





损失函数作用
Loss function describes how efficient the model performs with respect to the expected outcome. Here, the main objective is to minimize the number of misclassifications. The choice of the loss function is critical in defining the outputs in a way that is sensitive to the application at hand. There are various types of lost or cost functions.
损失函数描述了模型相对于预期结果的执行效率。 在此,主要目的是最大程度地减少错误分类的次数。 损耗函数的选择对于以对当前应用程序敏感的方式定义输出至关重要。 有各种类型的损失或成本函数。
L1损失 (L1 Loss)
L1 loss function is also known as least absolute deviations (LAD). It is the sum of all the absolute differences between the target value and the predicted values.
L1损失函数也称为最小绝对偏差(LAD)。 它是目标值和预测值之间所有绝对差的总和。
L2损失 (L2 Loss)
L2 loss function is also known as least squares error (LSE). It is basically minimizing the sum of square of the differences between the target value and the predicted values.
L2损失函数也称为最小二乘误差(LSE)。 基本上是将目标值和预测值之间的差的平方和最小化。
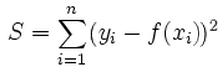
The disadvantage of the L2 loss function is that it considers the outliers as well, which increases the value of the loss function.
L2损失函数的缺点是它也会考虑离群值,这会增加损失函数的值。
胡贝尔损失 (Huber Loss)
Huber loss function is used in robust regression and is less sensitive to outliers. It utilizes both L1 and L2 loss.
Huber损失函数用于稳健回归中,并且对异常值不敏感。 它同时利用了L1和L2损耗。
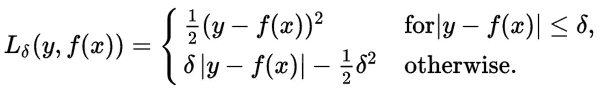
Where, 𝛿 is a set parameter, 𝑦 represents the target value and 𝑓(𝑥) represents the predicted value.
其中,𝛿是设定参数,𝑦表示目标值,𝑓(𝑓)表示预测值。
铰链损失 (Hinge Loss)
The hinge loss is used for “maximum-margin” classification. For an intended output t = ±1 and a classifier score y, the hinge loss of the prediction y is defined as,
铰链损耗用于“最大边距”分类。 对于预期的输出t =±1和分类器得分y,预测y的铰链损耗定义为:
平方铰链损耗 (Squared Hinge Loss)
Squared Hinge Loss is a popular extension of hinge loss function that simply calculates the square of the score hinge loss. It has the effect of smoothing the surface of the error function and making it numerically easier to work with.
平方铰链损耗是铰链损耗函数的一种流行扩展,它可以简单地计算分数铰链损耗的平方。 它具有使误差函数的表面变平滑并使它在数值上更易于使用的效果。
可能性损失 (Likelihood Loss)
The likelihood function is also relatively simple, and is commonly used in classification problems. The function takes the predicted probability for each input example and multiplies them. he model outputs probabilities for TRUE (or 1) only, when the ground truth label is 0 we take (1-p) as the probability.
似然函数也相对简单,通常用于分类问题。 该函数获取每个输入示例的预测概率并将其相乘。 该模型仅输出TRUE(或1)的概率,当地面真实标签为0时,我们将(1-p)作为概率。
交叉熵损失 (Cross-entropy loss)
Cross-entropy loss or log loss measures the performance of a classification model whose output is a probability value between 0 and 1. Cross-entropy loss increases as the predicted probability diverges from the actual label.
交叉熵损失或对数损失衡量的是分类模型的性能,该模型的输出是介于0和1之间的概率值。随着预测概率与实际标签的偏离,交叉熵损失会增加。
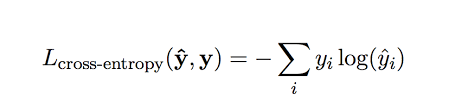
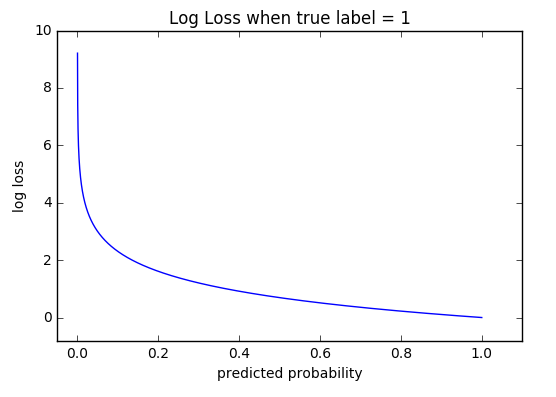
The graph above shows the range of possible loss values given a true observation. As the predicted probability approaches 1, log loss slowly decreases. As the predicted probability decreases, however, the log loss increases rapidly.
上图显示了给出真实观察值时可能出现的损耗值的范围。 随着预测概率接近1,对数损失逐渐减少。 但是,随着预测概率的降低,对数损失会Swift增加。
sigmod交叉熵损失 (Sigmoid-Cross-entropy loss)
Sigmoid Cross-Entropy loss is a Sigmoid activation plus a Cross-Entropy loss. Generally, we calculate 𝑠𝑐𝑜𝑟𝑒𝑠 = 𝑥∗𝑤 + 𝑏, pass this value into the sigmoid function that compresses the value to range (0,1).
Sigmoid交叉熵损失是Sigmoid激活加交叉熵损失。 通常,我们计算𝑠𝑐𝑜𝑟𝑒𝑠=𝑥∗𝑤+𝑏,然后将此值传递到S型函数中,该函数会将值压缩到范围(0,1)。
Softmax交叉熵损失 (Softmax cross-entropy loss)
Softmax Loss is a Softmax activation plus a Cross-Entropy loss. It uses softmax function to convert the score vector into a probability vector and is used for multi-class classification.
Softmax损失是Softmax激活加上交叉熵损失。 它使用softmax函数将得分向量转换为概率向量,并用于多类分类。
Kullback Leibler发散损失 (Kullback Leibler Divergence Loss)
Kullback Leibler Divergence, or KL Divergence for short, is a measure of how one probability distribution differs from a baseline distribution. A KL divergence loss of 0 suggests the distributions are identical. The behavior of KL Divergence is very similar to cross-entropy. It calculates how much information is lost if the predicted probability distribution is used to approximate the desired target probability distribution.
Kullback Leibler散度(简称KL散度)是一种概率分布与基线分布的差异的度量。 KL散度损失为0表明分布是相同的。 KL发散的行为与交叉熵非常相似。 如果使用预测的概率分布来近似所需的目标概率分布,它将计算丢失了多少信息。
致谢 (Acknowledgement)
Sincere gratitude to Mr. Sudhanshu Kumar, CEO & Chief AI Engineer, iNeuron for imparting continuous encouragement and generous guidance.
衷心感谢iNeuron首席执行官兼首席AI工程师Sudhanshu Kumar先生不断给予鼓励和慷慨的指导。
翻译自: https://medium.com/analytics-vidhya/loss-functions-d1c65c24c2ea
损失函数作用


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









