







一个朋友在某运动品牌公司上班,老板给他布置了一个处理客户订单数据的任务。要求是根据订单时间和客户id判断生成四个新的数据:
1、记录该客户是第几次光顾
2、上一次的日期时间是什么时候
3、与上次订单的间隔时间
4、这是一个existing客户还是一个new客户(见定义)
文件说明:
1、第一列是订单日期和时间(乱序)
2、第二列是客户的id
3、第三列不需要使用
4、60+万行数据
相关定义如下:
1、existing:此次下单日期时间与上次日期时间的距离在N天以内,精确到时间(时分秒)
2、new:即超过N天
整体思路
1、读取表格的行数据存储成list,并按照时间列的升序排序。
2、维护一个map(在python里是字典dict),每个用户 id 作为key,一个二元组(第几次下单,上一次的日期时间)作为value。
3、遍历表格行数据的list。判断客户 id 是否已经存在于map中,若首次出现,则置该客户 id 在map中的value为[1,‘首次下单’],对应行数据新增的4个数据为[1,‘首次下单’,该次日期时间与上次日期时间差,‘new’]。若已经存在,则更新map中对应的value为[原次数+1,该次日期时间],对应行数据新增的4个数据为[原次数+1,上次日期时间,间隔时间,new/existing取决于间隔时间与预设N]Python资源分享秋秋裙 855408893 ,内有安装包,学习视频资料,免费直播实战案例。这里是Python学习者的聚集地,零基础,进阶,都欢迎
4、将修改过后的行数据list写入到Excel工作簿并保存。
读取表格数据
我们可以用xlrd模块对Excel文件进行读取,以便进一步分析处理数据。示例代码如下:
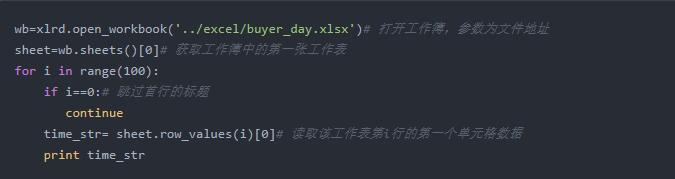
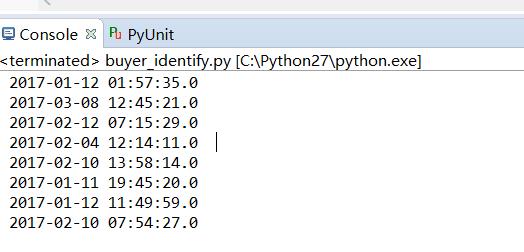
以上代码成功输出前100行的日期则说明已经成功读取到数据。输出结果如下:
既然读取文件没有问题,进一步浏览整个文件发现存在多余的空行和重复的标题行在读取和转存中可以用正则匹配过滤掉这些行。
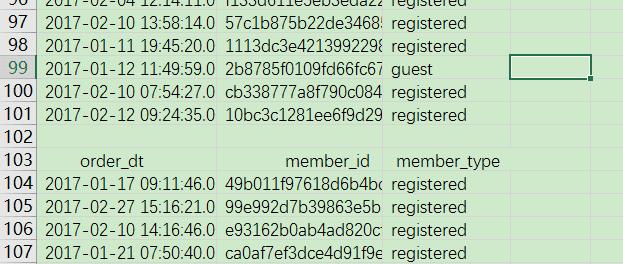
将读取的行数据转存到list中,以便进行排序。
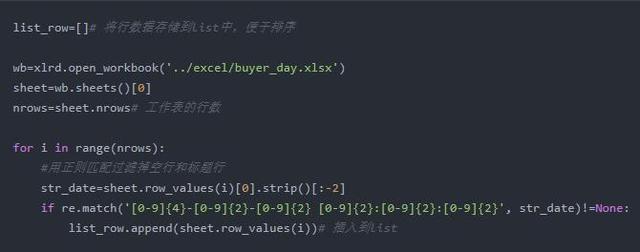
将修改后的行数据list写入Excel表格并保存为xslx格式
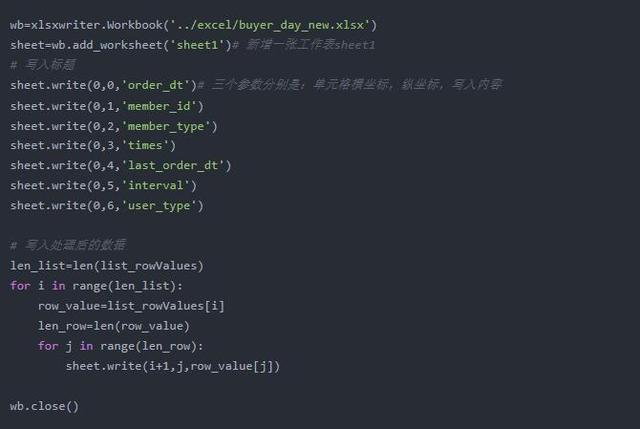
结果展示
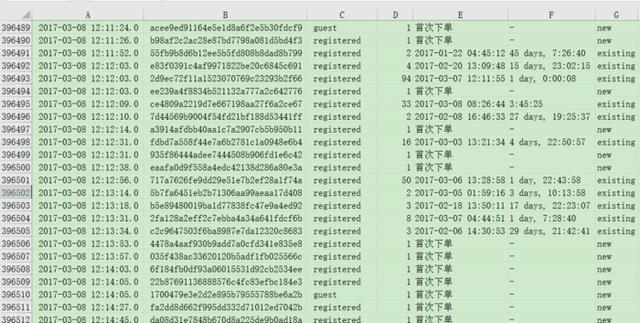
完整代码

















 1607
1607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









