







 本文介绍了生成对抗网络(GAN)的基本思想,包括生成器和判别器的原理,以及对抗训练的过程。通过实例展示了如何使用GAN生成动漫头像,并分享了训练GAN的实用技巧,如更改样本标签、加入随机噪声等,以应对训练中的挑战。
本文介绍了生成对抗网络(GAN)的基本思想,包括生成器和判别器的原理,以及对抗训练的过程。通过实例展示了如何使用GAN生成动漫头像,并分享了训练GAN的实用技巧,如更改样本标签、加入随机噪声等,以应对训练中的挑战。
往期回顾:
07——深度模型中的优化
08——卷积网络
09——循环神经网络
之前学习了基本的深度学习与神经网络模型,让我们开始学习一些进阶的东西。个人对于生成对抗网络很感兴趣,就学习它吧。(主要参考李宏毅的GAN教程,以及其他一些博客)
生成对抗网络(Generative Adversial Network, GAN) ,是很有创新性的一种模型。它提供了一种思想就是对抗训练,让两个或多个模型间互相促进,犹如自然选择一般进行进化。近年来有关 GAN 的应用越来越多,可以前往thisxdoesnotexist.com/,里面有许多有趣的项目。同时关于 GAN 的论文也越来越多: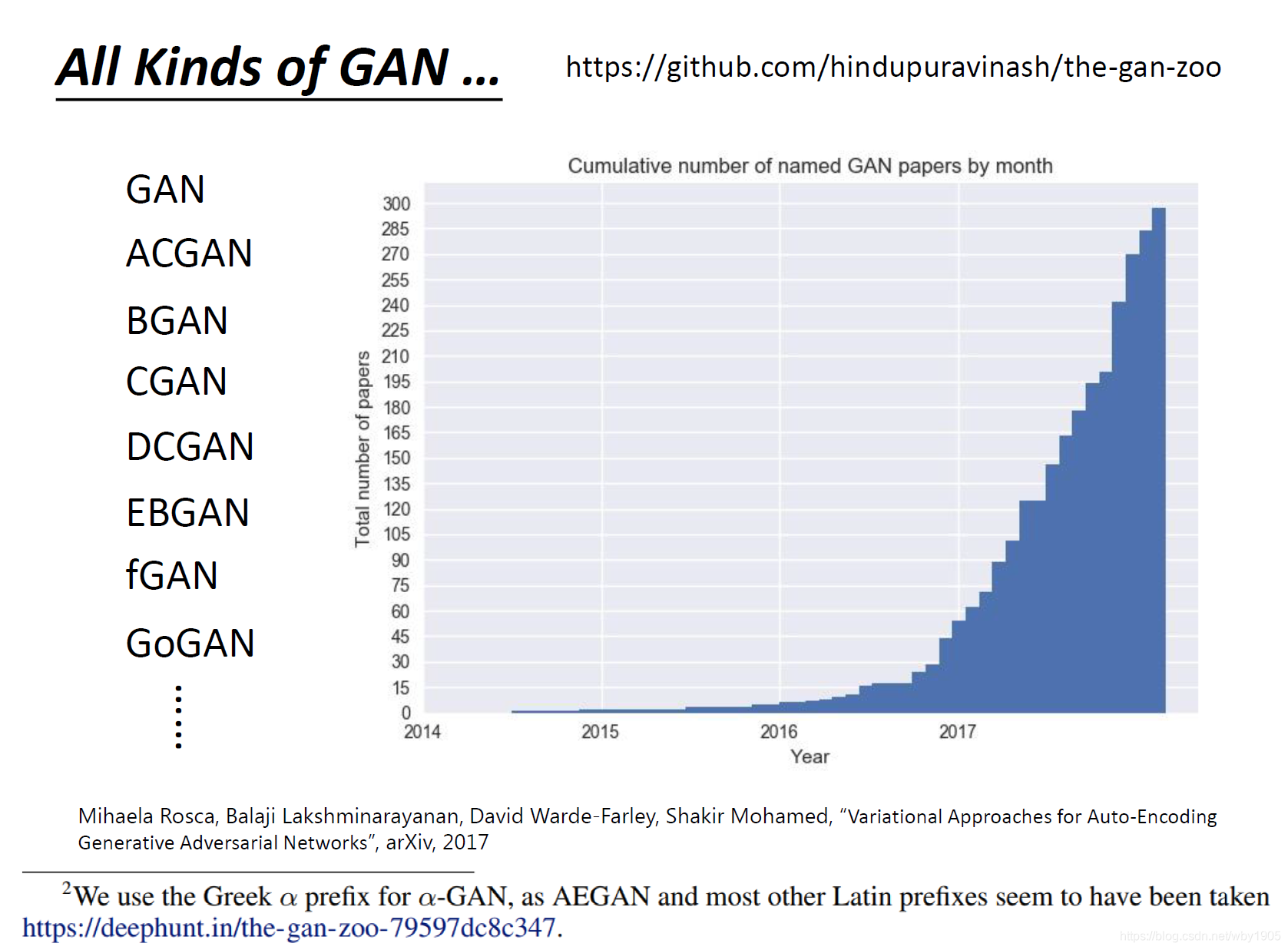
