




 本文介绍如何使用百度OCR服务与Selenium库自动化识别网页中的验证码,包括申请百度OCR服务、安装所需库、编写验证码识别代码及登录网站自动化流程。
本文介绍如何使用百度OCR服务与Selenium库自动化识别网页中的验证码,包括申请百度OCR服务、安装所需库、编写验证码识别代码及登录网站自动化流程。
百度OCR申请:
先申请一个百度账号,然后搜索百度智能云,登录进入

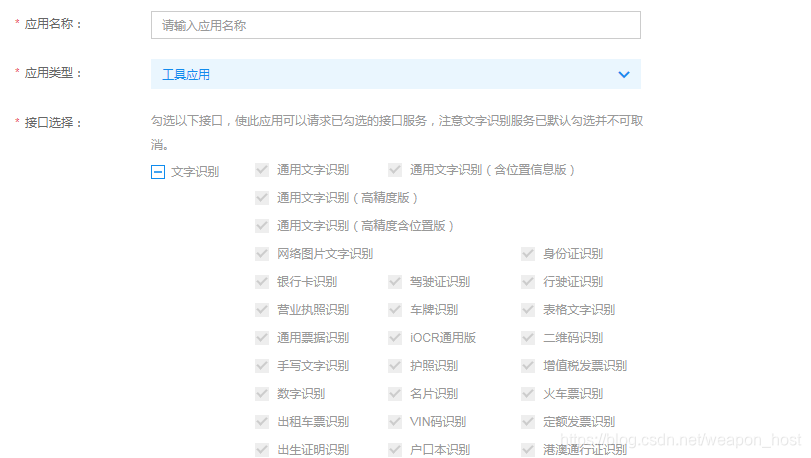
创建完成后会获得一个AppID,APIKey,Secret Key,等下会用到。
接下来开始编写代码,在这之前,要安装好python3,selenium,baidu-aip(安装自行百度)
我们首先写一个百度OCR的类,第一步,导入我们需要的安装包
from os import path
from aip import AipOcr
类代码:
class BaiduOCR:
def __init__(self, picfile):
self.picfile = picfile
def baiduOCR(self):
"""利用百度api识别文本,并保存提取的文字
picfile: 图片文件名
"""
filename = path.basename(self.picfile)
# 你的AppID,APIKey,Secret Key
APP_ID = '1852****'
API_KEY = 'b5jRwiOvBFmyeTD******'
SECRECT_KEY = '0UYTZDzFCcd2WExctrbHMxM***********'
client = AipOcr(APP_ID, API_KEY, SECRECT_KEY)
i = open(self.picfile, 'rb')
img = i.read()
print("正在识别图片:\t" + filename)
# basicGeneral : 通用文字识别
# basicAccurate : 通用文字识别(高精度版)
# general : 通用文字识别(含位置信息版)
# accurate : 通用文字识别(含位置高精度版)
# enhancedGeneral : 通用文字识别(含生僻字版)
# webImage : 网络图片文字识别
# 还有更多参数可选,具体详情可自查Api文档
message = client.webImage(img) # 网络文字识别,每天 50 000 次免费
# message = client.basicAccurate(img) # 通用文字高精度识别,每天 800 次免费
# 打印信息可注释掉,此处是为了调试
print 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









