



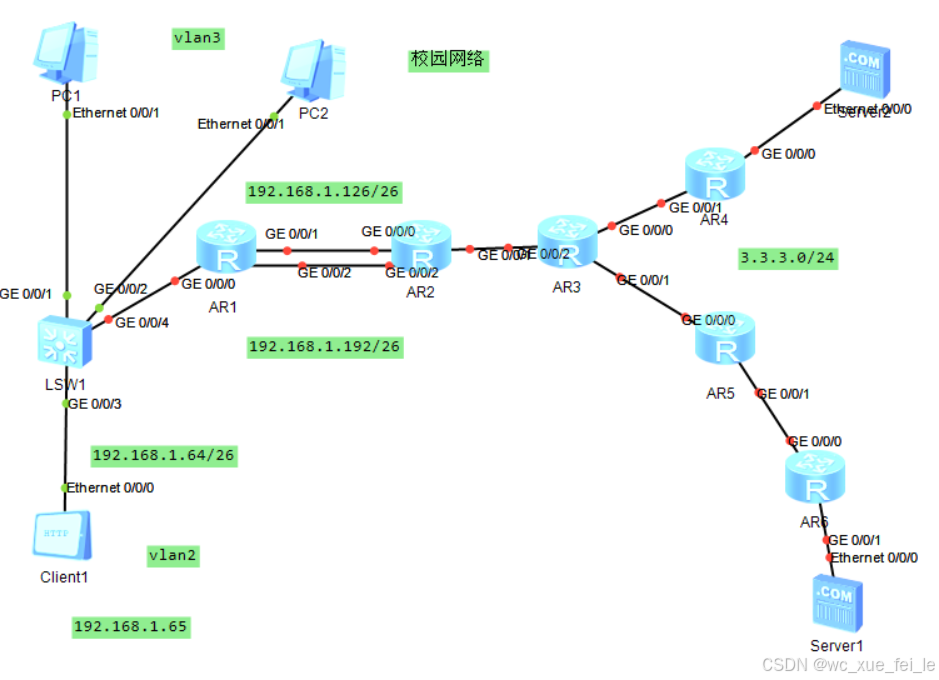
一.拓扑图
二、实验要求
1.学校内部的HTTP客户端可以正常通过域名www.baidu.com访问到百度网络中的HTTP服务器
2.学校网络内部网段基于192.168.1.0/24划分,PC1可以正常访问3.3.3.0/24网段,但是PC2不允许
3.学校内部路由使用静态路由,R1和R2之间两条链路进行浮动静态
4.运营商网络内部使用动态路由协议
5.AR1可以被telnet远程控制
三、实验需求分析
1.配置好HTTP后,在服务器信息选择HttpServer选择文件目录后启动,就可以访问HTTP服务器。
2.学校内部需要四个网段,从主机位借2个位给网络位:
192.168.1.0/26
192.168.1.00 000000 192.168.1.0/26
192.168.1.01 000000 192.168.1.64/26
192.168.1.10 000000 192.168.1.128/26
192.168.1.11 000000 192.168.1.192/26
3.手动配置静态路由信息;r1和r2之间为每条链路设置不同的优先级
4.运营商网络内使用OSPF协议进行配置
5.在AR1配置telent服务,并保证客户端可以访问到AR1
四、实验步骤
1.对学校内部
由于具有VLAN2和VLAN3,则学校内部网络有四个广播域。其次要做学校内部的基于192.168.1.0/24的网段的划分
<SW1>system-view
[SW1]vlan batch 2 3
[SW1]interface GigabitEthernet0/0/3
[SW1-GigabitEthernet0/0/3]port link-type access
