leader和一个关注者应该在生产者获得对其产生的数据的确认之前已经获取了数据。
acks: A producer can produce messages with this setting set to 0, 1 or all. Here is what these settings mean:
acks :生产者可以生成此设置为0、1或全部的消息。 这些设置的含义如下:
- acks = 0: The producer does not request a response, so as soon as it is able to produce a message, it assumes the broker got it and moves on. Use this setting only when its ok to lose data. acks = 0:生产者不请求响应,因此一旦能够产生消息,就假定经纪人得到了消息并继续前进。 仅在可以丢失数据的情况下才使用此设置。
- acks = 1: This is the default setting. The producer gets as acknowledgment as soon as the leader gets the message. There is potential to lose information because if the leader acknowledges receipt and immediately goes down before the follower got the message, the message is lost. acks = 1:这是默认设置。 领导者收到消息后,生产者就会得到认可。 信息丢失的可能性很大,因为如果领导者确认收货并在追随者收到消息之前立即掉线,则消息将丢失。
- acks = all: Use this setting when you cannot lose any messages. A producer will get an acknowledgment for a published record only when the leader and followers (totaling up to the min.insync.replicas) have received the data. This setting adds a bit of latency, but guarantees no message loss. acks =全部:当您不会丢失任何消息时,请使用此设置。 仅当领导者和关注者(总计min.insync.replicas)收到数据时,生产者才会获得对已发布记录的确认。 此设置会增加一些延迟,但不会丢失任何消息。
enable.idempotence: This setting ensures that a producer does not produce duplicate messages to Kafka and messages are delivered in order within a partition. Setting this property to true in turn sets additional properties like acks, in flight requests and retries. It is a best practice to enable this setting to ensure a stable and safe pipeline.
enable.idempotence :此设置确保生产者不会向Kafka产生重复消息,并且消息将在分区内按顺序传递。 将此属性设置为true会依次设置其他属性,例如ack , 飞行请求和重试 。 最佳实践是启用此设置以确保稳定和安全的管道。
compression.type: The Kafka producer batches data when it sends it to the broker. Enabling message compression makes the batch much smaller (up to 4 times), thus reducing network bandwidth for data transfer and making replication within Kafka quicker. This also leads to better disk utilization in Kafka as messages are stored in compressed format.
compression.type :Kafka生产者将数据发送到代理时会对其进行批处理。 启用消息压缩可使批处理变得更小(最多4倍),从而减少用于数据传输的网络带宽,并使Kafka内的复制更快。 由于消息以压缩格式存储,因此这也可以提高Kafka中的磁盘利用率。
linger.ms: Number of milliseconds a producer will wait before sending the batch (default 0). By setting this to a small value like 10 milliseconds, we can increase throughput and compression.
linger.ms :生产者在发送批次之前将等待的毫秒数(默认为0)。 通过将其设置为一个较小的值(例如10毫秒),我们可以提高吞吐量和压缩率。
batch.size: One can control the size of the producer batch with this setting. The default is 16kb, but can be increased to a larger value like 32kb to increase compression and throughput.
batch.size :可以使用此设置控制生产者批次的大小。 默认值为16kb,但可以增加到更大的值,例如32kb,以提高压缩率和吞吐量。
消费者设置 (Consumer settings)
When writing a Kafka consumer one must be mindful of Kafka’s delivery semantics and commit strategies for messages.
编写Kafka使用者时,必须注意Kafka的传递语义和消息提交策略。
交付语义: (Delivery Semantics:)
There are 3 modes in which Kafka delivers messages:
Kafka传递消息的方式有3种:
At most once: A consumer commits the offset for a batch of records as soon as it is received. This can lead to loss of messages if the consumer goes down before processing the batch.
最多一次 :使用者在收到一批记录时就提交偏移量。 如果使用者在处理该批次之前掉线,则可能导致消息丢失。
At least once: This is the default setting in Kafka. A consumer commits the offsets after processing the batch. In this mode, although one doesn’t lose messages, there is a possibility of getting the same message more than once.
至少一次 :这是Kafka中的默认设置。 消费者在处理批次后提交偏移量。 在这种模式下,尽管不会丢失消息,但有可能多次获得同一条消息。
Exactly once: Kafka delivers the message exactly once to the consumer. This is only possible within the Kafka ecosystem. So, if one is reading from a Kafka topic and writing to other topics in Kafka, this mode can be enabled. If an external system like a database or JMS is involved, exactly once processing is not guaranteed unless you code for it.
