



1:LlamaIndex 介绍
「 LlamaIndex is a framework for building context-augmented LLM applications. Context augmentation refers to any use case that applies LLMs on top of your private or domain-specific data. 」
LlamaIndex 是一个为开发「上下文增强」的大语言模型应用的框架(也就是 SDK)。上下文增强,泛指任何在私有或特定领域数据基础上应用大语言模型的情况。例如:
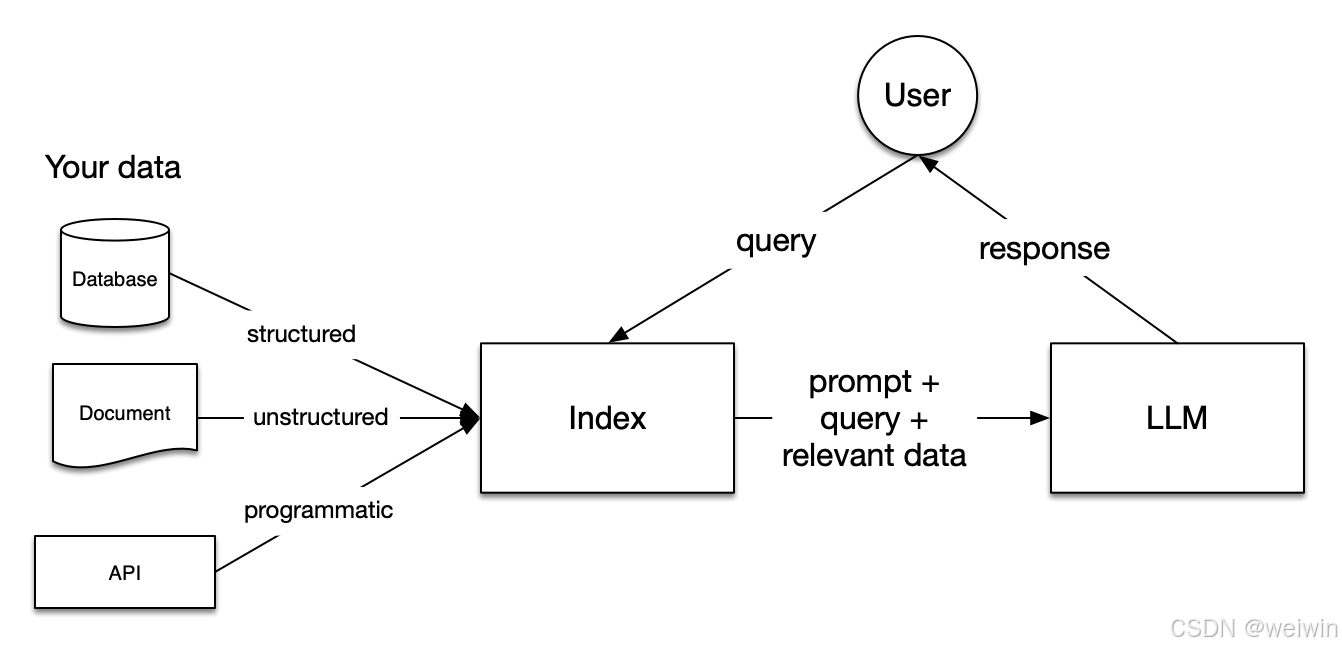
LlamaIndex 有 Python 和 Typescript 两个版本,Python 版的文档相对更完善。
- Python 文档地址:https://docs.llamaindex.ai/en/stable/
- Python API 接口文档:https://docs.llamaindex.ai/en/stable/api_reference/
- TS 文档地址:https://ts.llamaindex.ai/
- TS API 接口文档:https://ts.llamaindex.ai/api/
LlamaIndex 是一个开源框架,Github 链接:https://github.com/run-llama
2: LlamaIndex 的核心模块
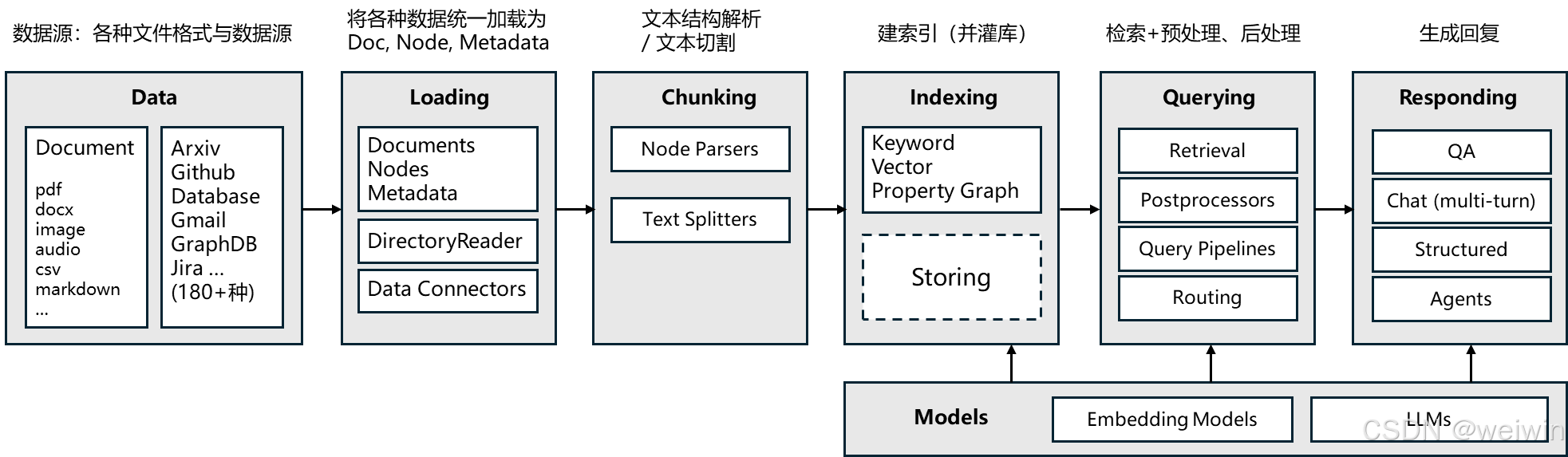
3:安装 LlamaIndex
Python
pip install llama-index4、数据加载(Loading)
官方说明:SimpleDirectoryReader is the simplest way to load data from local files into LlamaIndex. For production use cases it's more likely that you'll want to use one of the many Readers available on LlamaHub, but SimpleDirectoryReader is a great way to get started.
可以通过SimpleDirectoryReader进行简单的本地文件加载器,它会遍历指定目录,并根据文件扩展名自动加载文件,支持格式文件:
.csv - comma-separated values
.docx - Microsoft Word
.epub - EPUB ebook format
.hwp - Hangul Word Processor
.ipynb - Jupyter Notebook
.jpeg, .jpg - JPEG image
.mbox - MBOX email archive
.md - Markdown
.mp3, .mp4 - audio and video
.pdf - Portable Document Format
.png - Portable Network Graphics
.ppt, .pptm, .pptx - Microsoft PowerPoint
from llama_index.core import SimpleDirectoryReader
reader = SimpleDirectoryReader(
input_dir="./data", # 目标目录