甚至在“GAN”前加上两个字母都有重复的名字(例如LSGAN), github 上有一个 the-gan-zoo 里面汇集了很多的 GAN 模型及论文。
随着 GAN 的研究不断发展,它不仅能够应用于图像生成,还能够生成文章,生成语音等等,总之 GAN 的应用可以充分发挥你的想象力。
这一节我们说一说最基本的 GAN 的思想并实现成二次元头像。
一、基本思想
GAN 主要由两部分组成:生成器(Generator) 和 判别器(Discriminitor)
1. 生成器
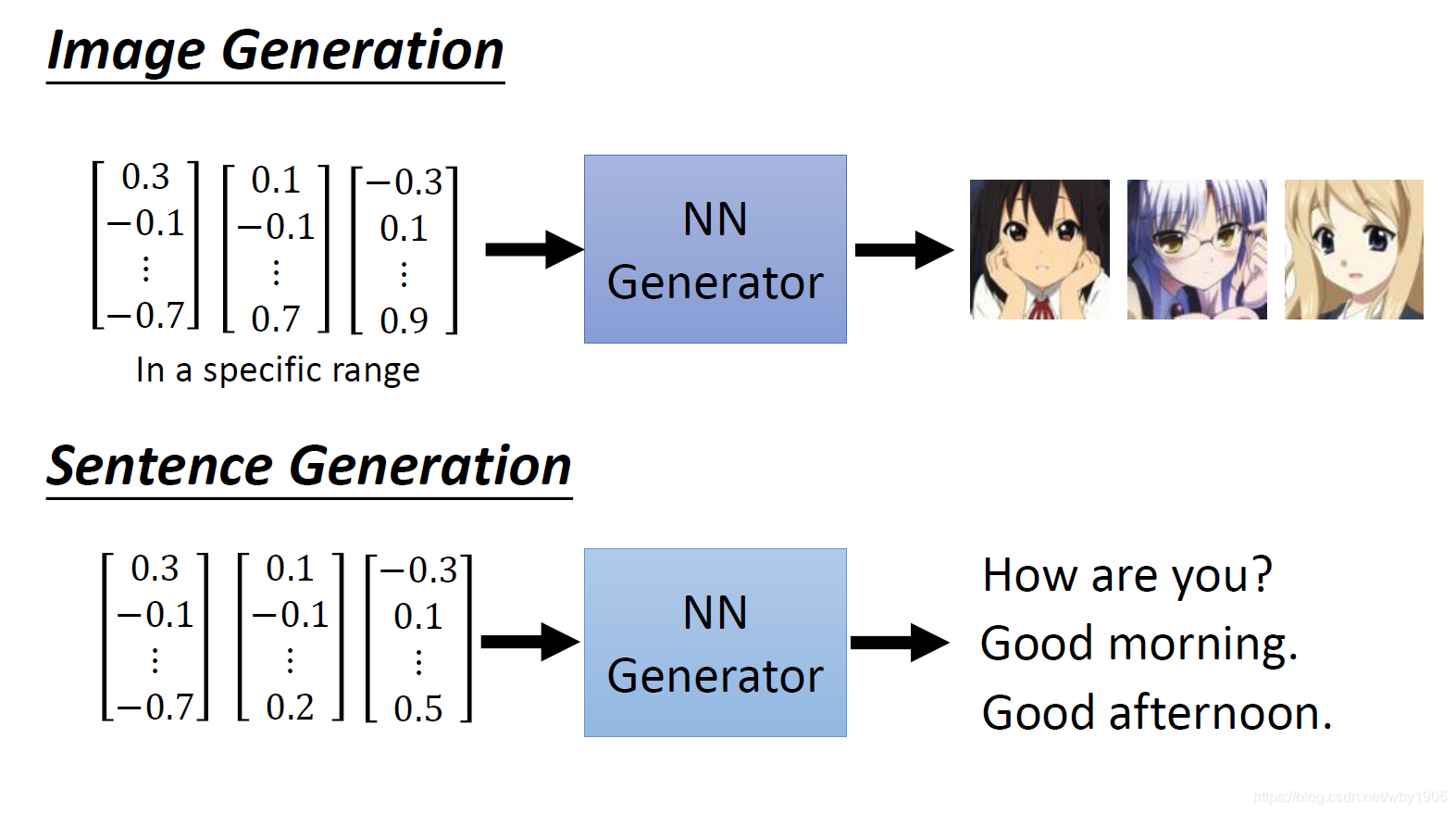
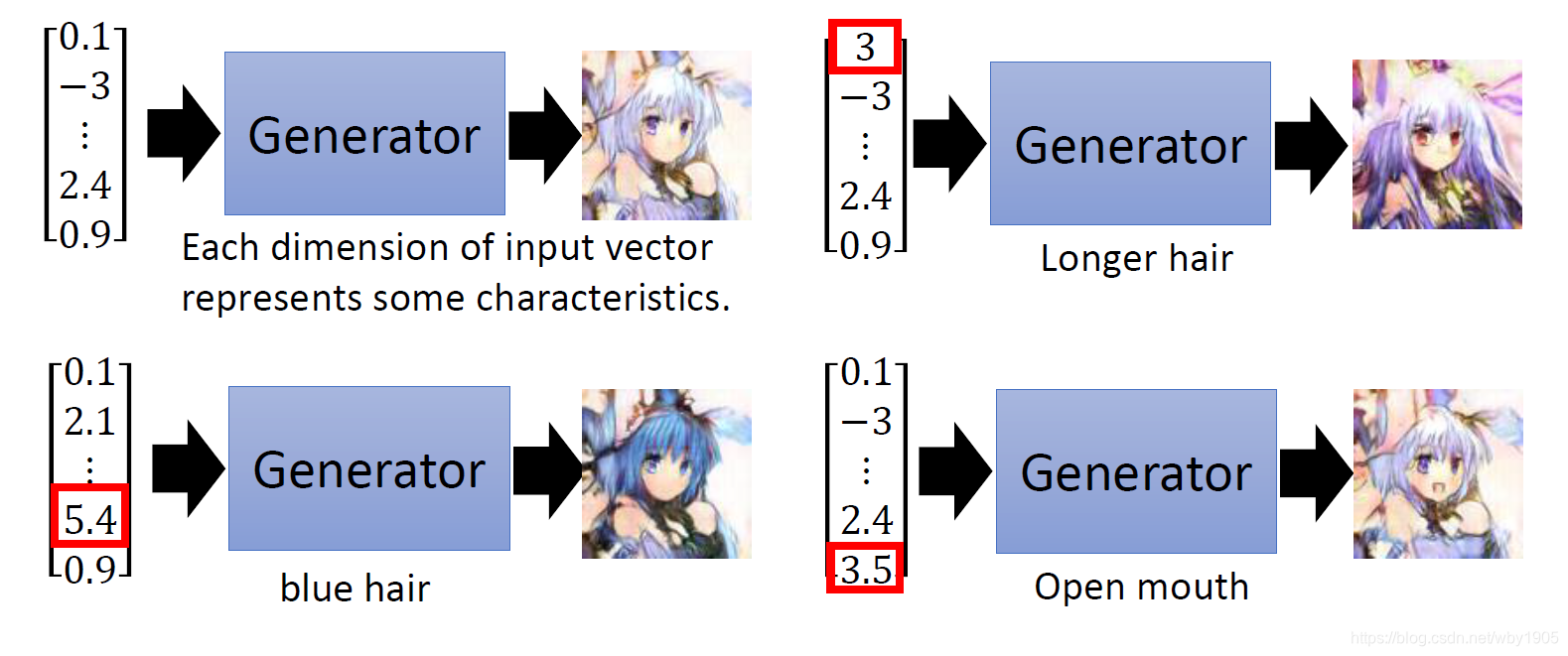
最基本的生成器的就是输入一些随机向量,然后它就可以生成一些对应的图片或是句子。向量的每个维度都代表了一些特征,譬如头发颜色,有无眼镜等等。
生成器本质上就是一个神经网络,它将特征值映射到目标任务上。
