





变分自动编码器
An autoencoder is one of the many different special neural network designs, the main objective of an autoencoder is to learn how to return the same data used to train it. The basic structure of an autoencoder can be split into two different networks, an encoder, and a decoder. The encoder compresses the data into a low dimensions space, while the decoder reconstructs the training data. In the middle of those two networks lays a bottleneck representation of the data. The bottleneck representation or latent space representation can be helpful for data compression, non-linear dimensionality reduction, or feature extraction. In a traditional autoencoder, the latent space could take any form as there is no constrain controlling the distribution of the latent variables in the latent space. A variational autoencoder rather than learn a single attribute in the latent space, learn a probability distribution for each latent attribute. The following post shows a simple method to optimize the architecture of a variational autoencoder using different performance measurements.
自动编码器是许多不同的特殊神经网络设计之一,自动编码器的主要目标是学习如何返回用于训练的相同数据。 自动编码器的基本结构可以分为两个不同的网络,一个编码器和一个解码器。 编码器将数据压缩到低维空间,而解码器重建训练数据。 在这两个网络中间,构成了数据的瓶颈表示。 瓶颈表示或潜在空间表示可有助于数据压缩,非线性降维或特征提取。 在传统的自动编码器中,潜在空间可以采用任何形式,因为不存在控制潜在空间中潜在变量分布的约束。 可变自动编码器而不是学习潜在空间中的单个属性,而是学习每个潜在属性的概率分布。 以下文章显示了一种使用不同的性能指标来优化变分自动编码器体系结构的简单方法。
思维时尚 (Thinking fashion)
A classic data set used in machine learning is the MNIST dataset, that dataset is composed of a variety of images of handwritten numbers from zero to nine. With the rise in popularity of the MNIST dataset similar datasets have been created. One of those is the Fashion MNIST dataset, it consists of images of several clothing items, divided into ten different categories. Each image is a simple 28X28 grayscale image.
机器学习中使用的经典数据集是MNIST数据集,该数据集由从零到九的各种手写数字图像组成。 随着MNIST数据集的普及,已经创建了类似的数据集。 其中之一是Fashion MNIST数据集,它由几种服装的图像组成,分为十个不同类别。 每个图像都是简单的28X28灰度图像。

Before the definition of the variational autoencoder, we need to define the different custom layers needed to train the variational autoencoder. In Keras, a custom layer can be created by defining a new class that inherits the characteristics of a Layer class from Keras. For this particular autoencoder, two customs layers are going to be needed a sampling layer and a wrapper layer. The Sampling layer will take as input the layer before the bottleneck representation and will be used to constrain the values that the latent space can take. By sampling a normal distribution the variational autoencoder will learn a latent representation that is normally distributed. That characteristic can be useful to create new data that does not exist in the training data, that can be done with the decoder by using a sample from the same distribution as an input. For that characteristic variational autoencoders are also classified as generative models.
在定义可变自动编码器之前,我们需要定义训练可变自动编码器所需的不同自定义层。 在Keras中,可以通过定义一个新类来创建自定义图层,该类继承了Keras中Layer类的特征。 对于此特定的自动编码器,将需要两个海关层:一个采样层和一个包装层。 采样层将以瓶颈表示之前的层作为输入,并将用于约束潜在空间可以采用的值。 通过采样正态分布,变分自编码器将学习正态分布的潜在表示。 该特性对于创建训练数据中不存在的新数据很有用,可以通过使用来自相同分布的样本作为输入,由解码器完成。 为此,变分自动编码器也被归类为生成模型。
class Sampling(Layer):
'''
Custom Layer for sampling the latent space
'''
def call(self,inputs):
Mu,LogSigma=inputs
batch=tf.shape(Mu)[0]
dim=tf.shape(Mu)[1]
epsilon=K.random_normal(shape=(batch,dim))
return Mu+(K.exp(0.5*LogSigma))*epsilonWith the sampling layer defined the wrapper layer is defined similarly. However, the objective of this layer is to add a custom term to the model loss. A variational autoencoder loss is composed of two main terms. The first one the reconstruction loss, which calculates the similarity between the input and the output. And the distribution loss, that term constrains the latent learned distribution to be similar to a Gaussian distribution. The second loss term is added to a layer before the bottleneck representation and it adds the Kullback Leiber divergence as a dissimilarity between the learned distribution and the Gaussian distribution.