[SW1-GigabitEthernet0/0/3]port default vlan 2
[SW1]interface GigabitEthernet 0/0/4
[SW1-GigabitEthernet0/0/4]port link-type trunk
[SW1-GigabitEthernet0/0/4]port trunk allow-pass vlan 2 3
[R2]interface GigabitEthernet 0/0/0.1
[R2-GigabitEthernet0/0/0.1]dot1q termination vid 2
[R2-GigabitEthernet0/0/0.1]ip address 192.168.1.190 24
[R2-GigabitEthernet0/0/0.1]arp broadcast enable
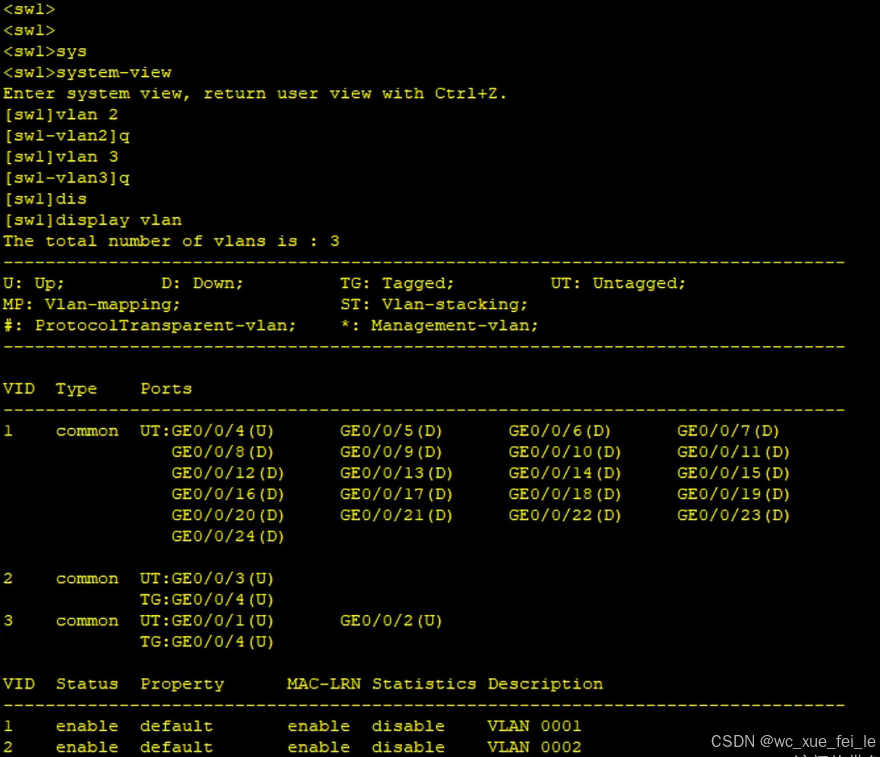
路由配置
配置r1
[R1]interface g0/0/1 #进入接口
[R1-GigabitEthernet0/0/1]ip address 192.168.1.1 26 #配置IP地址以及子网掩码
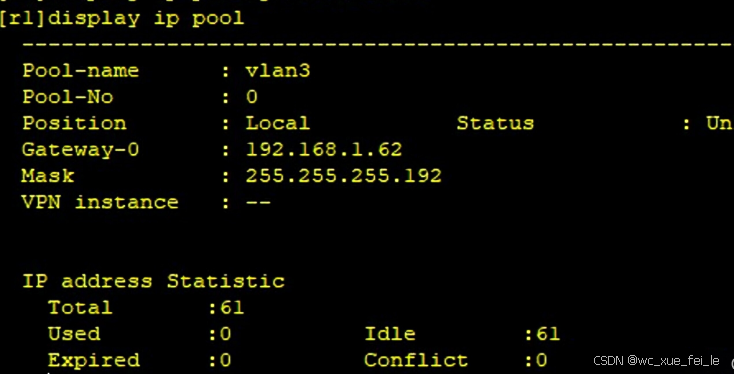
学校内部网络使用静态路由,R1和R2之间两条路进行浮动静态
配置r2
[AR2-GigabitEthernet0/0/2]ip address 192.168.1.1 30
[AR2-GigabitEthernet0/0/1]ip address 192.168.1.5 30
[AR2]interface g0/0/0.2
[AR2-GigabitEthernet0/0/0.2]dot1q termination vid 2
