










前言:在数据库管理系统中,索引是提高查询性能的核心技术之一,无论是在大数据量的查询场景中,还是在复杂查询条件下,合理使用索引都能显著加快数据检索的速度,MySQL作为一种广泛使用的关系型数据库,其索引机制对于优化查询性能至关重要。
这里是的BLOG
想要了解更多内容可以访问我的主页-优快云博客

在正式开始讲解之前,先让我们看一下本文大致的讲解内容:
目录
**1.**索引简介
在开始学习MySQL的索引之前,先让我们了解一下什么是MySQL中的索引。
(1)索引是什么
在数据库管理系统中,索引是一种用于加速数据查找的数据结构,它通过在数据表上创建额外的数据结构,使得数据库能够更加高效地查找数据行。
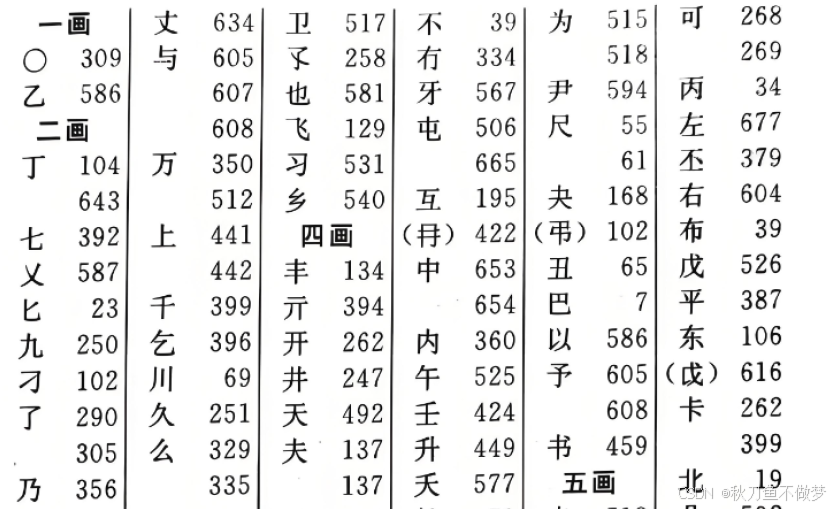
可以将索引比作是一本书的目录,它帮助我们快速定位到特定的章节内容,对于数据库而言,索引类似于书籍中的目录,指引着数据库引擎如何快速定位和访问特定的数据行。
例如,当我们查找一本字典中的某个字时,我们可以通过目录页按照笔画、部首或拼音的顺序快速定位到目标字。(如图)
(2)使用索引的原因
显而易见,使用索引的主要目的是提升数据检索的效率,在大多数数据库应用中,查询操作的频率通常远高于增、删、改等操作。
因此,索引的优化作用尤为突出,尤其是在处理大量数据时,它能够显著减少查询所需的时间,没有索引时,数据库只能进行全表扫描,查找目标数据。而有了索引后,数据库只需查找索引结构,从而大大减少了数据访问的成本。
——这就是为什么我们需要在MySQL中添加索引,并且为什么使用它。
通过上述的简短介绍之后,读者应该对索引有了一定的了解了,那么接下来就让我们开始正式的学习MySQL中的索引吧!