2. 判别器
判别器的作用就是分辨给定的图片或数据是来自真实数据分布生成的还是生成器所生成的假数据,它会给一个评分。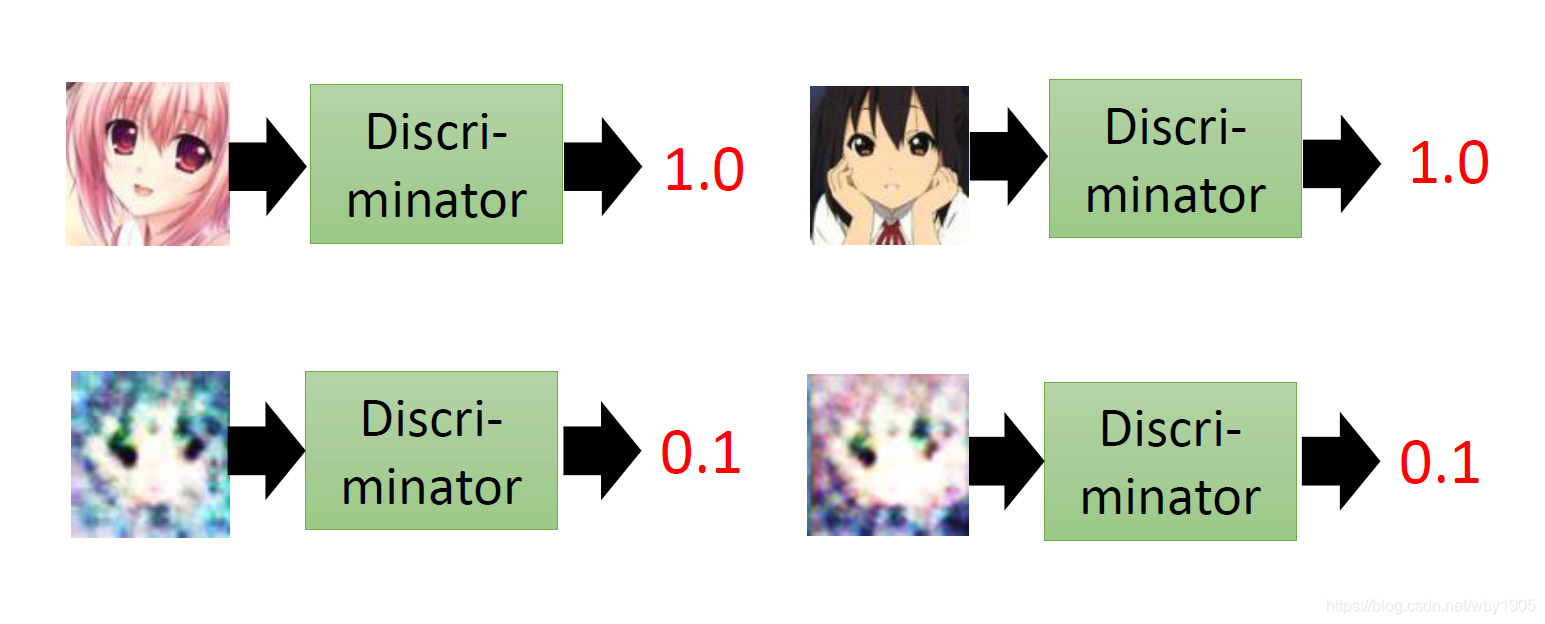
3. 对抗训练
生成器和判别器之间需要进行对抗训练,也就是说,生成器要尽可能“骗过”判别器,而判别器要尽可能识别出生成器的假样本。两者相互对抗,最后共同进化。
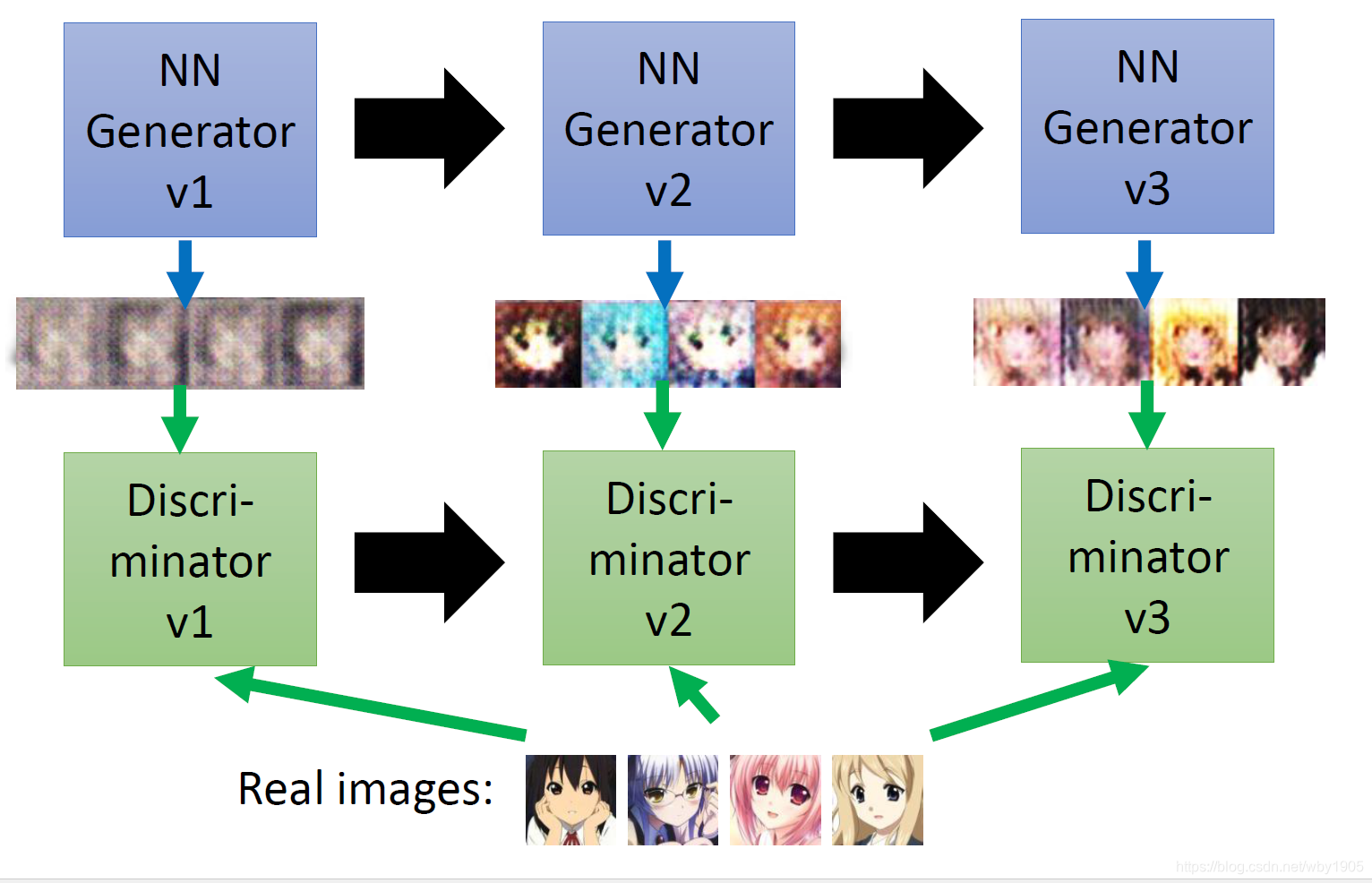
4. 训练过程
具体的训练过程如下:
在每个循环中:
- 首先我们需要从真实分布中采集出 m 个真实样本,给它们标为 1 (即表示为真实标签),同时随机生成 m 个向量,投入生成器中生成 m 个假样本记作 0 (即假标签)。
- 将真实标签的数据和假标签的数据都喂入判别器中,计算出它的 Loss ,并反向传播进行梯度优化。
- 固定住判别器的权重,然后将之前生成的假样本的标签改为 1 ,即对于生成器来说这种假样本在判别器中的真实性应该是越真实越好。然后重新喂入判别器中,进行反向传播梯度优化。