[AR2-GigabitEthernet0/0/0.2]ip address 192.168.1.129 26
[AR2-GigabitEthernet0/0/0.2]interface g0/0/0.3
[AR2-GigabitEthernet0/0/0.3]dot1q termination vid 3
[AR2-GigabitEthernet0/0/0.3]ip address 192.168.1.193 26
[AR2]ip route-static 0.0.0.0 0 192.168.1.2
[AR2]ip route-static 0.0.0.0 0 192.168.1.6 preference 61

配置r3
[AR3-GigabitEthernet0/0/0]ip address 13.0.0.3 24
[AR3-GigabitEthernet0/0/1]ip address 34.0.0.3 24
[AR3-GigabitEthernet0/0/2]ip address 35.0.0.3 24
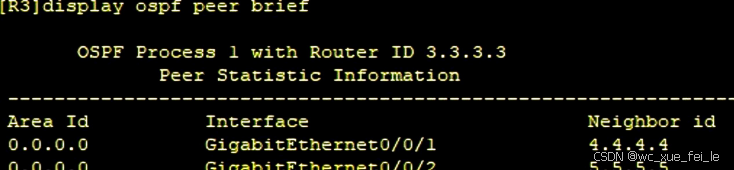
[AR3]rip 1
[AR3-rip-1]verify-source
[AR3-rip-1]version 2
[AR3-rip-1]network 13.0.0.0
[AR3-rip-1]network 34.0.0.0
[AR3-rip-1]network 35.0.0.0
配置r4
[r4-GigabitEthernet0/0/0]ip address 34.0.0.4 24
[r4-GigabitEthernet0/0/1]ip address 100.1.1.254 24
[r4-GigabitEthernet0/0/0]ip address 34.0.0.4 24