通过定义采样层,可以类似地定义包装层。 但是,该层的目的是向模型损失添加自定义项。 可变自动编码器损耗由两个主要术语组成。 第一个是重建损失,它计算输入和输出之间的相似度。 分配损失将潜在的学习分布限制为类似于高斯分布。 第二个损失项被添加到瓶颈表示之前的层中,并添加了Kullback Leiber发散作为学习到的分布和高斯分布之间的差异。
class KLDivergenceLayer(Layer):
'''
Custom layer to add the divergence loss to the final model
'''
def _init_(self,*args,**kwargs):
self.is_placeholder=True
super(KLDivergenceLayer,self)._init_(*args,**kwargs)
def call(self,inputs):
Mu,LogSigma=inputs
klbatch=-0.5*K.sum(1+LogSigma-K.square(Mu)-K.exp(LogSigma),axis=-1)
self.add_loss(K.mean(klbatch),inputs=inputs)
return inputs创建自动编码器(Creating the autoencoder)
As all the custom layers are already defined the autoencoder can be created. In an autoencoder, the number of densely connected layers or convolutional blocks gradually down-sample the shape of the data into the latent space size (encoder) and then gradually return it to the original data size (decoder). If the same units are for the encoder and the decoder, then both networks are the mirror images of each other. We can use that characteristic to use the same function to create the encoder and the decoder, just by simply reversing the order of the elements of each layer. Then, adding the custom layers to the encoder.
由于所有自定义层均已定义,因此可以创建自动编码器。 在自动编码器中,紧密连接的层或卷积块的数量将数据的形状逐渐下采样为潜在空间大小(编码器),然后逐渐将其恢复为原始数据大小(解码器)。 如果编码器和解码器使用相同的单元,则两个网络都是彼此的镜像。 我们只需简单地反转每一层元素的顺序,就可以使用该特性来使用相同的功能来创建编码器和解码器。 然后,将自定义图层添加到编码器。
def MakeCoder(InputShape,Units,Latent,UpSampling=False):
'''
Parameters
----------
InputShape : tuple
Data shape.
Units : list
List with the number of dense units per layer.
Latent : int
Size of the latent space.
UpSampling : bool, optional
Controls the behaviour of the function, False returns the encoder while True returns the decoder.
The default is False.
Returns
-------
InputFunction : Keras Model input function
Input Used to create the coder.
localCoder : Keras Model Object
Keras model.
'''
if UpSampling:
denseUnits=Units[::-1]
Name="Decoder"
else:
denseUnits=Units
Name="Encoder"
InputFunction=Input(shape=InputShape)
nUnits=len(denseUnits)
X=Dense(denseUnits[0])(InputFunction)
X=Activation('relu')(X)
for k in range(1,nUnits-1):
X=Dense(denseUnits[k])(X)
X=Activation('relu')(X)
X=Dense(denseUnits[nUnits-1])(X)
if UpSampling:
Output=Activation('sigmoid')(X)
localCoder=Model(inputs=InputFunction,outputs=Output,name=Name)
else:
X=Activation('relu')(X)
Mu=Dense(Latent)(X)
LogSigma=Dense(Latent)(X)
Mu,LogSigma=KLDivergenceLayer()([Mu,LogSigma])
Output=Sampling()([Mu,LogSigma])
localCoder=Model(inputs=InputFunction,outputs=[Mu,LogSigma,Output],name=Name)
return InputFunction,localCoderVariational Autoencoder performance can be measured in a variety of forms, the simplest one could be to use the model loss as a measure of autoencoder performance. When a neural network is trained the stochastic gradient descent algorithm is used to minimize the loss function and to calculate the layer weights and biases.
可变的自动编码器性能可以通过多种形式来衡量,最简单的一种方法是使用模型损失来衡量自动编码器性能。 当训练神经网络时,使用随机梯度下降算法来最小化损失函数并计算层权重和偏差。
def LossPerformance(XData,YData,Index):
'''
Parameters
----------
XData : array
Xdata.
YData : array
YData.
Index : list
List of integer values. Number of dense units per layer
Returns
-------
float
loss of the model.