2.索引使用的数据结构
在上文中我们已经说到,MySQL中的索引是一种数据结构,那么其到底是哪种数据结构呢?接下来让我们一起探索一下:
(1)HASH
我们知道哈希索引的时间复杂度是O(1),查询速度非常快,在理想情况下,哈希索引能够实现常数时间的查找。然而,哈希索引的局限性在于它不支持范围查询,比如,BETWEEN、>、<等操作都无法通过哈希索引高效执行,因此它并不适用于所有的查询场景。
——所以MySQL并没有将哈希作为默认的索引数据结构,原因就在于它的这些局限性。
(2)二叉搜索树
二叉搜索树是一个经典的数据结构,其中每个节点的值都大于其左子树的所有节点,小于其右子树的所有节点,通过这种结构,我们可以在有序的数据集中实现高效的查找,然而,二叉搜索树在最坏情况下的时间复杂度为O(N),并且随着数据量的增加,树的高度可能会非常大,导致查询性能下降。
虽然AVL树和红黑树等自平衡二叉树可以在一定程度上缓解这一问题,但二叉树依然存在每次检索都需要访问多个节点,导致频繁的磁盘I/O操作,这些磁盘I/O操作在数据库系统中是性能瓶颈,因此二叉搜索树也不是MySQL中的索引的数据结构。
(3)N叉树
为了克服二叉树的问题,N叉树通过将每个节点的子节点数量增加到N(大于2)来有效降低树的高度,当日这也意味着相同数据量的情况下,N叉树的树高比二叉树要低,减少了每次查询时需要访问的节点数,从而减少了磁盘I/O的次数,提升了查询效率。
但是尽管N叉树在理论上能够有效地提高查询效率,MySQL也并未选择N叉树作为默认的索引数据结构,原因是N叉树虽然在减少树高方面有优势,但是还有更好的数据结构。
(4)B+树
最后我们来说一下MySQL中默认索引数据结构,B+树,其作为MySQL的默认索引数据结构,在数据库系统中得到了广泛的应用。B+树是一种自平衡的多路查找树,它通过非叶子节点存储索引信息,叶子节点则存储实际的数据。这种结构的最大优势在于它能有效保持数据的有序性,并且支持范围查询,特别适合处理大量数据的检索。
根据上述所述,B+树就作为了MySQL中索引的数据结构的最佳选择。
3.索引类型
在了解完了MySQL中索引所使用的数据结构之后,让我们来学习一下在MySQL中到底又哪些索引类型:
(1)主键索引
主键索引是数据库中的特殊索引类型,用于保证表中数据的唯一性和完整性,每个表只能有一个主键索引,通常是通过
PRIMARY KEY约束来创建,主键索引也是聚集索引,即数据表的数据行是按主键值顺序存储的。
让我们看一个创建主键索引的例子:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100)
);
特点:
- 每个表只能有一个主键索引。
- 数据行按照主键值的顺序存储(聚集存储)。
- 保证主键列数据的唯一性,不允许重复值。
- 不允许
NULL值。
(2)普通索引
普通索引是最基本的索引类型,用于加速查询操作,它不要求列的值唯一,适用于没有唯一性要求的场景。
让我们看一个创建普通索引的例子:
CREATE INDEX idx_name ON users(name);
特点:
- 用于加速查询。
- 允许列中有重复值。
- 可以包含
NULL值。- 适用于单列查询。
(3)唯一索引
唯一索引与普通索引类似,但它保证了索引列中的数据值唯一,唯一索引常用于确保数据列的唯一性,如用户邮箱、身份证号等。
让我们看一个创建唯一索引的例子:
CREATE UNIQUE INDEX idx_unique_email ON users(email);
特点:
- 保证索引列中的数据唯一,不允许重复值。
- 允许一个
NULL值(取决于数据库实现)。- 可以用于多个列的组合,确保组合列的唯一性。
(4)全文索引
全文索引是专门用于加速对大文本字段进行查询的索引类型,通常用于
TEXT类型或VARCHAR类型的字段,全文索引支持模糊匹配,可以对长文本内容进行高效的全文检索,通过MATCH ... AGAINST语句来执行全文搜索。
让我们看一个创建全文索引的例子:
CREATE FULLTEXT INDEX idx_fulltext_content ON articles(content);
特点:
- 用于加速对大文本字段(如
TEXT)的全文搜索。- 支持模糊查询和自然语言查询。
- 不适用于小字段或常规查询。
- 在MySQL中,只有
MyISAM和InnoDB(8.0及以上)支持全文索引。
(5)聚集索引
聚集索引是数据库中唯一的索引类型,数据表的实际数据存储顺序与聚集索引的顺序相同,每个表只能有一个聚集索引,因为数据行只能有一个排序顺序,通常,主键索引即为聚集索引,如果没有主键,数据库会选择其他唯一的列作为聚集索引。
让我们看一个创建聚集索引的例子:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100)
);
——其实我们发现主键索引就是聚集索引!!!
