






 文章对比了Python内置列表和自定义链表在不同规模下的性能,发现链表在大数据量下对插入和删除操作有优势,小于10000时两者性能接近,但创建对象消耗的时间影响了实验结果。
文章对比了Python内置列表和自定义链表在不同规模下的性能,发现链表在大数据量下对插入和删除操作有优势,小于10000时两者性能接近,但创建对象消耗的时间影响了实验结果。
据说 python 中的list是用数组实现的,相比于链表,数组的优势在于节省空间和索引查询快O(1),但是插入和删除O(n)都慢。
做个实验在验证下:
自己写了一个链表:
# file: my_linked_list.py
class LinkedListNode(object):
def __init__(self, data):
self.data = data
self.next = None
class LinkedList(object):
def __init__(self):
self.head = None
self.tail = None
# self.size = 0
def append(self, new_node):
if self.tail is None:
self.tail = new_node
self.head = new_node
else:
self.tail.next = new_node
self.tail = new_node
# self.size += 1
def append_with_data(self, data):
self.append(LinkedListNode(data))
def clear(self):
self.head = None
self.tail = None
# self.size = 0
def pop_left(self):
ret = self.head
if self.head:
self.head = self.head.next
ret.next = None
if self.head is None:
self.tail = None
return ret
性能测试:
# file: main.py
import time
from my_linked_list import LinkedList, LinkedListNode
def test_py_list(size=10000, loop=100):
lt = []
total_pop_time = 0
total_append_time = 0
for i in range(loop):
# append
abt = time.time()
for j in range(size):
lt.append(LinkedListNode(j))
aet = time.time()
total_append_time += (aet - abt)
# pop
pbt = time.time()
for k in range(size - 1):
lt.pop(1)
lt.clear()
pet = time.time()
total_pop_time += (pet - pbt)
print("append time: {} ms".format(total_pop_time * 1000))
print("pop time: {} ms".format(total_append_time * 1000))
def test_my_linked_list(size=10000, loop=100):
lt = LinkedList()
total_pop_time = 0
total_append_time = 0
for i in range(loop):
# append
abt = time.time()
for j in range(size):
lt.append(LinkedListNode(j))
aet = time.time()
total_append_time += (aet - abt)
# pop
pbt = time.time()
for k in range(size - 1):
lt.pop_left()
pet = time.time()
lt.clear()
total_pop_time += (pet - pbt)
print("append time: {} ms".format(total_append_time * 1000))
print("pop time: {} ms".format(total_pop_time * 1000))
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
list_size = 1000
while list_size <= 100000:
print('===== list size:{} ====='.format(list_size))
print('===== test_py_list')
test_py_list(size=list_size)
print('===== test_my_linked_list')
test_my_linked_list(size=list_size)
list_size *= 10
测试结果如下:
| python list | linked list | |||
| size | append | pop left | append | pop left |
| 1000 | 15 | 31 | 31 | 31 |
| 3000 | 46 | 94 | 94 | 94 |
| 9000 | 655 | 111 | 393 | 217 |
| 27000 | 4346 | 836 | 1257 | 745 |
| 81000 | 39582 | 3048 | 4591 | 2248 |
| 243000 | 1046307 | 13355 | 18667 | 6456 |
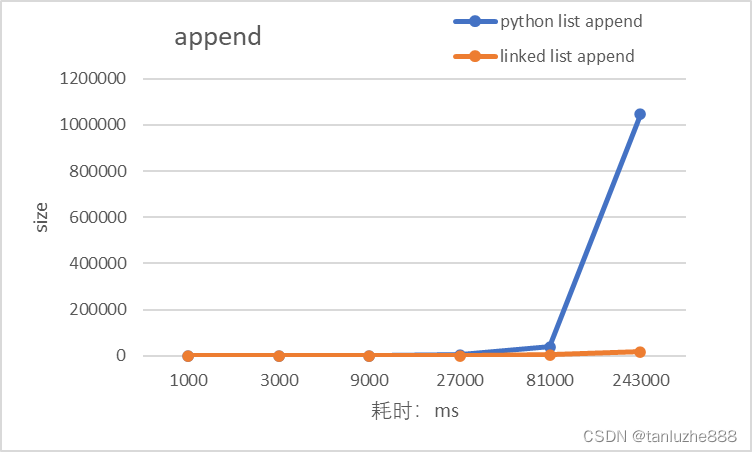
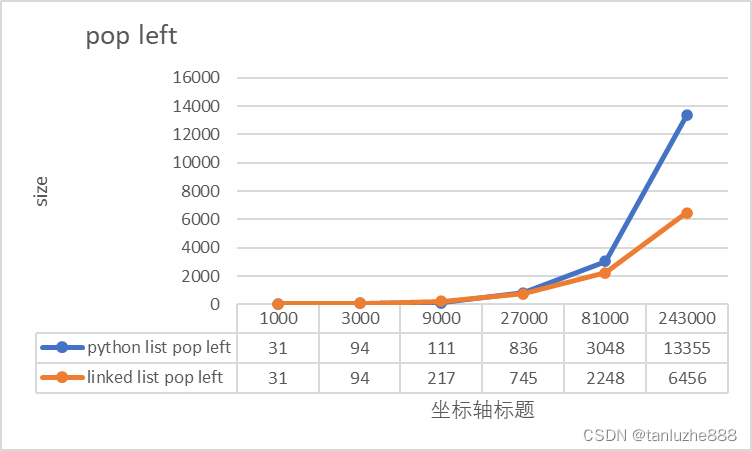
从结果中可以看到:
1)整体来说,性能上还是链表要好于原生的list,而且数据量越大,这种优势越明显;
2)当数据量低于10000时,性能差距并不大,这里的10000只是粗略值,也可能分界线在几千;
3)注意,在向原生list中填入数据的时候也用了链表的节点,实际操作中这是不必要的,这么做的原因是:创建对象似乎在python中很耗时,都是用对象可以拉平这一差距,这样才有可比性。但是,如果python list仅仅是填入简单数据,如int, 那么两者性能的分界线估计要高于10000。
总的来说,数据量10000以下可以选原生list,10000以上最好是链表。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









