




 本文详细介绍如何使用ELK堆栈收集、解析和可视化nginx日志。从json化nginx日志,到安装配置filebeat,再到logstash的高级配置及kibana索引管理,一步步实现高效日志处理。
本文详细介绍如何使用ELK堆栈收集、解析和可视化nginx日志。从json化nginx日志,到安装配置filebeat,再到logstash的高级配置及kibana索引管理,一步步实现高效日志处理。
前面已经搭建好了ELK的基础环境,现在我们可以开始收集日志了,那就从收集nginx日志开始吧。
一、把nginx日志json化
收集nginx日志之前,最好是把nginx的日志格式给json化,这样可以大大的方便我们收集和查看日志。
修改nginx的配置文件,增加json日志格式。
log_format access_json '{"clientip":"$remote_addr",'
'"remoteuser":"$remote_user",'
'"timestamp":"$time_local",'
'"host":"$server_addr",'
'"request":"$request",'
'"status":"$status",'
'"size":"$body_bytes_sent",'
'"referer":"$http_referer",'
'"useragent":"$http_user_agent",'
'"xff":"$http_x_forwarded_for",'
'"responsetime":"$request_time",'
'"upstreamaddr":"$upstream_addr",'
'"upstreamtime":"$upstream_response_time",'
'"upstreamstatus":"$upstream_status",'
'"contenttype":"$http_content_type",'
'"authorization":"$http_authorization",'
'"requestSource":"$http_requestSource",'
'"mobileName":"$http_mobileName",'
'"mobileSystem":"$http_mobileSystem",'
'"systemVersion":"$http_systemVersion",'
'"appVersion":"$http_appVersion",'
'"upstreamcachestatus":"$upstream_cache_status"}';
并在下面的access_log中调用access_json
access_log logs/access.log access_json;
修改完成之后,reload一下nginx,这个json日志格式就生效了。
二、安装filebeat
就像之前的elk一样,客户端服务器上的filebeat也放到/usr/local/elkstack/这个目录下,并用elkstack这个用户启动。
[root@log1 ~]# useradd elkstack
[root@log1 ~]# mkdir -p /usr/local/elkstack
下载filebeat的tar包,解压
[root@log1 ~]# cd /usr/local/elkstack
[root@log1 elkstack]# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.4.0-linux-x86_64.tar.gz