recursive=False, # 是否递归遍历子目录,默认为True
required_exts=[".pdf"] # (可选)只读取指定后缀的文件
)
documents = reader.load_data()
如果默认的PDFReader效果不好,想指定文件加载器,可以使用以下方式:
# !pip install pymupdf
from llama_index.core import SimpleDirectoryReader
from llama_index.readers.file import PyMuPDFReader
reader = SimpleDirectoryReader(
input_dir="./data", # 目标目录
recursive=False, # 是否递归遍历子目录
required_exts=[".pdf"], # (可选)只读取指定后缀的文件
file_extractor={".pdf": PyMuPDFReader()} # 指定特定的文件加载器
)
documents = reader.load_data()
print(documents[0].text)5:文档切分与解析
为方便检索,通常会把document切分为Node。
A Node represents a "chunk" of a source Document, whether that is a text chunk, an image, or other. Similar to Documents, they contain metadata and relationship information with other nodes.
Nodes:官方给的方法可以使用SentenceSplitter进行切分
from llama_index.core.node_parser import SentenceSplitter
# load documents
...
# parse nodes
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(documents)
# build index
index = VectorStoreIndex(nodes)也可以使用TextSplitters对文本进行切分
from llama_index.core import Document
from llama_index.core.node_parser import TokenTextSplitter
node_parser = TokenTextSplitter(
chunk_size=100, # 每个 chunk 的最大长度
chunk_overlap=50 # chunk 之间重叠长度
)
nodes = node_parser.get_nodes_from_documents(
documents, show_progress=False
)6:索引(Indexing)与检索(Retrieval)
# 构建 index
index = VectorStoreIndex(nodes)
# 获取 retriever
vector_retriever = index.as_retriever(
similarity_top_k=2 # 返回2个结果
)# 检索
results = vector_retriever.retrieve("******")
















 853
853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









