



爬虫的基本流程
1.发起请求:
通过HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,然后等待服务器响应。这个请求的过程就像我们打开浏览器,在浏览器地址栏输入网址:www.baidu.com,然后点击回车。这个过程其实就相当于浏览器作为一个浏览的客户端,向服务器端发送了 一次请求。
2.获取响应内容:
如果服务器能正常响应,我们会得到一个Response,Response的内容便是所要获取的内容,类型可能有HTML、Json字符串,二进制数据(图片,视频等)等类型。这个过程就是服务器接收客户端的请求,进过解析发送给浏览器的网页HTML文件。
3.解析内容:
得到的内容可能是HTML,可以使用正则表达式,网页解析库进行解析。也可能是Json,可以直接转为Json对象解析。可能是二进制数据,可以做保存或者进一步处理。这一步相当于浏览器把服务器端的文件获取到本地,再进行解释并且展现出来。
4.保存数据:
保存的方式可以是把数据存为文本,也可以把数据保存到数据库,或者保存为特定的jpg,mp4 等格式的文件。这就相当于我们在浏览网页时,下载了网页上的图片或者视频。
相关的库:
- requests库
- lxml类库
Requests库介绍
Requests库是Python中的一个HTTP网络请求库,浏览器会发送信息给该网址所在的服务器
爬取第一个网页
这里以 “http://www.baidu.com“为例。
第一步:导入requests库
import requests
第二步:创建一个url,这里是”http://www.baidu.com”
url = "http://www.baidu.com"
第三步:对”http://www.baidu.com“发起一个get请求
response = requests.get(url)
这里的response是一个对象,response 对象是服务器发送到客户端的数据
第四步:可以调用response对象的方法将服务器端的数据打印一下
print(response.text)
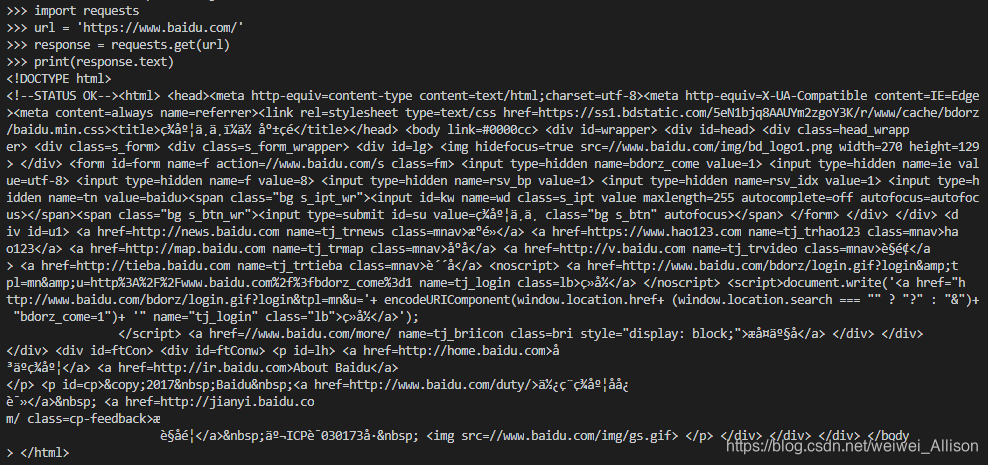
可以看到这里的数据是乱码,出现这种情况的原因是:response.text 的解码是根据HTTP头部对响应的编码做出有根据的推测,推测的文本编码。也就是说它的解码方式只是一种推测,并不一定正确。
那如何修改编码方式呢?
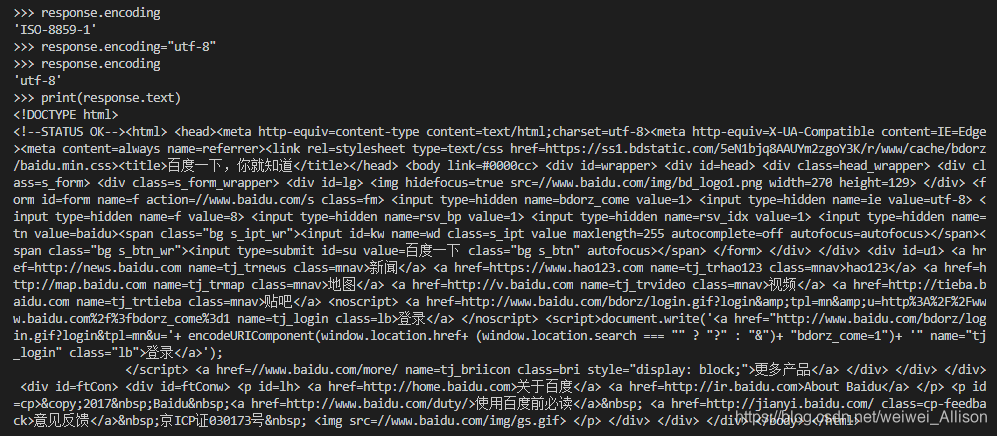
可以在打印之前增加一行:
response.enconding("utf-8")
这行的作用就是将编码格式改为 utf-8 编码,这对大多数网页来说都是可行的。
结果如下:
响应状态:有多种响应状态,比如200代表成功,301 跳转页面,404 表示找不到页面,502 表示服务器错误;
print(response.status_code) # 打印出状态码

lxml类库介绍
lxml类库是一个Html/XML的解析器,主要功能是如何解析和提取HTML/XML数据。
etree将文本转成html:
# 将文本转成html对象
html = etree.HTML(text)
# 将html对象转成html的文本信息
etree.tostring(html)
lxml.etree中提供了几种方法用于解析文本:
etree.fromstring() # 用于解析字符串
etree.HTML() # 用于解析HTML对象
etree.XML() # 用于解析XML对象
etree.parse() # 用于解析文件类型的对象
XPath介绍
XPath(XML Path Language)是一门在XML文档中查找信息的语言,可用来在XML文档中对元素和属性进行遍历。Xpath为XML路径语言,用来确定XML文档中某个位置,类似于地理中经纬网的作用。
XPath的节点有7种类型:文档节点,元素节点,属性节点,文本节点,命名空间节点,处理指令节点,注释节点。对于我们需要关注的是前面4个节点。
用 Xpath 获取静态文本:
import requests
from lxml import etree
# 用Requests库抓取整个页面
url = 'http://data.eastmoney.com/cjsj/cpi.html'
content = requests.get(url).content
# 用etree.HTML()解析对象
html = etree.HTML(content)
# 右键copy.Xpath复制后,通过etree.xpath()函数调用
html.xpath('//*[@id="tb"]/tr[3]/td[2]/text()')
# 部分浏览器会在table标签下添加tbody标签,因此将Xpath中的tbody删去,否则将无法获取数据。
以Chrome为例,按f12检查网页,用箭头点击自己想要的地方,比如我想提取出“故宫博物院”的xpath地址,右击,点击copy,然后选择copy xpath。这样我们就获得“故宫博物院”的xpath。
import requests
from lxml import etree
import lxml
url="http://www.meituan.com/xiuxianyule/271772/"
#你需要爬取的网页
html=requests.get(url)
html.encoding="utf-8"
selecter=etree.HTML(html.text)
#将你的xpath复制到三引号里面,因为xpath里可能有双引号,所以我们加上三引号比较靠谱
s=selecter.xpath("""//*[@id="lego-widget-play-mt-poi-001-000"]/div/div[2]/div[1]/h1/text()""")
print (s)

















 2738
2738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