至于 Loss 的选择有许多,对于最基本的 GAN, 它采用了 BCELoss,即二类交叉熵损失。因此,具体过程如图:

二、对抗训练的好处
为什么需要对抗训练?为什么判别器或者生成器不能自主学习?让我们分情况说明。
1. 仅有生成器的学习
仅有生成器的学习思想与自编码器相当。我们可以依照 Auto-encoder 的训练过程进行训练,此时的 Decoder 可以看作是生成器。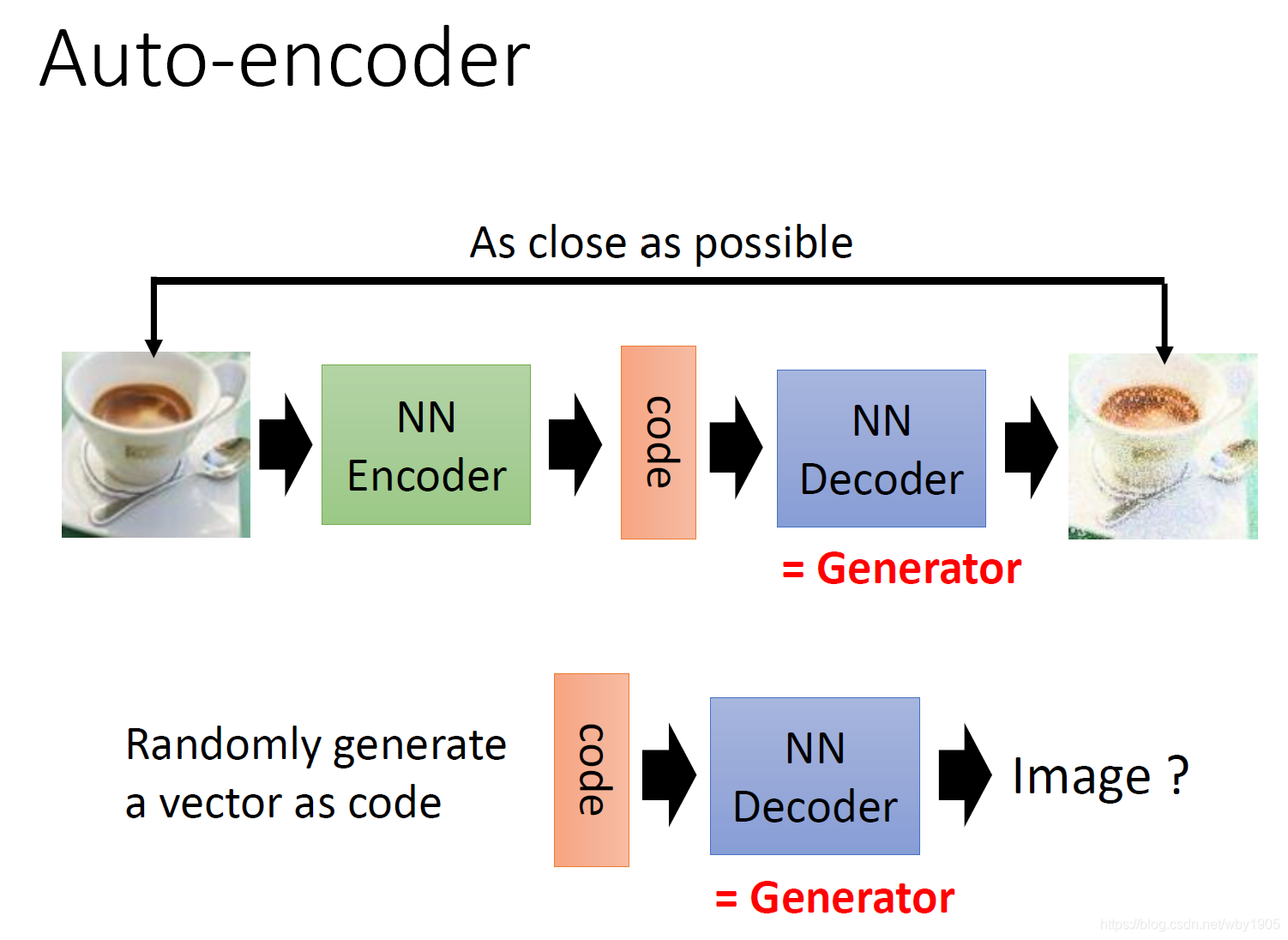
但是自编码器仅仅要求还原的图片与原图片尽可能像就行,而没有考虑到邻近像素间的差异(即人眼的感受)。例如对于目标
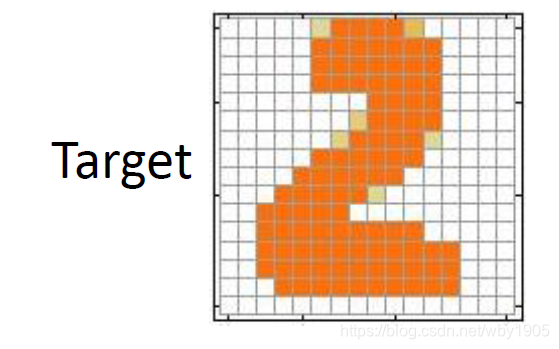
以下四个生成图前两个与原目标仅有一个像素的差异,后两个有六个像素差异,
然而直观来看,我们可以一眼就感觉出前两个生成的效果并不好。
自编码器并不能很好的考虑到邻近像素的相关性,可能需要很深的网络才可以,因此只有生成器并不能很好的完成生成任务,需要一个判别器帮助判断像素间是否符合直观感受。
2. 只有判别器的学习