[r4-GigabitEthernet0/0/1]ip address 100.1.1.254 24
配置r5
[R5-GigabitEthernet0/0/0]ip address 35.0.0.5 24
[R5-GigabitEthernet0/0/1]ip address 56.0.0.5 24
[AR5]RIP 1
[AR5-rip-1]version 2
[AR5-rip-1]network 35.0.0.0
[AR5-rip-1]network 56.0.0.0
配置r6
[AR6-GigabitEthernet0/0/1]ip address 172.16.1.254 24
[AR6-GigabitEthernet0/0/0]ip address 56.0.0.6 24
R6作为边界路由器还需要一条通往公网的缺省路由
[AR6]ip route-static 0.0.0.0 0 56.0.0.5
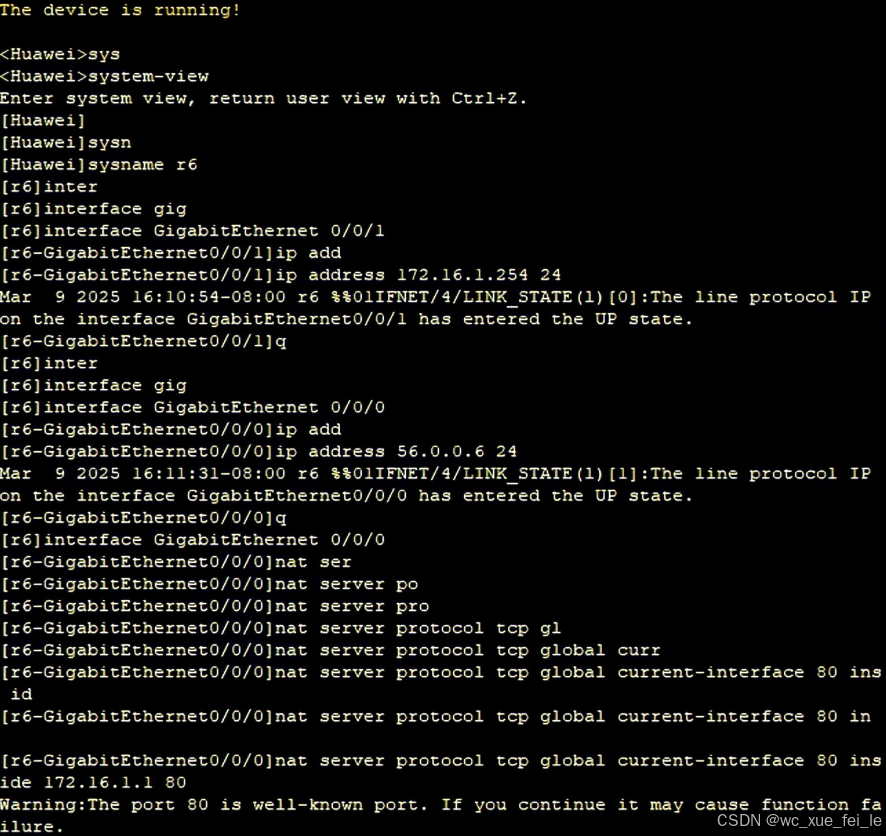
端口映射
R6边界路由器需要用NAT动态转换与端口映射
[AR6-GigabitEthernet0/0/0]nat server protocol tcp global current-interface 80 ins
ide 172.16.1.1 80
[AR6]acl 2000
[AR6-acl-basic-2000]rule permit source 172.16.1.0 0.0.0.255
[AR6-GigabitEthernet0/0/0]nat outbound 2000

对PC1和PC2进行DHCP的配置
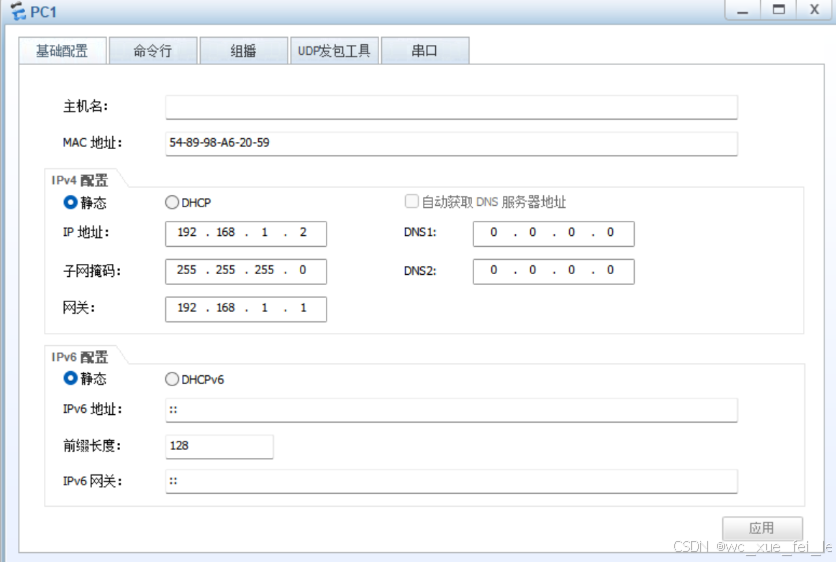
