





网络优化初学者难吗
Reinforcement Learning: A technique based on rewards & punishments
强化学习:一种基于奖惩的技术
Unlike supervised & unsupervised machine learning algorithms, reinforcement learning models run in an interactive environment, without having a need to train on historic data to make predictions in real time. This technique enables an agent to learn through feedback of its own action & experiences.
与有监督和无监督的机器学习算法不同,强化学习模型在交互式环境中运行,而无需训练历史数据即可进行实时预测。 该技术使代理能够通过反馈自己的行为和经验来学习。
It is used to solve interacting problems where the data is observed up to the latest iteration which is then considered to decide an action to be taken in future
它用于解决交互问题,在这些交互问题中,可以观察到最新迭代之前的数据,然后将其视为决定将来要采取的措施
它对网络广告系列分析有何帮助?(How can in it help in web campaign analytics?)
Campaigns are short term marketing efforts that are scoped towards driving traffic, engagement, conversions or revenue for the brand and/or its products. Some of the use cases where reinforcement learning can help include optimized campaign teasers for specific target audiences to improve the overall click through rate, selecting the best content for campaigns.
广告活动是短期的营销活动,其范围旨在提高品牌和/或其产品的流量,参与度,转化或收入。 强化学习可以帮助使用的一些用例包括针对特定目标受众的优化广告系列预告片,以提高整体点击率,为广告系列选择最佳内容。
问题陈述 (Problem Statement)
For this problem, a brand in the hospitality domain wants to start a campaign aimed towards its new subscription plan that is going to be launched soon. They plan to run teasers for this upcoming campaign for the customers visiting their website.
针对此问题,酒店领域的品牌希望针对其即将推出的新订阅计划发起一场运动。 他们计划为即将到来的广告系列吸引访问其网站的客户。
The creative team has designed five different versions of this teaser and now the business has to make an informed decision on which among these work the best towards orchestrating a journey towards conversion initiation (Teaser which has the highest click through rate).
创意团队设计了此预告片的五个不同版本,现在,企业必须做出明智的决定,以决定其中哪个最能有效地安排转化转化的过程(点击率最高的Teaser)。
资料集 (Data set)
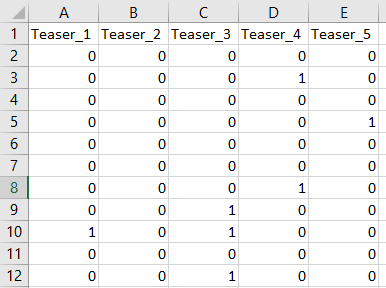
The data set has visitor level information wherein a ‘1’ or ‘0’ is recorded based on if the visitor clicks on the teaser or not.
该数据集具有访问者级别信息,其中基于访问者是否点击预告片来记录“ 1”或“ 0”。
使用的建模技术(Modelling technique used)
In this project, we will focus on the two most commonly used algorithms — Upper Confidence Bound(UCB) & Thompson Sampling.
在本项目中,我们将重点介绍两种最常用的算法-高可信度边界(UCB)和汤普森采样。
Upper Confidence Bound -This is a deterministic algorithm. At start it is assumed that all the 5 options produce similar results. Now as the algorithm iterates through each row (user)it checks if the teaser was interacted with and accordingly the teaser is rewarded, meaning it has a better confidence. As an example if a user interacts with ‘Teaser_3’ there is a high chance of it generating a click the next time it is shown and vice versa. This way we make the intuition based on maximum reward approach.
最高可信度界限-这是一种确定性算法。 开始时,假定所有5个选项产生相似的结果。 现在,随着算法遍历每一行(用户),它会检查预告片是否与之交互,并因此获得奖励,这意味着它具有更好的置信度。 例如,如果用户与“ Teaser_3”进行交互,则很有可能在下次显示该点击时产生点击,反之亦然。 这样,我们基于最大奖励方法进行直觉化。
Thompson Sampling- This is a probabilistic algorithm. In this approach, we try to guess the reward distribution(click through’s in our case) and then try to maximize the total reward. At the start, a random distribution for each teaser is assumed. Post this we check if the ad was rewarding or not based on the actual data and accordingly the total rewards and distribution for each teaser is adjusted. As we move across large sets of iterations the total rewards starts to converge to the expected return of the teasers.
汤普森抽样-这是一种概率算法。 在这种方法中,我们尝试猜测奖励分配(在我们的案例中为“点击”),然后尝试使总奖励最大化。 首先,假设每个预告片都是随机分布的。 发布后,我们会根据实际数据检查广告是否有奖励,并相应调整每个预告片的总奖励和分配。 当我们进行大量迭代时,总奖励开始收敛到预告片的预期回报。
结果 (Results)
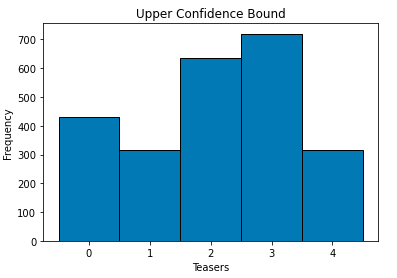
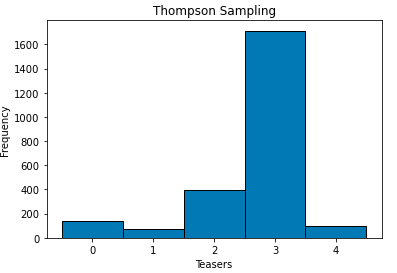
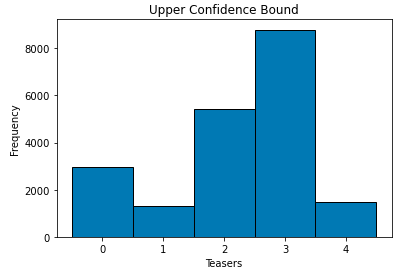
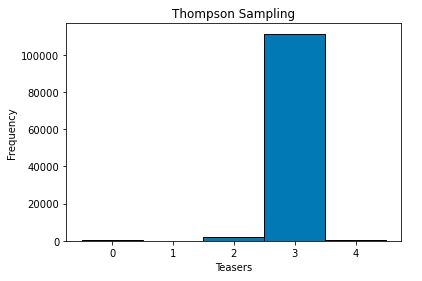
Thompson sampling tends to provide a better view of the final choice of Teaser at much smaller number of iterations.
汤普森采样倾向于以更少的迭代次数更好地了解Teaser的最终选择。
为什么比A / B测试工具更喜欢这种技术? (Why prefer such techniques over A/B testing tools?)
The cost of procuring an A/B testing tool can be much higher as compared to utilizing such methods with existing computational power.
与使用具有现有计算能力的方法相比,购买A / B测试工具的成本可能要高得多。
为什么更喜欢汤普森采样而不是UCB算法? (Why prefer Thompson sampling over UCB algorithm?)
Thompson sampling provides better empirical evidence among the two. Moreover, UCB requires an update after every round while Thompson sampling can accommodate delayed feedback. Considering it from the website teasers and digital ads standpoint Thompson sampling has an additional advantage of computational efficiency over the other.
汤普森抽样在两者之间提供了更好的经验证据。 此外,UCB需要在每轮之后进行更新,而汤普森采样可以容纳延迟的反馈。 从网站宣传和数字广告的角度考虑,Thompson采样比其他方法具有计算效率更高的优势。
码 (Code)
网络优化初学者难吗


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