如果我们有一个表现很好的判别器 D(x) 。我们可以解决以下的问题来实现生成:
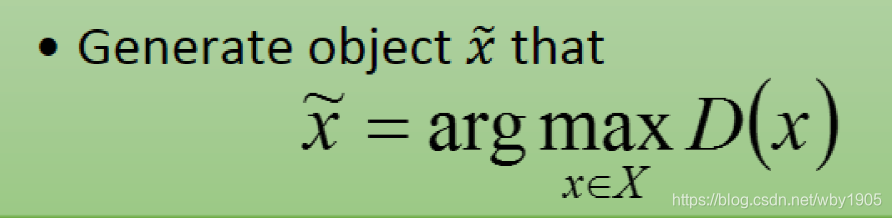
然而这需要我们列举出全部可能的x,这几乎是不可能的事情。
此外,即便我们可以列举出全部的 x ,但是由于来自于真实分布的数据必然全部都是真实的,不存在假的样本,因此我们无法去获取假的真实样本。
3. 生成器与判别器的结合才能各尽所能
生成器和判别器各有优缺点:

因此只有两者结合起来对抗训练才能互相补充,发挥特长。

如图。从判别器的角度来看,生成器事实上就是一种列举 x 的有效手段,并且可以产生出假的样本;同时从生成器的角度看,判别器可以帮助判断生成器生成的是否符合直观,可以注意到不同部分的关联。
三、GAN 实践:生成动漫头像
这里我使用 pytorch 简单地搭建了一个 DCGAN 网络,来实现生成一些二次元头像。(就是李宏毅课的作业 HW3-1,我还主要参考了torch官网的这篇教程)
首先让我们导入相关的库,设置一个 seed
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as op
import torch.utils.data as dat
import torch.backends.cudnn as cudnn
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
%matplotlib inline
# 设置 seed
seed = 2020
torch.manual_seed(seed)
接着定义一些超参数:
root : 数据存放地址
lr : 学习率
batch_size : 批量
input_size : 随机向量的长度
image_size : 图像的大小
epochs : 迭代次数
# 超参数
root = r'data'
lr = 0.0006
batch_size = 64
input_size = 256
image_size = 96
epochs = 10
读取数据
dataset = dset.ImageFolder(root,
transform=transforms.Compose([transforms.Resize((96,96)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5),
(0.5, 0.5, 0.5)),
]))
dataloader = dat.DataLoader(dataset,
shuffle=True,
batch_size=batch_size,
drop_last=True,
num_workers=2)
# 在 GPU 或者 CPU 上运行
device = torch.device("cuda:0" if (torch.cuda.is_available()) else "cpu")
我们可以检查一下数据:
real_batch = next(iter(dataloader))
plt.figure(figsize=(8, 8))
plt.axis("off")
plt.title("Training Images")
plt.imshow 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