[root@log1 elkstack]# tar -zxf filebeat-7.4.0-linux-x86_64.tar.gz
修改配置文件
[root@log1 ~]# cat /usr/local/elkstack/filebeat-7.4.0-linux-x86_64/filebeat.yml | grep -Ev '^$|^#'
filebeat.inputs:
- type: log
enabled: true
paths:
- /data/logs/nginx/access.log
fields:
log_topics: nginx-log
logtype: nginx-access
output.kafka:
enabled: true
hosts: ["192.168.0.141:9092","192.168.0.142:9092","192.168.0.143:9092"]
topic: '%{[fields][log_topics]}'
用filebeat来收集日志,并输出到kafka中相应的topic中。
paths用来指定要收集的日志的路径
fields增加两个字段:
- log_topics:该日志输出到kafka中的topic名称。
- logtype:给该日志增加一个type属性,在后面的日志筛选、过滤的过程中可以更好的做区分。
创建日志目录
[root@log1 ~]# mkdir -p /data/filebeat7/logs
[root@log1 ~]# chown -R elkstack:elkstack /data/filebeat7
启动filebeat
[root@log1 ~]# chown -R elkstack:elkstack /usr/local/elkstack/filebeat-7.4.0-linux-x86_64
[root@log1 ~]# su - elkstack
[elkstack@log1 ~]$ cd /usr/local/elkstack/filebeat-7.4.0-linux-x86_64
[elkstack@log1 ~]$ nohup ./filebeat -e -c filebeat.yml >> /data/filebeat7/logs/filebeat_nohup.log &
三、配置、启动logstash
之前在安装logstash的时候,我是没启动logstash的。现在到了收集nginx日志的阶段,用filebeat收集完nginx日志,传到kafka中,再由logstash去kafka相应的topic中取出日志内容,并做我们想要的过滤、筛选等等处理。
由于这里只收集一个nginx的日志,所以我这里只需要写一个配置文件。启动logstash的时候,直接指定这个配置文件就行。但是如果是收集多个日志文件,需要写多个配置文件的时候呢?这个时候我们可以创建一个目录专门用于放各种日志的配置文件,启动的时候指定这个目录即可,它下面的配置文件都会生效,这里虽然只是一个配置文件,但还是创建一个目录吧,这样清楚点。
[elkstack@node1 ~]$ cd /usr/local/elkstack/logstash-7.4.0
[elkstack@node1 ~]$ mkdir conf.d
编写nginx日志的logstash配置文件
[elkstack@node1 ~]$ cat /usr/local/elkstack/logstash-7.4.0/conf.d/nginx-access.conf
input {
kafka {
bootstrap_servers => "192.168.0.141:9092,192.168.0.142:9092,192.168.0.143:9092"