'''
localEncoder,localDecoder,localVAE=MakeVariationalAutoencoder((784,),Index,2)
localVAE.compile(optimizer=Adam(),loss=AutoencoderLoss)
localVAE.fit(XData,YData,batch_size=128,epochs=25)
return localVAE.evaluate(XData,YData)However, using the model loss minimization only shows us how the model learns the data but it doesn’t tell us how useful the latent representation could be. As the variational autoencoder can be used for dimensionality reduction, and the number of different item classes is known another performance measurement can be the cluster quality generated by the latent space obtained by the trained network. We can apply k means clustering to the latent space and calculate the silhouette coefficient of the clusters and use it as a performance measurement of the network.
但是,使用模型损失最小化仅向我们展示了模型如何学习数据,但没有告诉我们潜在表示可能有多有用。 由于可变自动编码器可用于降维,并且已知不同项目类别的数量,因此另一个性能度量可以是由受过训练的网络获得的潜在空间生成的群集质量。 我们可以将k均值聚类到潜在空间并计算聚类的轮廓系数,并将其用作网络的性能度量。
def ClusterPerformance(XData,YData,Index):
'''
Parameters
----------
XData : array
Xdata.
YData : array
YData.
Index : list
List of integer values. Number of dense units per layer
Returns
-------
performance : float
silhouette coeficient obtained by appling kmeans clustering to the latent recostruction.
'''
localEncoder,localDecoder,localVAE=MakeVariationalAutoencoder((784,),Index,2)
localVAE.compile(optimizer=Adam(),loss=AutoencoderLoss)
localVAE.fit(XData,YData,batch_size=256,epochs=30)
_,_,Latent=localEncoder.predict(XData)
Clusters=KMeans(n_clusters=10,random_state=globalSeed)
ClusterLabels=Clusters.fit_predict(Latent)
performance=silhouette_score(Latent,ClusterLabels)
return performanceWith the different performance measurements defined we can start to optimize the architecture of the variational autoencoder. First, a random set of possible architectures is created, each architecture follows the unique constrain that the first layer has the same size as the input, which will ensure that the decoder will have the same output shape as the input data. Then each architecture will be modified following one simple rule if the number of layers in the current architecture is greater than 4 one random layer will be removed, if that is not the case each layer will be added k units, where k is the location of the layer. For example, the first layer will have zero units added as the location of the first layer is zero.
通过定义不同的性能度量,我们可以开始优化可变自动编码器的体系结构。 首先,创建一组可能的架构,每个架构遵循唯一的约束条件,即第一层具有与输入相同的大小,这将确保解码器具有与输入数据相同的输出形状。 然后,如果当前体系结构中的层数大于4,则将按照一个简单的规则修改每个体系结构,如果一个随机层将被删除,则不是这样;如果不是,则将为每个层添加k个单位,其中k是位置。层。 例如,第一层将添加零单位,因为第一层的位置为零。
def MakeIndexEvolution(IndexPopulation,mutProb=0.25):
"""
Parameters
----------
IndexPopulation : list
contains the index for feature generation.
mutProb : float (0,1)
probability of mutation.
Returns
-------
currentIndexs : list
contains the modified indexs.
"""
currentIndexs=copy.deepcopy(IndexPopulation)
nIndexs=len(IndexPopulation)
for k in range(nIndexs):
if np.random.random()>mutProb:
if len(currentIndexs[k])>4:
randomPosition=np.random.randint(1,len(currentIndexs[k]))
del currentIndexs[k][randomPosition]
else:
currentIndexs[k]=list(currentIndexs[k]+np.arange(0,len(currentIndexs[k])))
return currentIndexsOn each round of performance optimization, each individual in the architecture population will be updated if the performance is better than the previous performance.
在每轮性能优化中,如果性能好于先前的性能,则将更新体系结构总体中的每个个体。
def TrainOnGenerations(XData,YData,Performance,Generations,PopulationSize,minimize=False):
"""
Parameters
----------
XData : array
X data.
YData : array
Y data.
Performance : function
Function that calculates the performance of the model
Generations : int
Number of iterations.
PopulationSize : int
number of individuals per iteration.
minimize : bool
Algorithm behaviour, minimization or maximization of the objetive function.
The default is false
Returns
-------
fitness : list
performance of each individual in the population.
currentPopulation : list
contains the index of the las population in the iteration.