恰好一次 : Kafka仅一次将消息传递给消费者。 这仅在卡夫卡生态系统中是可能的。 因此,如果正在阅读Kafka主题并在Kafka中写入其他主题,则可以启用此模式。 如果涉及数据库或JMS之类的外部系统,则除非您进行编码,否则不能保证只进行一次处理。
偏移提交策略: (Offset commit strategies:)
A Kafka consumer, by default, has enable.auto.commit set to true. What this means is that the consumer reads a batch of records and acknowledges the batch every 5 seconds. This is a risky setting because if a record fails within the batch, it is lost. In order to build a reliable consumer set the auto commit property to false and manually commit offsets. This gives you the opportunity to retry failed messages a few times and audit them (moving them to a dead letter queue).
默认情况下,Kafka使用者将enable.auto.commit设置为true。 这意味着用户将读取一批记录并每5秒确认一次。 这是一个有风险的设置,因为如果记录在批处理中失败,它将丢失。 为了构建可靠的使用者,请将auto commit属性设置为false并手动提交偏移量。 这使您有机会重试失败的消息几次并对其进行审核(将它们移动到死信队列中)。
重置偏移量: (Resetting Offsets:)
Offsets in Kafka (>= 2.0) are stored for 7 days by default. This gives the consumer the option to reset the offset to the earliest or latest using the auto.offset.reset policy. Another option to set the offset for a consumer group is to use the Kafka command line. Follow the steps below to set the offset to a particular offset value:
默认情况下,卡夫卡(> = 2.0)中的偏移量存储7天。 这使使用者可以选择使用auto.offset.reset策略将偏移量重置为最早或最新。 为使用者组设置偏移量的另一种方法是使用Kafka命令行。 请按照以下步骤将偏移量设置为特定的偏移值:
- Bring down the consumer group 降低消费群体
Use kafka-consumer-groups command to set the offset to a particular value
使用kafka-consumer-groups命令将偏移量设置为特定值
- Bring the consumer group up 培养消费者群体
交易次数 (Transactions)
In the above section we looked at some important settings for the producer and consumer with which we can build reliable applications. In this section we will look into the support for transactions in Kafka.
在上一节中,我们研究了生产者和消费者的一些重要设置,通过这些设置我们可以构建可靠的应用程序。 在本节中,我们将研究对Kafka中事务的支持。
为什么我们需要交易? (Why do we need Transactions?)
Transactions are needed for any mission critical application that perform a “read-process-write” processing cycle and need “exactly-once” processing semantics. Transactions in Kafka build on the durability settings described earlier around acknowledgments, producer idempotence and consumer offset commit strategies.
任何执行“读取-处理-写入”处理周期并且需要“完全一次”处理语义的关键任务应用程序都需要事务。 Kafka中的事务建立在前面关于确认,生产者幂等和消费者抵消提交策略所描述的持久性设置上。
事务语义 (Transactional semantics)
原子多分区写入 (Atomic multi-partition writes)
Transactions guarantee that a read from a topic and a write to multiple topics works in an “all or nothing” manner. If an error occurs, it rolls back the read and write across topics.
事务保证对主题的读取和对多个主题的写入以“全部或全部”的方式工作。 如果发生错误,它将回滚跨主题的读写。
僵尸击剑 (Zombie Fencing)
Exactly once processing is complex. Even with Transactions enabled, it is possible to process the same message twice when multiple workers are reading from a topic. In a nutshell, if a worker reads a message, processes it and updates the offset but hasn’t committed it and either goes down or hangs, the Kafka consumer group coordinator assigns the partition to another worker. Since the transaction wasn’t committed, the second worker gets the same message, processes it and commits the transaction. If the first worker now wakes up and commits the transaction, this would result in a duplicate message. Zombie fencing as explained in this article, accounts for this issue.
恰好一次处理很复杂。 即使启用了事务处理,当多个工作人员正在从一个主题中读取消息时,也可能两次处理同一条消息。 简而言之,如果一个工作程序读取了一条消息,对其进行了处理并更新了偏移量,但尚未提交该消息,但该消息已关闭或挂起,则Kafka用户组协调员会将分区分配给另一个工作程序。 由于未提交事务,因此第二个工作人员会收到相同的消息,对其进行处理并提交事务。 如果第一个工作人员现在醒来并提交事务,则将导致重复消息。 在解释僵尸击剑这个文章,占了这个问题。
消费交易消息 (Consuming Transacted messages)
The default setting when consuming messages is read_uncommitted which means that the consumer would read aborted and un committed messages. When using transactions, set the isolation.level property to read_committed so the consumer only reads committed messages.