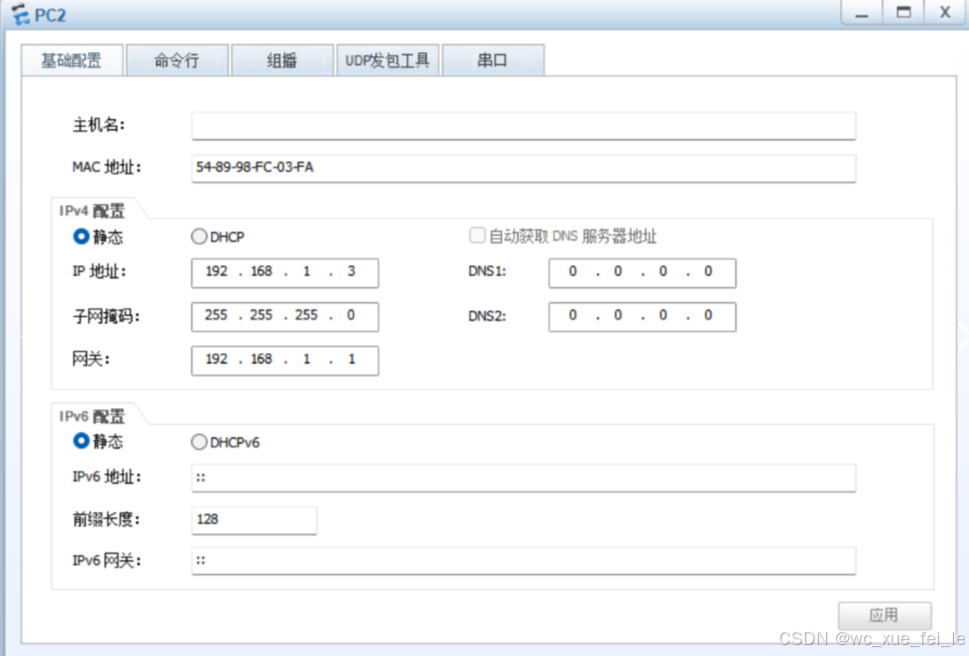
首先先启用DHCP
然后再PC1和PC2分别进行Ping

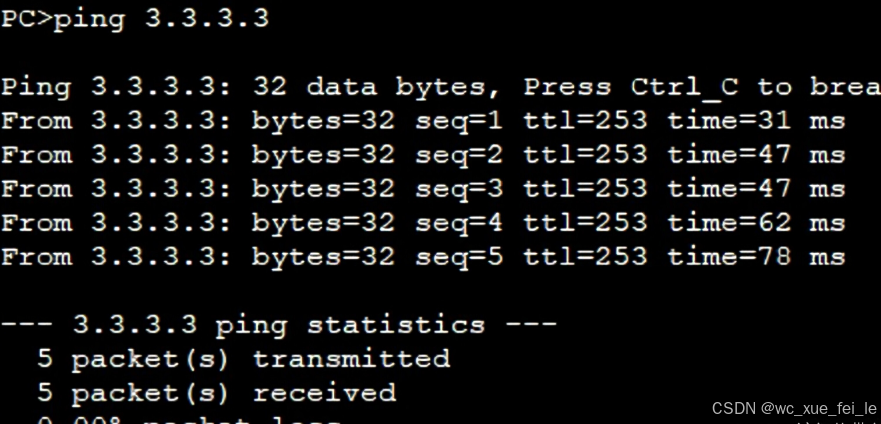
PC1可以正常访问3.3.3.3
要使PC2访问不了dns,则需要下列操作
客户端域名访问服务器
配置DNS
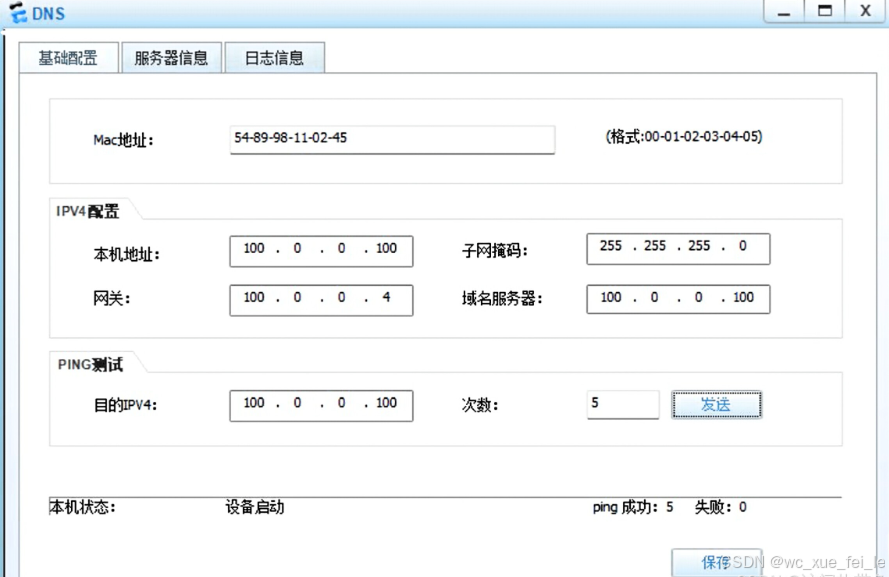
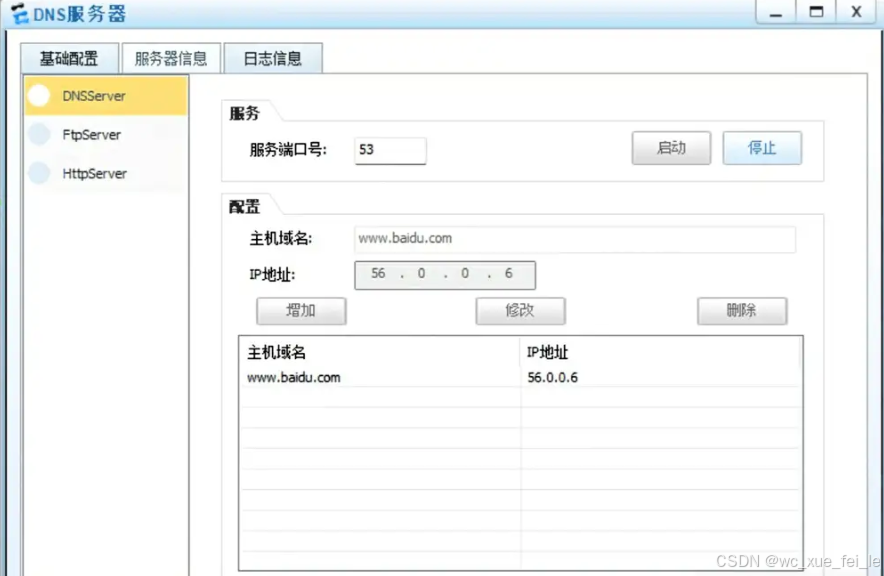

五、实验感悟
这次实验要设置三个网络区域,分别是学校网络、运营商网络和百度网络,会用到六个路由器。首先,在这六个路由器里,我们要对AR1和AR2这两个路由器,按照学校内部的网段192.168.1.0/24来进行网络划分,然后设置访问控制列表(ACL)。设置完之后,PC1就能正常访问3.3.3.0/24这个网段了,但PC2不能访问.
在学校网络这边,我们用静态路由的方式来配置。有两条链路,通过管理距离(AD)设置成浮动静态路由,这样一来,要是主链路出问题不能用了,备份链路就会自动开始工作。
对于运营商网络,需要用动态路由协议,具体就是开放最短路径优先(OSPF)协议,还要设置路由器标识(Router-ID)。
最后,我们要让AR1这个路由器能被远程控制,也就是通过telnet实现。先建立AR1的远程连接,设置好账号和密码进行验证,开启AAA认证,再创建一个新用户。在控制的那一端,用telnet通过这个新用户来管理AR1,这样就能实现对AR1的远程控制了。

















 469
469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