特点:
- 每个表只能有一个聚集索引。
- 数据行按照索引顺序存储。
- 索引创建时,表的数据会重新排序。
- 聚集索引查询范围数据时效率较高,但插入、删除数据时可能会有额外开销。
(6)非聚集索引
非聚集索引是指索引的顺序与数据存储的顺序无关。与聚集索引不同,非聚集索引将索引数据和实际数据行分开存储。非聚集索引通常用于加速对单列或多列的查询,可以有多个非聚集索引。
让我们看一个创建非聚集索引的例子:
CREATE INDEX idx_name ON users(name);
特点:
- 可以在一个表上创建多个非聚集索引。
- 索引存储与数据存储顺序无关。
- 查询效率较高,但插入、删除和更新时需要额外维护索引。
- 对于常用查询字段,非聚集索引可以提高查询性能。
以上就是MySQL中的常见的索引类型了!
4.索引的使用
了解完了索引的类型之后,那么我们如何在MySQL中使用索引呢?接下来就让我们学习一下在MySQL中如何使用索引:
(1)自动创建
当我们为一张表加主键约束(Primary key),外键约束(Foreign Key),唯一约束(Unique)的时候,这时MySQL会为对应的的列自动创建一个索引,如果表不指定任何约束时,MySQL会自动为每一列生成一个索引并用 ROW_ID 进行标识,这就是所谓的MySQL中的自动创建索引。
(2)手动创建
有了自动创建索引,那就肯定有手动创建索引啦,接下来让我们分别学习一下如何手动创建主键索引,唯一索引和普通索引:
【1】手动创建主键索引
方式一:创建表时直接在列定义中设置主键:
CREATE TABLE t_test_pk (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20)
);
特点:
- 简洁:主键和自增属性直接写在列定义中,语法直观。
- 自动增长:
AUTO_INCREMENT结合PRIMARY KEY,可用于生成唯一标识符。- 常用场景:适用于单列主键需求,设计清晰明确。
方式二:创建表时单独指定主键
CREATE TABLE t_test_pk1 (
id BIGINT AUTO_INCREMENT,
name VARCHAR(20),
PRIMARY KEY (id)
);
特点:
- 分离定义:主键的定义单独通过
PRIMARY KEY指定,不和列的定义绑定。- 灵活性高:适合更复杂的场景,如联合主键:
- 适用场景:当表结构复杂,需要后期更改主键定义时推荐使用这种方式
方式三:修改表后设置主键
创建表时未定义主键:
CREATE TABLE t_test_pk2 (
id BIGINT,
name VARCHAR(20)
);
修改表,添加主键:
ALTER TABLE t_test_pk2 ADD PRIMARY KEY (id);
ALTER TABLE t_test_pk2 MODIFY id BIGINT AUTO_INCREMENT;
特点:
- 后期调整:适用于初始创建时未定义主键的表。
- 分步骤设置:
ADD PRIMARY KEY将某列设为主键。MODIFY修改列属性为自增。- 适用场景:表已经存在,且需要后续添加主键时使用。
以上就是在MySQL中手动创建主键索引的所有方式了!
【2】手动创建唯一索引
了解完了如何手动创建主键索引之后,在让我们看一下如何去手动创建唯一索引:
方式一:创建表时直接在列定义中设置唯一键
CREATE TABLE t_test_uk (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) UNIQUE
);
特点:
- 简洁直观:唯一约束直接在列定义中声明,语法清晰。
- 适用场景:适用于为单列设置唯一约束,代码简洁。
方式二:创建表时单独指定唯一约束
CREATE TABLE t_test_uk1 (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20),
UNIQUE (name)
);
特点:
- 分离定义:唯一约束与列定义分开,易于修改和调整。
- 适用场景:适用于多个唯一约束或后期调整约束的情况。
方式三:修改表后设置唯一约束
CREATE TABLE t_test_uk2 (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20)
);
ALTER TABLE t_test_uk2 ADD UNIQUE (name);
特点:
- 后期调整:适用于在表创建后需要添加唯一约束的场景。
- 灵活性高:可以在已有表中添加或修改唯一约束。
以上就是在MySQL中手动创建唯一索引的所有方式了!