group_id => "logstash-group"
topics => "nginx-log"
auto_offset_reset => "latest"
consumer_threads => 5
decorate_events => true
codec => json
}
}
filter {
if [fields][logtype] == "nginx-access" {
json {
source => "message"
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
}
geoip {
source => "clientip"
target => "geoip"
}
mutate {
convert => [ "size","integer" ]
convert => [ "responsetime","float" ]
convert => [ "upstreamtime","float" ]
}
}
}
output {
if [fields][logtype] == "nginx-access" {
elasticsearch {
hosts => ["192.168.0.141:9200","192.168.0.142:9200","192.168.0.143:9200"]
index => "logstash-nginx-access.log-%{+YYYY.MM.dd}"
}
}
}
1.如果收集的是json格式的日志,则在logstash的input的kafka中需要加入codec => json,不然整个日志会作为文本展示在"message"这个字段中。
2.在收集nginx的日志的时候,可以用logstash中的filter插件中的data来匹配$time_local的日志时间格式,这个匹配真的是实验了很久,替换@timestrap时间为日志的生成时间而不是处理时间。或者,在定义nginx日志格式的时候,直接用$time_iso8601来替代$time_local,因为$time_iso8601这个时间格式比较好匹配(其实一样啦,只是我刚开始不知道$time_local的正则匹配怎么写而已)
参考文章:https://blog.youkuaiyun.com/jianblog/article/details/54585043
3.logstash多个配置文件,需要做区分,比如用在input中用type做区分,然后在filter和output中用type来做判断。不然同一个日志,有几个output就会重复几次。
参考地址:https://blog.youkuaiyun.com/qq_24879495/article/details/78009562
4.logstash 修改配置文件不重启 ./bin/lagstash -f configfile.conf --config.reload.automatic
参考地址:https://www.cnblogs.com/smail-bao/p/8675341.html
5.在使用geoip插件的时候,不用再去下载数据文件了,因为已经包含在logstash的包内了。具体的位置在/usr/local/elkstack/logstash-7.4.0/vendor/bundle/jruby/2.5.0/gems/logstash-filter-geoip-6.0.3-java/vendor/GeoLite2-City.mmdb,只是未必是最新的,最新的可以去官网下载<https://dev.maxmind.com/geoip/geoip2/geolite2/>
