




 本文介绍Map端Join技术,包括其实现原理与步骤,并通过具体示例展示了如何利用DistributedCache在MapReduce中实现表连接。
本文介绍Map端Join技术,包括其实现原理与步骤,并通过具体示例展示了如何利用DistributedCache在MapReduce中实现表连接。
一:背景
MapReduce提供了表连接操作其中包括Map端join、Reduce端join还有半连接,现在我们要讨论的是Map端join,Map端join是指数据到达map处理函数之前进行合并的,效率要远远高于Reduce端join,因为Reduce端join是把所有的数据都经过Shuffle,非常消耗资源。
二:技术实现
基本思路:
(1):需要join的两个文件,一个存储在HDFS中,一个使用DistributedCache.addCacheFile()将需要join的另外一个文件加入到所有Map缓存中。
(2):在Map函数里读取该文件,进行join
(3):将结果输出到reduce
(4):DistributedCache.addCacheFile()需要在作业提交前设置。
什么是DistributedCache?
DistributedCache是为了方便用户进行应用程序开发而设计的文件分发工具。它能够将只读的外部文件进行自动分发到各个节点上进行本地缓存,以便task运行时加载。
DistributedCache的使用步骤
(1):在HDFS中上传文件(文本文件、压缩文件、jar包等)
(2):调用相关API添加文件信息
(3):task运行前直接调用文件读写API获取文件。
常见API:
DistributedCache.addCacheFile();
DistributedCache.addCacheArchive();
下面我们通过一个示例来深入体会Map端join。
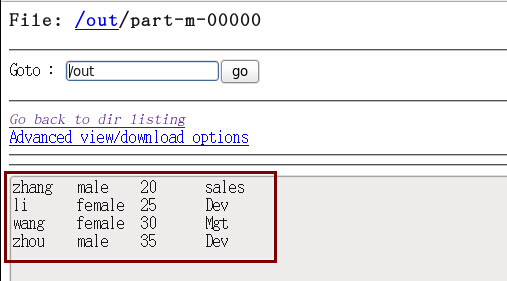
表一:tb_a数据如下
- name sex age depNo
- zhang male 20 1
- li female 25 2
- wang female 30 3
- zhou male 35 2
表二:tb_b数据如下
- depNo depName
- 1 sales
- 2 Dev
- 3 Mgt
#需求就是连接上面两张表
注意:在Map端join操作中,我们往往将较小的表添加到内存中,因为内存的资源是很宝贵的,这也说明了另外一个问题,那就是如果表的数据量都非常大则不适合使用Map端join。
代码如下:
- public class MyMapJoin {
- // 定义输入路径
- private static String INPUT_PATH1 = "";
- //加载到内存的表的路径
- private static String INPUT_PATH2 = "";
- // 定义输出路径
- private static String OUT_PATH = "";
- public static void main(String[] args) {
- try {
- // 创建配置信息
- Configuration conf = new Configuration();
- // 获取命令行的参数
- String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
- // 当参数违法时,中断程序
- if (otherArgs.length != 3) {
- System.err.println("Usage:MyMapJoin<in1> <in2> <out>");
- System.exit(1);
- }
- // 给路径赋值
- INPUT_PATH1 = otherArgs[0];
- INPUT_PATH2 = otherArgs[1];
- OUT_PATH = otherArgs[2];
- // 创建文件系统
- FileSystem fileSystem = FileSystem.get(new URI(OUT_PATH), conf);
- // 如果输出目录存在,我们就删除
- if (fileSystem.exists(new Path(OUT_PATH))) {
- fileSystem.delete(new Path(OUT_PATH), true);
- }
- // 添加到内存中的文件(随便添加多少个文件)
- DistributedCache.addCacheFile(new Path(INPUT_PATH2).toUri(), conf);
- // 创建任务
- Job job = new Job(conf, MyMapJoin.class.getName());
- // 打成jar包运行,这句话是关键
- job.setJarByClass(MyMapJoin.class);
- //1.1 设置输入目录和设置输入数据格式化的类
- FileInputFormat.setInputPaths(job, INPUT_PATH1);
- job.setInputFormatClass(TextInputFormat.class);
- //1.2 设置自定义Mapper类和设置map函数输出数据的key和value的类型
- job.setMapperClass(MapJoinMapper.class);
- job.setMapOutputKeyClass(NullWritable.class);
- job.setMapOutputValueClass(Emp_Dep.class);
- //1.3 设置分区和reduce数量
- job.setPartitionerClass(HashPartitioner.class);
- job.setNumReduceTasks(0);
- FileOutputFormat.setOutputPath(job, new Path(OUT_PATH));
- // 提交作业 退出
- System.exit(job.waitForCompletion(true) ? 0 : 1);
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- public static class MapJoinMapper extends Mapper<LongWritable, Text, NullWritable, Emp_Dep> {
- private Map<Integer, String> joinData = new HashMap<Integer, String>();
- protected void setup(Mapper<LongWritable, Text, NullWritable, Emp_Dep>.Context context) throws IOException, InterruptedException {
- // 预处理把要关联的文件加载到缓存中
- Path[] paths = DistributedCache.getLocalCacheFiles(context.getConfiguration());
- // 我们这里只缓存了一个文件,所以取第一个即可,创建BufferReader去读取
- BufferedReader reader = new BufferedReader(new FileReader(paths[0].toString()));
- String str = null;
- try {
- // 一行一行读取
- while ((str = reader.readLine()) != null) {
- // 对缓存中的表进行分割
- String[] splits = str.split("\t");
- // 把字符数组中有用的数据存在一个Map中
- joinData.put(Integer.parseInt(splits[0]), splits[1]);
- }
- } catch (Exception e) {
- e.printStackTrace();
- } finally{
- reader.close();
- }
- }
- protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, NullWritable, Emp_Dep>.Context context) throws IOException,
- InterruptedException {
- // 获取从HDFS中加载的表
- String[] values = value.toString().split("\t");
- // 创建Emp_Dep对象
- Emp_Dep emp_Dep = new Emp_Dep();
- // 设置属性
- emp_Dep.setName(values[0]);
- emp_Dep.setSex(values[1]);
- emp_Dep.setAge(Integer.parseInt(values[2]));
- // 获取关联字段depNo,这个字段是关键
- int depNo = Integer.parseInt(values[3]);
- // 根据depNo从内存中的关联表中获取要关联的属性depName
- String depName = joinData.get(depNo);
- // 设置depNo
- emp_Dep.setDepNo(depNo);
- // 设置depName
- emp_Dep.setDepName(depName);
- // 写出去
- context.write(NullWritable.get(), emp_Dep);
- }
- }
- }
注:这个程序不知道为什么要打成jar包的方式才能运行,直接通过Eclipse链接服务器运行会失败(如果有知道的朋友,请指教!)

















 464
464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