【3】手动创建普通索引
最后让我们看一下如何手动创建普通索引:
方式一:创建表时指定索引列
CREATE TABLE t_test_index (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) UNIQUE,
sno VARCHAR(10),
INDEX (sno)
);
特点:
- 简洁:在表创建时直接为特定列添加索引,语法简单明了。
- 适用场景:适用于表结构设计时直接考虑索引的情况。
方式二:修改表中的列为普通索引
CREATE TABLE t_test_index1 (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20),
sno VARCHAR(10)
);
ALTER TABLE t_test_index1 ADD INDEX (sno);
特点:
- 灵活性高:可以在表创建后添加索引,适用于已经存在的表。
- 适用场景:适用于已存在的表,需要根据查询需求后续添加索引的情况。
方式三:单独创建索引并指定索引名
CREATE TABLE t_test_index2 (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20),
sno VARCHAR(10)
);
CREATE INDEX index_name ON t_test_index2(sno);
特点:
- 自定义索引名:可以为索引指定自定义的名字,方便后续管理和引用。
- 适用场景:当需要为表中的列创建索引,并且希望指定索引名时使用。
以上就是在MySQL中手动创建普通索引的所有方式了!
(3)创建复合索引
在了解完了手动创建主键索引、唯一索引和普通索引之后,细心的读者可能会发问,难道只能将一列设置为索引吗?答案是——不是的,我们可以将多列设置为复合索引。
而创建语法与创建普通索引相同,只不过指定多个列,列与列之间用逗号隔开:
方式一:创建表时指定复合索引列
CREATE TABLE t_test_index4 (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20),
sno VARCHAR(10),
class_id BIGINT,
INDEX (sno, class_id)
);
特点:
- 简洁:在表创建时直接为多个列指定复合索引,语法简洁。
- 适用场景:适用于在表设计时就需要为多个列创建复合索引的情况。
方式二:修改表中的列为复合索引
CREATE TABLE t_test_index5 (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20),
sno VARCHAR(10),
class_id BIGINT
);
ALTER TABLE t_test_index5 ADD INDEX (sno, class_id);
特点:
- 灵活性高:可以在表创建后根据需要添加复合索引。
- 适用场景:适用于已经存在的表,在后期需要根据查询需求添加复合索引
方式三:单独创建索引并指定索引名
CREATE TABLE t_test_index6 (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20),
sno VARCHAR(10),
class_id BIGINT
);
CREATE INDEX index_name ON t_test_index6 (sno, class_id);
特点:
- 自定义索引名:可以为复合索引指定自定义的名字,方便后续管理和引用。
- 适用场景:当需要为多个列创建复合索引,并且希望指定索引名时使用。
以上就是在MySQL中创建复合索引的三种方式了!!!
(4)查看索引
在了解完了创建索引之后,接下来让我们学习一下如何在MySQL中查看索引,其有两种方式:
第一种:使用 SHOW INDEX 命令
SHOW INDEX FROM 表名;
解释:
- 该命令可以查看指定表的所有索引信息。
- 返回结果包括索引名称、列名、唯一性、索引类型等。
第二种:使用 SHOW CREATE TABLE 命令
SHOW CREATE TABLE 表名;
解释:
- 此命令会显示表的完整创建语句,包括表中的所有索引。
- 返回结果中的
KEY或INDEX部分显示了表中定义的索引。
以上就是在MySQL中查看索引的方式了!
(5)删除索引
最后让我们看一下在MySQL中如何去删除索引,一共两种方式,一种删除主键索引,一种删除其他索引(非主键):
(1)删除主键索引
ALTER TABLE 表名 DROP PRIMARY KEY;
使用场景:
- 删除主键:如果你需要修改表的设计,或者表中的主键列不再适用,可以通过此语句删除主键。例如,主键列数据类型不适合或想要将主键列改为其他列。
- 复合主键:如果表使用了多个列作为主键(复合主键),可以删除整个复合主键。
例子:
ALTER TABLE users DROP PRIMARY KEY;
解释:这条语句会删除 users 表中的主键。
(2)删除其他索引
ALTER TABLE 表名 DROP INDEX 索引名;
使用场景:
- 删除不再需要的索引:如果某个索引不再用于优化查询,可以删除它。删除无用的索引有助于减少存储空间的使用,并提高写入操作(如 INSERT、UPDATE)的效率。
- 替换索引:在某些情况下,可能会创建一个新的索引来替换现有索引。删除旧的索引是优化表结构的一部分。
例子:
ALTER TABLE employees DROP INDEX idx_name;
解释:这条语句删除了 employees 表中名为 idx_name 的索引。
以上就是删除索引的方式了!!!
以上就是本篇文章全部内容~~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