6.在用geoip插件进行地图展示的时候,报错说没有geo_point类型的字段。nginx的索引名称必须为logstash-*才会应用默认模板,默认模板的location字段的类型是geo_point。
参考文章:https://blog.youkuaiyun.com/yanggd1987/article/details/50469113
7.在nginx日志字段中,我要把"size" => "integer","responsetime" => "float","upstreamtime" => "float",但是在kibana中看到的还是string类型,如果需要转类型,需要重新把索引删除之后再重新创建。
参考文章:https://blog.51cto.com/tianshili/1946507?utm_source=oschina-app
启动logstash
[elkstack@node1 ~]$ nohup logstash -f /usr/local/elkstack/logstash-7.4.0/conf.d/ >> /data/logstash7/logs/logstash_nohup.log &
四、在kibana中添加索引
logstash启动之后,就会从kafka中读取相关的日志内容,并进行过滤和筛选。
先在kibana中添加索引
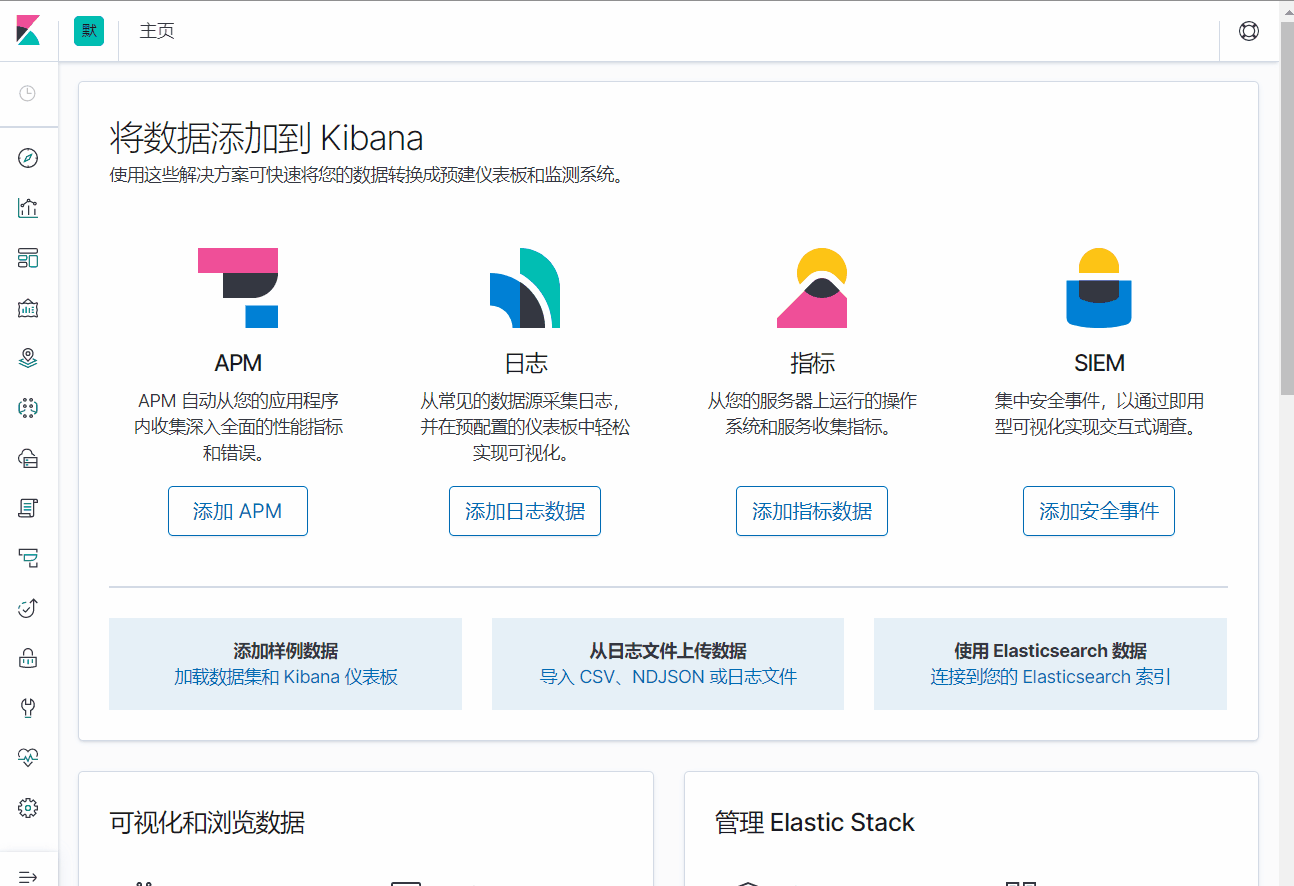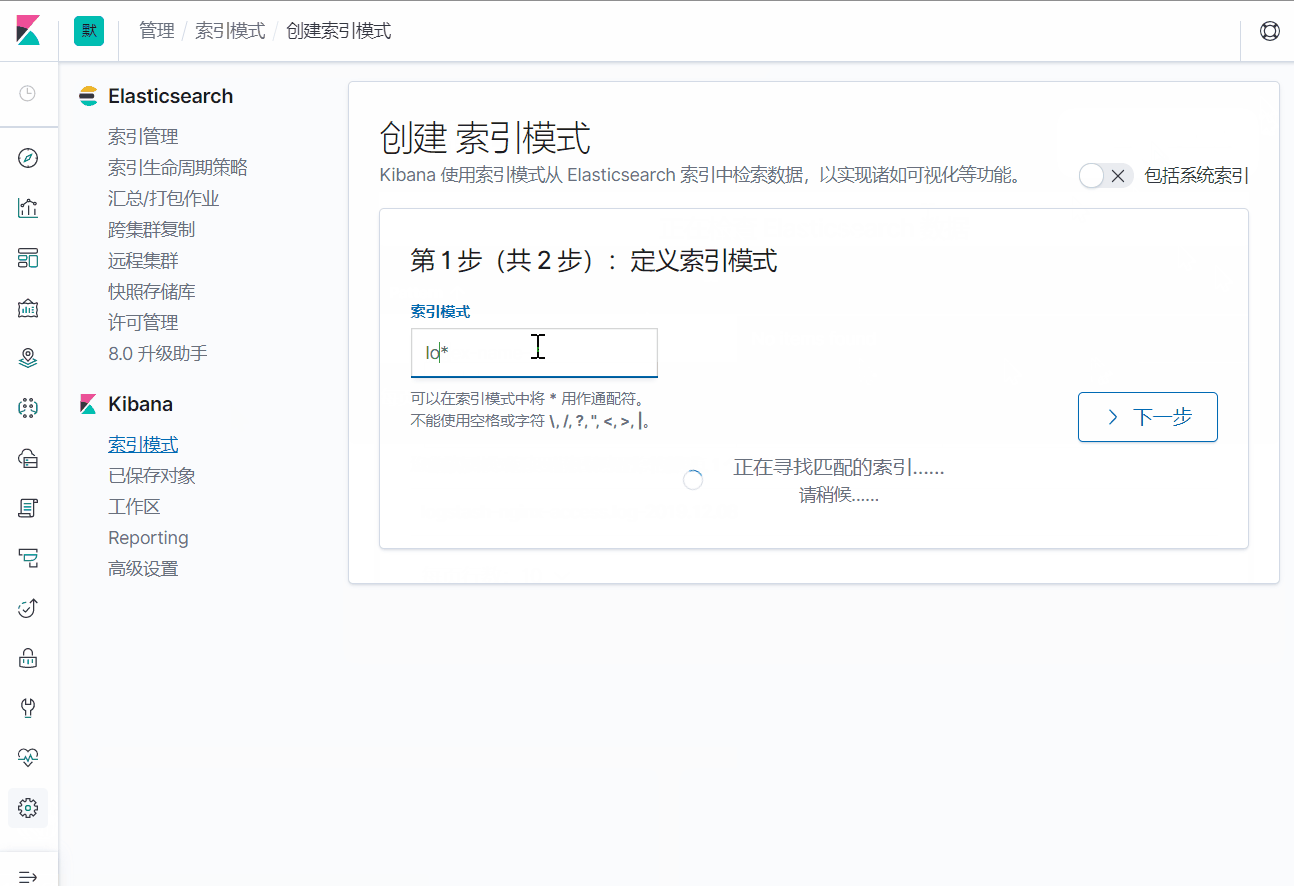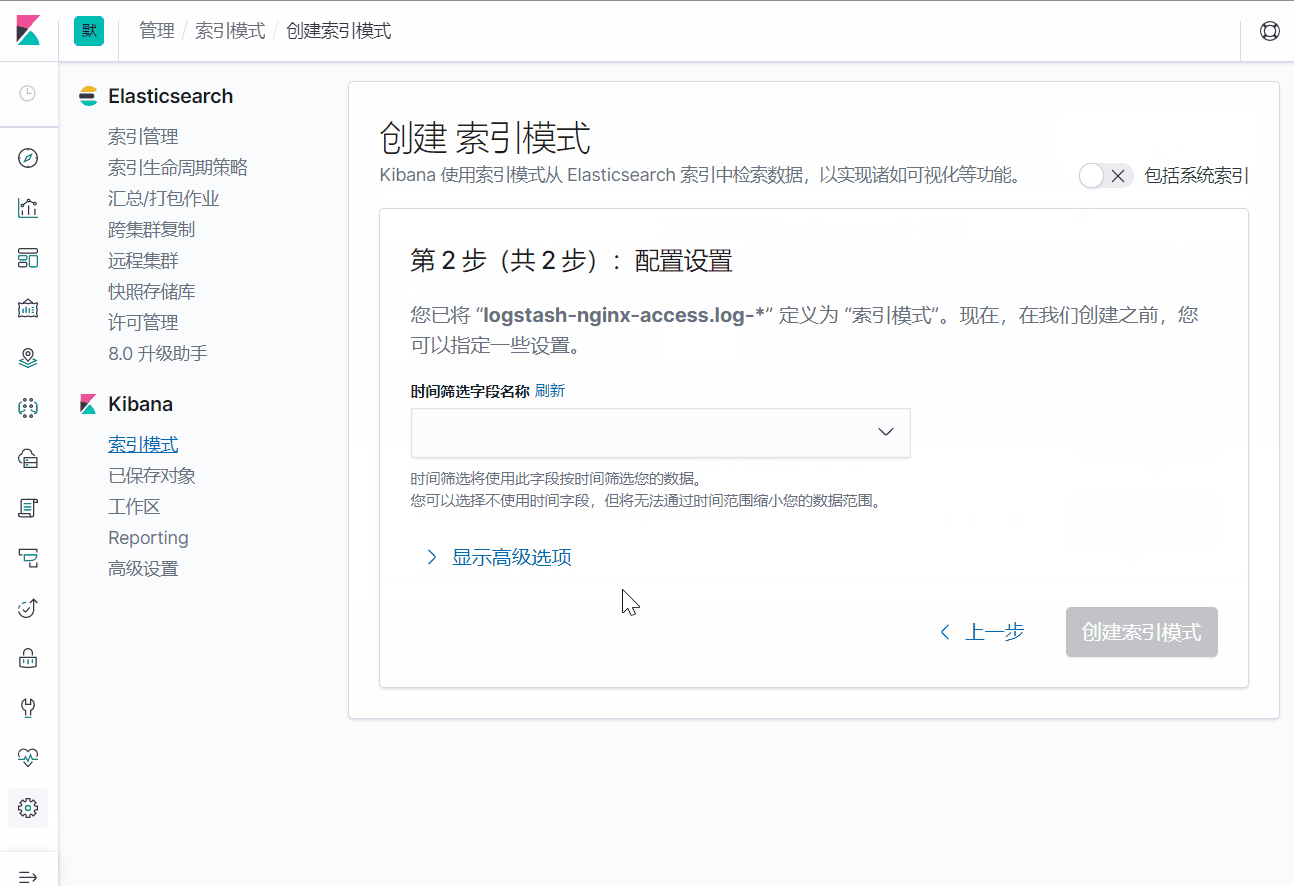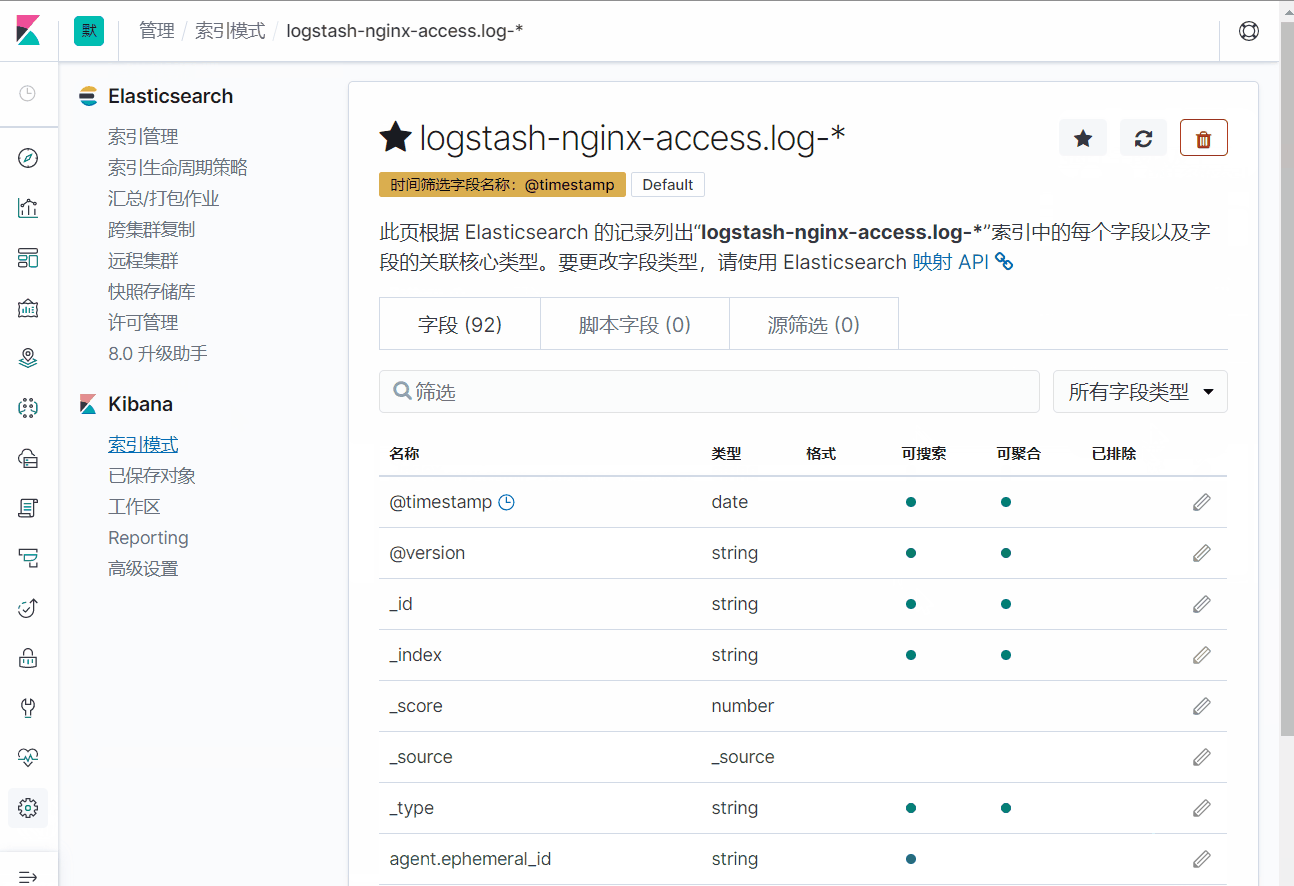