使用邮件时的默认设置为read_uncommitted ,这意味着 消费者将读取已中止和未提交的消息。 使用事务时,请将isolation.level属性设置为read_committed,以便使用者仅读取已提交的消息。
实施交易 (Implementing Transactions)
There are two main options to implement transactions in Kafka applications:
在Kafka应用程序中实现事务有两个主要选项:
- Using Producer and Consumer API: This approach involves using the Kafka client library or a wrapper library that’s built on top of it and setting the configurations described above for producers and consumers and enabling transactions. While this is certainly doable, there is a simpler approach for the “read-process-write” style processing (also known a Stream processing) in a Kafka to Kafka workload. This is accomplished by using Kafka Streams. The use of producer and consumer APIs is most suited when one needs to process messages between Kafka and an external system like a database or JMS. 使用Producer和Consumer API:此方法涉及使用Kafka客户端库或在其之上构建的包装器库,并为生产者和消费者设置上述配置并启用交易。 尽管这当然是可行的,但在Kafka到Kafka的工作负载中,有一种更简单的方法用于“读取-处理-写入”样式的处理(也称为Stream处理)。 这是通过使用Kafka Streams完成的。 当需要在Kafka和数据库或JMS等外部系统之间处理消息时,最适合使用生产者和消费者API。
Kafka Streams: This option is ideal for Kafka to Kafka workloads. By setting a single property, processing.guarentee to exactly_once one can get “Exactly Once” semantics without any code changes. This article describes how Kafka streams handles exactly once processing and how to enable it in your application.
Kafka Streams:此选项是从Kafka到Kafka的工作负载的理想选择。 通过设置一个属性,将processing.guarentee设置为精确地一次即可获得“ 精确一次”的语义,而无需更改任何代码。 该文章描述了如何卡夫卡流控恰好一次处理以及如何使其能够在您的应用程序。
测试Kafka应用程序 (Testing Kafka applications)
The Confluent platform includes client libraries for many languages like Java, C++, .NET, Go and Python. This blog assumes you are using Java for developing your application. Here is a sample application written using Spring-Kafka along with unit and integration tests.
Confluent平台包括用于多种语言的客户端库 ,例如Java,C ++ 、. NET,Go和Python。 该博客假定您正在使用Java开发应用程序。 这是使用Spring-Kafka编写的示例应用程序,以及单元和集成测试。
- Unit tests: At the bottom of the testing pyramid lie unit tests, that test the smallest unit of code (a method). External dependencies are mocked using a library like Mockito. If you follow TDD, you should end up with a lot of unit tests that run quickly. 单元测试:测试金字塔的底部是单元测试,该单元测试用于测试最小的代码单元(一种方法)。 使用Mockito之类的库可以模拟外部依赖关系。 如果遵循TDD,则应该以快速运行的大量单元测试结束。
Integration tests: These tests involve creating topics on Kafka and confirming that our code can read and write from our topics. Spring-Kafka provides embedded Kafka that is an implementation of Kafka running in memory that can be spun up and torn down after your tests. If your code involves an external system like JMS, use Test Containers to spin up MQ in a docker container and run your test against it. The sample project above has an example of such a test.
集成测试:这些测试涉及在Kafka上创建主题,并确认我们的代码可以从我们的主题中读写。 Spring-Kafka提供了嵌入式Kafka,它是在内存中运行的Kafka的实现,可以在测试后旋转和拆除。 如果您的代码涉及JMS之类的外部系统,请使用“ 测试容器”在docker容器中启动MQ并对其进行测试。 上面的示例项目中有一个这样的测试示例。
Chaos testing: Chaos testing involves injecting failure in the underlying infrastructure and examining the effects of it on your application. It helps in achieving resilience against network failures, infrastructure failures or application failures. Gremlin is a popular tool that one can use for chaos engineering.
混乱测试:混乱测试涉及将故障注入基础架构中并检查其对应用程序的影响。 它有助于实现抵御网络故障,基础架构故障或应用程序故障的弹性。 Gremlin是一种可以用于混沌工程的流行工具。
摘要 (Summary)
In this article, we looked at the Kafka architecture at a high level and approaches one can take in building reliable applications. I hope you find this blog useful as you build applications that run against Kafka.
在本文中,我们从高层次研究了Kafka架构,并介绍了构建可靠应用程序时可以采用的方法。 我希望这个博客对构建针对Kafka的应用程序有用。
翻译自: https://medium.com/kinandcartacreated/building-reliable-applications-with-kafka-283c3563d34e
kafka 源码环境构建


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









