





 本文介绍了机器学习管理平台,它旨在提供一个集中的解决方案,用于管理和优化整个机器学习工作流程,包括数据准备、模型训练、部署和监控。通过这样的平台,可以提高AI项目的效率和可重复性。
本文介绍了机器学习管理平台,它旨在提供一个集中的解决方案,用于管理和优化整个机器学习工作流程,包括数据准备、模型训练、部署和监控。通过这样的平台,可以提高AI项目的效率和可重复性。
机器学习管理平台
This story will answer most of the questions that come to your mind while thinking of how to build a platform that can help you deploy your AI model overproduction or what all we need to look into a platform for the same.
这个故事将回答您想到的大多数问题,同时思考如何构建可以帮助您过度部署AI模型的平台,或者我们需要为平台寻找的一切。

Before we go into the details of the specific components of the above architecture and talk about the engineering side, let’s learn a bit about the training process.
在详细介绍上述架构的特定组件并讨论工程方面之前,让我们学习一些培训过程。

So, the model training process is majorly offline. The model training is mainly performed by Data Scientists and Statisticians. These people jot down the requirements, collect data via running various SQL queries over the databases, then comes the data cleaning and feature selection process. After the data is prepared they train a model that is suitable for the particular use case or business requirement, do the validation and testing. And finally, you have the model, to be deployed in production. The model is provided to the developers in various formats depending on the libraries/language used to train the model, say in form of a pickle file or PMML file or any other format.
因此,模型训练过程主要是离线的。 模型训练主要由数据科学家和统计学家进行。 这些人记下了需求,通过在数据库上运行各种SQL查询来收集数据,然后进行数据清理和功能选择过程。 在准备好数据之后,他们会训练适合特定用例或业务需求的模型,进行验证和测试。 最后,您有了要在生产中部署的模型。 根据用于训练模型的库/语言,以各种格式将模型提供给开发人员,例如以pickle文件或PMML文件或任何其他格式的形式。
Now as an engineer its out responsibility to come up with a platform on which we can deploy these trained models and in most of the cases run them in real-time, collect the input and output that goes in and comes out of the model and in some cases provided the feedback, retrain the model.
现在,作为工程师,它有责任提出一个平台,我们可以在该平台上部署这些训练有素的模型,并且在大多数情况下,它们可以实时运行,收集输入和输出来自模型和模型的输入和输出。一些案例提供了反馈,重新训练了模型。
Now as promised let’s deep dive into the engineering side after we have the trained model with us.
现在,正如我们所承诺的,在我们拥有训练有素的模型之后,让我们深入研究工程方面。

The above shows is a brief overview of how the whole platform looks like. In majorly every Machine Learning System we will see these four components.
上图显示了整个平台的简要概述。 在几乎每个机器学习系统中,我们都会看到这四个组成部分。
Client
客户
Pre-Processor Service
预处理服务
Compute/Deployment Service
计算/部署服务
Post-Processor Service
后处理器服务
Before we go in-depth of each of the components and the role they play. There is another important process named The Feedback Loop or Online Model Retraining this is also a somewhat important part of the platform that you may or may not have, it depends.
在深入探讨每个组件及其所扮演的角色之前。 还有一个重要的过程称为“反馈循环”或“在线模型再培训”,这也是您可能拥有或可能没有的平台中某个重要部分,具体取决于。
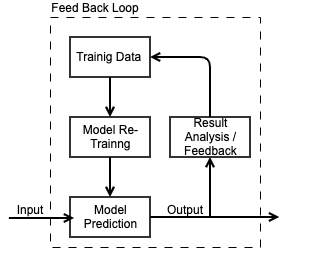
FeedBack loop / Online training process with time helps to fine-tune the model so that it can perform well even over those scenarios where our model was not able to generate the correct results in the past. By adding this component we make our model evolve.
带有时间的反馈循环/在线培训过程有助于微调模型,使其即使在过去我们的模型无法生成正确结果的情况下也能正常运行。 通过添加此组件,我们使模型得以发展。
Q. Why do we have this, if we have a model with say 99% accuracy?
问:如果我们的模型的准确度达到99%,为什么会有这个?
A. The accuracy of the model is over the past data that we already have. And our model learns the pattern out of that data. But when it comes to going live in production the data on which we need to make the prediction/inference can vary a lot form the data on which it was trained/tested/validated. So we adopt this feedback loop or online training mechanism.
答:模型的准确性超过了我们已经拥有的过去数据。 我们的模型从该数据中学习模式。 但是,当要投入生产时,我们需要进行预测/推断的数据可能会与经过训练/测试/验证的数据相差很大。 因此,我们采用这种反馈循环或在线培训机制。
Q. How it works?
问:如何运作?
A. Suppose we deploy version-1 of our model and we used to store all the results the model produced and the input provided to it. We collect all this data and by the end of the month/some time frame provide this to our analyst for the manual analysis. After the analysis, they find out that over certain kinds of input the model is not giving correct output and in the end, they come up with more training data that will help to correct the model. Then they upload this data and our service consume this data and retrain the model with it. The retraining works in the background while version-1 is still running. Once the retraining is done we update the version-1 with the version-2 and it comes live then.
答:假设我们部署了模型的版本1,并且我们曾经存储了模型产生的所有结果以及提供给模型的输入。 我们会收集所有这些数据,并在月底/某个时间范围内将其提供给我们的分析师进行手动分析。 经过分析,他们发现在某些输入下,模型无法提供正确的输出,最后,他们提出了更多的训练数据,这些数据将有助于纠正模型。 然后他们上传这些数据,我们的服务将使用这些数据并使用它重新训练模型。 当版本1仍在运行时,重新培训在后台进行。 重新培训完成后,我们将版本1更新为版本2,然后该版本将上线。
Finally, let’s dig into all the four components mentioned above
最后,让我们深入研究上述所有四个组成部分
Part-1: Client
第一部分:客户