"""
currentPopulation=MakeArchitectureLibrary(PopulationSize)
fitness=TrainOnPopulation(XData,YData,currentPopulation,Performance)
for k in range(Generations):
newPopulation=MakeIndexEvolution(currentPopulation)
newFitness=TrainOnPopulation(XData,YData,newPopulation,Performance)
for k in range(PopulationSize):
if minimize:
if newFitness[k]<fitness[k]:
currentPopulation[k]=newPopulation[k]
fitness[k]=newFitness[k]
else:
if newFitness[k]>fitness[k]:
currentPopulation[k]=newPopulation[k]
fitness[k]=newFitness[k]
return fitness,currentPopulationUnder the loss based performance measurement, all the trained models obtained a similar loss value, however, some variational autoencoders with fewer layers show a similar performance as those with a higher number of layers.
在基于损耗的性能测量下,所有训练的模型都获得了相似的损耗值,但是,某些具有较少层的变型自动编码器与具有较高层数的变型自动编码器具有相似的性能。
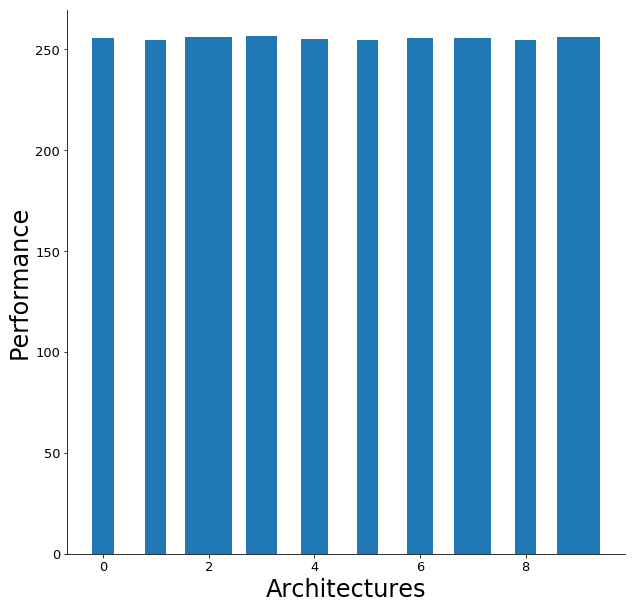
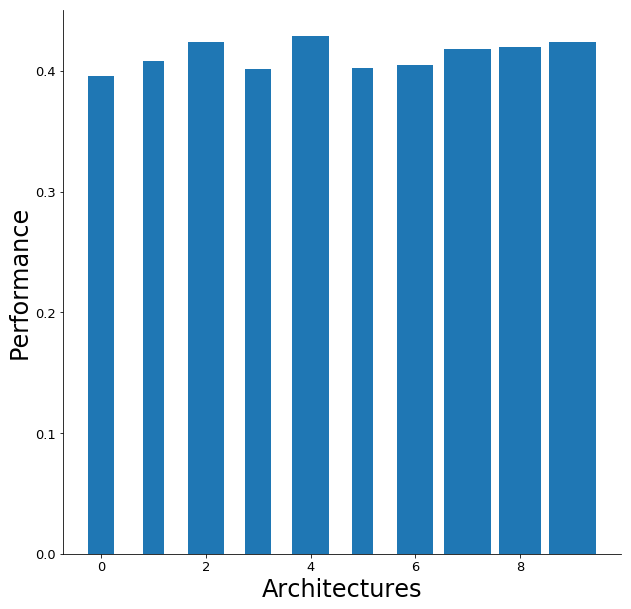
While the cluster-based performance shows a little more variation between the results. Although variational autoencoders with a high number of layers and a low number of layers show high performance, the best performing variational autoencoder happens to be in the middle regarding the number of layers.
虽然基于群集的性能在结果之间显示出更多差异。 尽管具有高层数和低层数的变体自动编码器显示出高性能,但是就层数而言,性能最佳的变体自动编码器恰好位于中间。
Know you have an example on how to define and use custom layers in Keras, how to add custom losses to a neural network, and how to merge everything using the functional API from Keras. Also how to develop a basic evolutionary algorithm using different performance measurements or different optimization objectives. The complete code for this post can be found in my GitHub by clicking here and the complete dataset y clicking here. See you in the next one.
知道您有一个示例,说明如何在Keras中定义和使用自定义层,如何向神经网络添加自定义损耗以及如何使用Keras的功能API合并所有内容。 还有如何使用不同的性能度量或不同的优化目标来开发基本的进化算法。 可以在我的GitHub上找到此文章的完整代码,方法是单击此处,完整数据集y单击此处。 下一个见。
变分自动编码器


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