添加完索引之后,可以看到,这个索引中一共有92个字段。
注意:在kibana中创建索引的时候,需要添加"Time",不然查看日志的时候就只有_source没有Time。
然后进入到左上角的"Discover"中
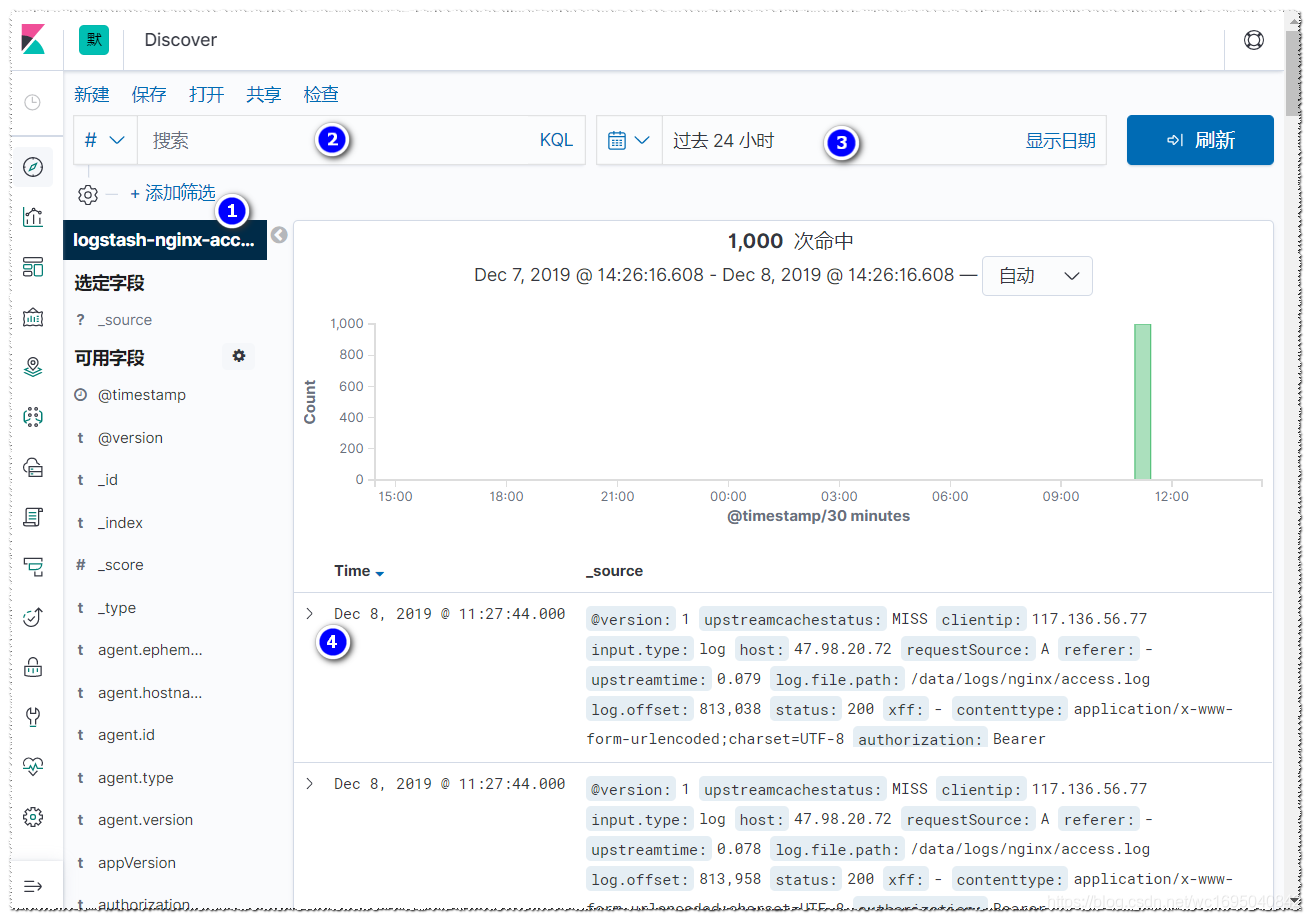
1,可以选择索引
2,可以根据关键字来搜索日志
3,可以选择日志的时间范围
4,可以查看这一条日志的具体内容,如下:
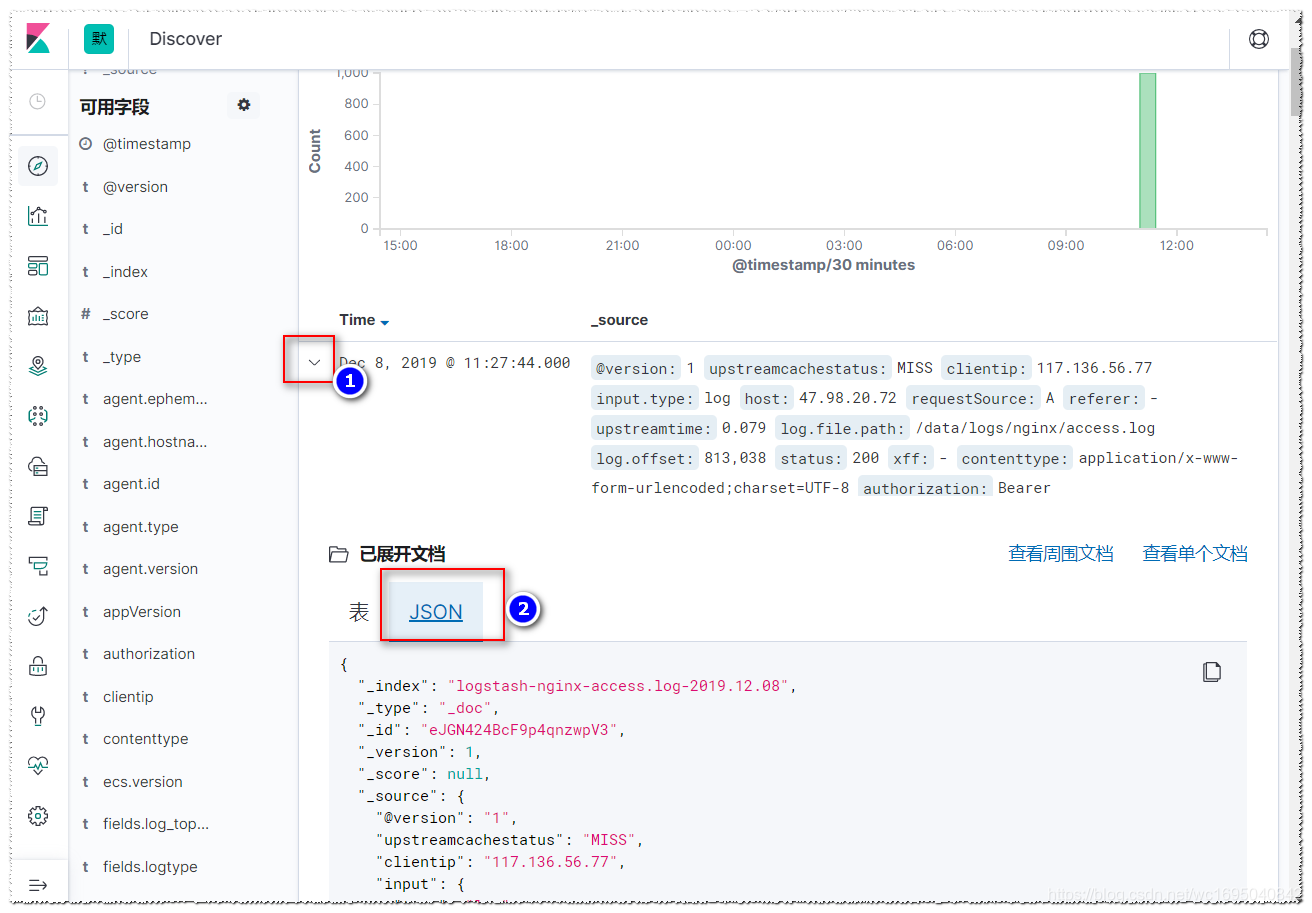
到这里,nginx的日志的收集已经完成,并且在kibana中能看到具体的日志内容。这些数据到底有什么用呢,之后在kibana中的绘图,就会展现出这些数据的作用。
参考文章:
https://blog.youkuaiyun.com/qq_24879495/article/details/78009562
https://www.cnblogs.com/smail-bao/p/8675341.html
https://www.bbsmax.com/A/MAzAyDOyz9/
https://blog.youkuaiyun.com/jianblog/article/details/54585043
https://blog.youkuaiyun.com/yanggd1987/article/details/50469113
https://blog.51cto.com/tianshili/1946507?utm_source=oschina-app
http://www.eryajf.net/2362.html

















 3410
3410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