The client can be any service that calls out the platform with the input parameters that are used to generate the input features which are feed to the model to get the output. Apart from the input the client also provides us with its information and the model/model Id that it wants us to run. And apart from the parameters the client supply to us in real-time, it can also demand us to get some input from other data sources at our end. Say if the model, client is using require user history, so for the client to fetch the user history in real-time is a time-consuming process. So here the client will require us to store the history of the user at our end. The same can be done with other data that can’t be served in real-time and possible to store, say the data that don’t change often/ static data and is required by the model for results computation. All the work including the conversion of input param by the client into input param/features feeds to the model is the responsibility of Pre-Processor Service.
客户端可以是任何使用输入参数调用平台的服务,这些输入参数用于生成输入要素,这些要素将馈入模型以获取输出。 除了输入之外,客户端还向我们提供其信息以及希望我们运行的模型/模型ID。 除了客户实时提供给我们的参数外,它还可以要求我们从其他数据源获得一些输入。 假设模型是否正确,客户端正在使用需要用户历史记录,因此对于客户端而言,实时获取用户历史记录是一个耗时的过程。 因此,在这里客户将要求我们在最后存储用户的历史记录。 对于不能实时提供并且无法存储的其他数据也可以做到这一点,例如,那些不经常更改的数据/静态数据,以及模型用于结果计算的数据。 所有工作,包括客户将输入参数转换为模型的输入参数/功能,均由Pre-Processor Service负责。
Part-2: Pre-Processor Service
第2部分:预处理器服务
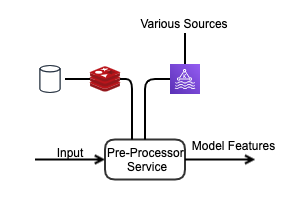
We have the connectivity of the pre-processor service with a cache, databases and it can subscribe to multiple topics of the Kafka. Kafka will have multiple producers and it will provide us data in real-time we can also insert analytics data into the stream as per the model requirements. The client can also upload the data in the database or say in S3 which later can be stored in a cache say Redis but this data will be mostly static for instance the user history as mentioned in Part-1. And In the end, all the logic required to convert the raw input and data into the input that is required by the model will reside in this service only. For instance, if we need to normalize some parameters or scale etc.
我们具有预处理器服务与缓存,数据库的连接,并且可以预订Kafka的多个主题。 Kafka将有多个生产者,它将实时向我们提供数据,我们还可以根据模型要求将分析数据插入流中。 客户端还可以将数据上传到数据库中,或者说在S3中稍后再存储在缓存中,例如Redis,但是该数据将大部分是静态的,例如,第1部分中提到的用户历史记录。 最后,将原始输入和数据转换为模型所需的输入所需的所有逻辑仅驻留在此服务中。 例如,如果我们需要规范化某些参数或比例等。
Note: We will discuss this in more detail in the next upcoming blog on Data Lake Design. Stay tuned!
注意:我们将在下一个即将发表的有关Data Lake Design的博客中对此进行更详细的讨论。 敬请关注!
Part-3: Compute Service
第三部分:计算服务

The whole-brain of the platform resides in this component and its most crucial component. This handles loading the model into the memory over the initiation, selecting the model-based of the request, running the model to get the results, storing the results with the input parameters, sending this for offline analysis in case manual efforts is required or performing the analysis online, getting the data for retraining the model after analysis, running the feedback loop; fine-tuning the model, updating the previous model with the fine-tuned one and again bringing that to work.
平台的整个大脑都位于该组件及其最关键的组件中。 这将处理在启动时将模型加载到内存中,选择基于模型的请求,运行模型以获取结果,将结果与输入参数一起存储,将其发送以供离线分析的情况(如果需要手动操作)或执行在线分析,获取数据以供分析后重新训练模型,运行反馈循环; 对模型进行微调,并使用经过微调的模型更新先前的模型,然后再次将其投入使用。
If we have our model trained using python we need to have support for python and all the libraries that we required to run the model. In case we have deep learning or complex model we might need servers with more power or say with GPUs. It all depends on what kind of model you want to deploy and what all support they need, how much latency you can handle, and what throughput you want. So since this part is important, do take in mind what kind of model you will have in the future, how many requests you will be serving, what delay you can expect, will the model will all be python based or we need to have support for other languages and libraries too so that your system scale well in the longer run.
如果我们使用python训练了模型,则需要对python和运行模型所需的所有库的支持。 如果我们有深度学习或复杂的模型,则可能需要功能更强大或具有GPU的服务器。 这完全取决于您要部署的模型类型,所需的所有支持,可以处理的延迟时间以及所需的吞吐量。 因此,由于这部分很重要,因此请记住您将来将拥有哪种模型,将要服务多少请求,可以预期的延迟时间,该模型将全部基于python还是我们需要获得支持也适用于其他语言和库,因此从长远来看,您的系统可以很好地扩展。
An example regarding the offline analysis process is mentioned while we were explaining the feedback loop.
在解释反馈循环时,提到了有关脱机分析过程的示例。
Now one of the sample online training is; say we run a test over the in which the model decides to recommend a product X to a particular customer or not. So let’s take 3 customers to say P, Q, and R
现在,示例在线培训之一是: 说我们对模型进行测试,模型决定是否向特定客户推荐产品X。 因此,让3个客户说P,Q和R
The Model decided to recommend product X to; P and Q but not to R.
该模型决定将产品X推荐给; P和Q,但不包括R。
And in the end what happened was:
最后发生的是:
- Product X was recommended to P and he purchased that 将产品X推荐给P,他购买了
- Product X was recommended to Q but he didn’t purchase it将产品X推荐给Q,但他没有购买
- Product X was not recommended to R but he ends up purchasing that by searching for the same.不推荐给R使用产品X,但他最终通过搜索购买了该产品。
We were able to see this via checking the record in our booking database and everything was done without any human intervention. With all this analysis we fine-tuned the model so that next time it does recommend product X and product similar to X to R and don’t recommend such product to Q. And this is how our model ends up correcting itself from the mistakes in the past.
通过查看预订数据库中的记录,我们能够看到这一点,并且一切都在没有任何人工干预的情况下完成。 通过所有这些分析,我们对模型进行了微调,以便下次将产品X和与X相似的产品推荐给R,而又不将产品推荐给Q。这就是我们的模型最终从错误中纠正自己的方式。过去。
Note: This is the heart of the system. Stay tuned we will cover it with more details and will also provide you some hands-on over the implementation.
注意:这是系统的心脏。 敬请期待,我们将为您提供更多详细信息,并为您提供一些实现方面的动手操作。
Part4: Post-Processor Service
第4部分:后处理器服务

This service maps the output by the model in the way clients expect. Say if the Model output a probability above 0.5 clients want true and if it’s below 0.5 the client requires false or say our model gives a recommendation score for some products and we need to combine this score with other parameters and finally provide the best k results to the client; all this logic is taken care of via this service.
该服务按照客户期望的方式按模型映射输出。 假设如果模型输出的概率大于0.5,则客户希望为真;如果模型的概率小于0.5,则客户要求为假;或者说我们的模型给出了某些产品的推荐分数,我们需要将此分数与其他参数结合起来,最后提供最佳的k结果以客户端; 所有这些逻辑都通过此服务处理。
Note: We have divided the whole system into four microservices, to have things loosely coupled, so that each service is responsible for its task and need not have any information regarding the other. But it all depends on how much complex your system is. In case the use cases are such that they don’t require us to have separate pre-processor and post-processor services we can club all in one. In case we want to have a separate service for the analysis and feedback loop part we can do that too, it all depends on your platform requirement.
注意:我们将整个系统分为四个微服务,以使事物松散地耦合在一起,因此每个服务都负责其任务,而无需获取有关另一个的任何信息。 但这全取决于系统的复杂程度。 如果用例不要求我们拥有单独的预处理器和后处理器服务,我们可以将所有服务合为一体。 如果我们想为分析和反馈回路部分提供单独的服务,我们也可以这样做,这完全取决于您的平台要求。
Hope you enjoyed the article and got an idea or an overview of how we go about designing a whole Machine Learning system. I know this is kind of brief just to provide you with the helicopter view of the system. There is a lot of insights we need to go into when it comes to working/ building these systems. I will try to write more on it in my upcoming articles as this is just the start.
希望您喜欢这篇文章,并对我们如何设计整个机器学习系统有一个想法或概述。 我知道这只是为了向您提供系统的直升机视图。 在工作/构建这些系统时,我们需要深入研究。 我将在以后的文章中尝试写更多内容,因为这只是开始。
Please do provide you valuable feedback over this as either its humans or machines both require feedback to improve over time and evolve.
请务必为此提供宝贵的反馈,因为无论是人工还是机器,都需要反馈,以随着时间的流逝而改进并不断发展。
Thanks………see you soon.
谢谢…………很快再见。
翻译自: https://medium.com/analytics-vidhya/machine-learning-platform-a0da1bd2257f
机器学习管理平台


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









