




 本文详述了ClickHouse分布式集群的部署、核心概念和测试,包括分片、副本、集群状态查询及故障恢复。通过停止节点服务、重启服务等操作验证了集群的高可用性和数据一致性。此外,还介绍了数据插入、数据库和表的创建,并提出了分区字段定义和分布式表规划的建议。
本文详述了ClickHouse分布式集群的部署、核心概念和测试,包括分片、副本、集群状态查询及故障恢复。通过停止节点服务、重启服务等操作验证了集群的高可用性和数据一致性。此外,还介绍了数据插入、数据库和表的创建,并提出了分区字段定义和分布式表规划的建议。
集群部署
核心概念:
集群
简单的理解,集群就是把多台计算机(服务器)拼凑在一起,它们相互合作和组合,在物理上构成了一个整体。
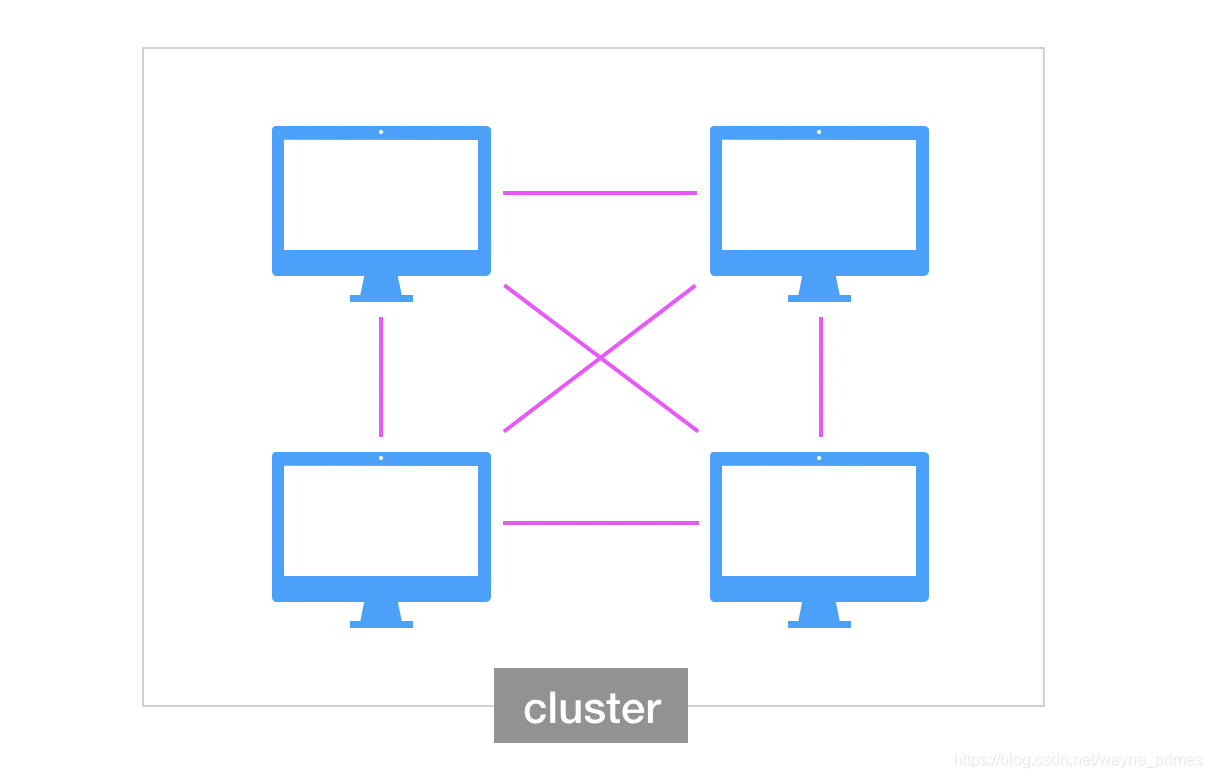
分布式
分布式的概念是相对于单个任务而言的,一个大任务或者复杂任务,将其按照一定的逻辑拆分成多个小任务,每个小任务单独处理,然后合并每个小结果成一个大结果。下面是一个简单的分布式架构示例:
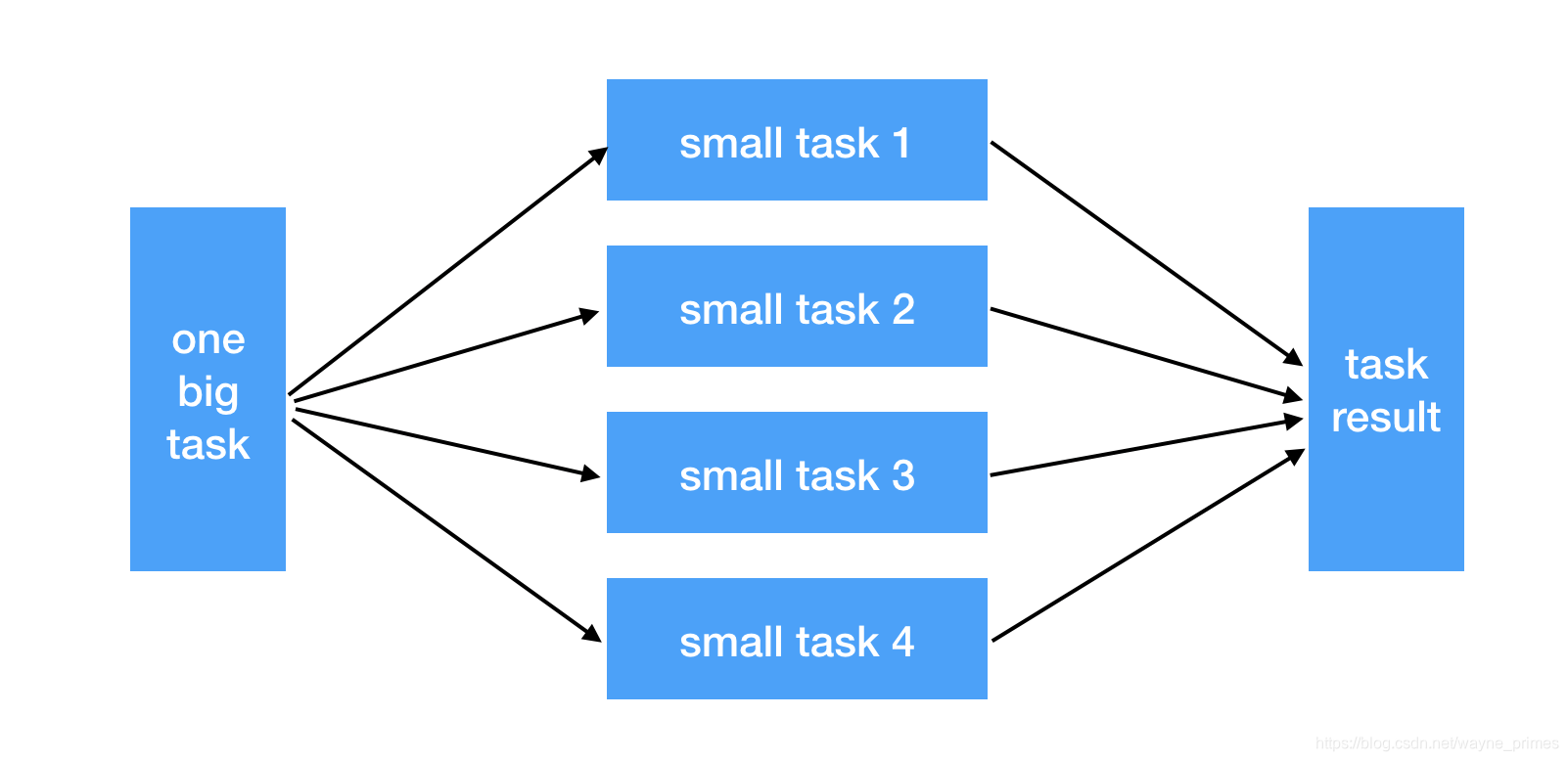
分布式集群
分布式集群兼以上三个特点而有之,能够处理大型任务,而且压榨计算性能。划重点如下
●多机器多任务处理
●每个单任务用分布式处理
●每个单机器内部实现并行计算
●分布式的文件系统
Clickhouse分布式集群规划
下面借助一个2*2分布式集群模型来厘清一些基本概念和定义:
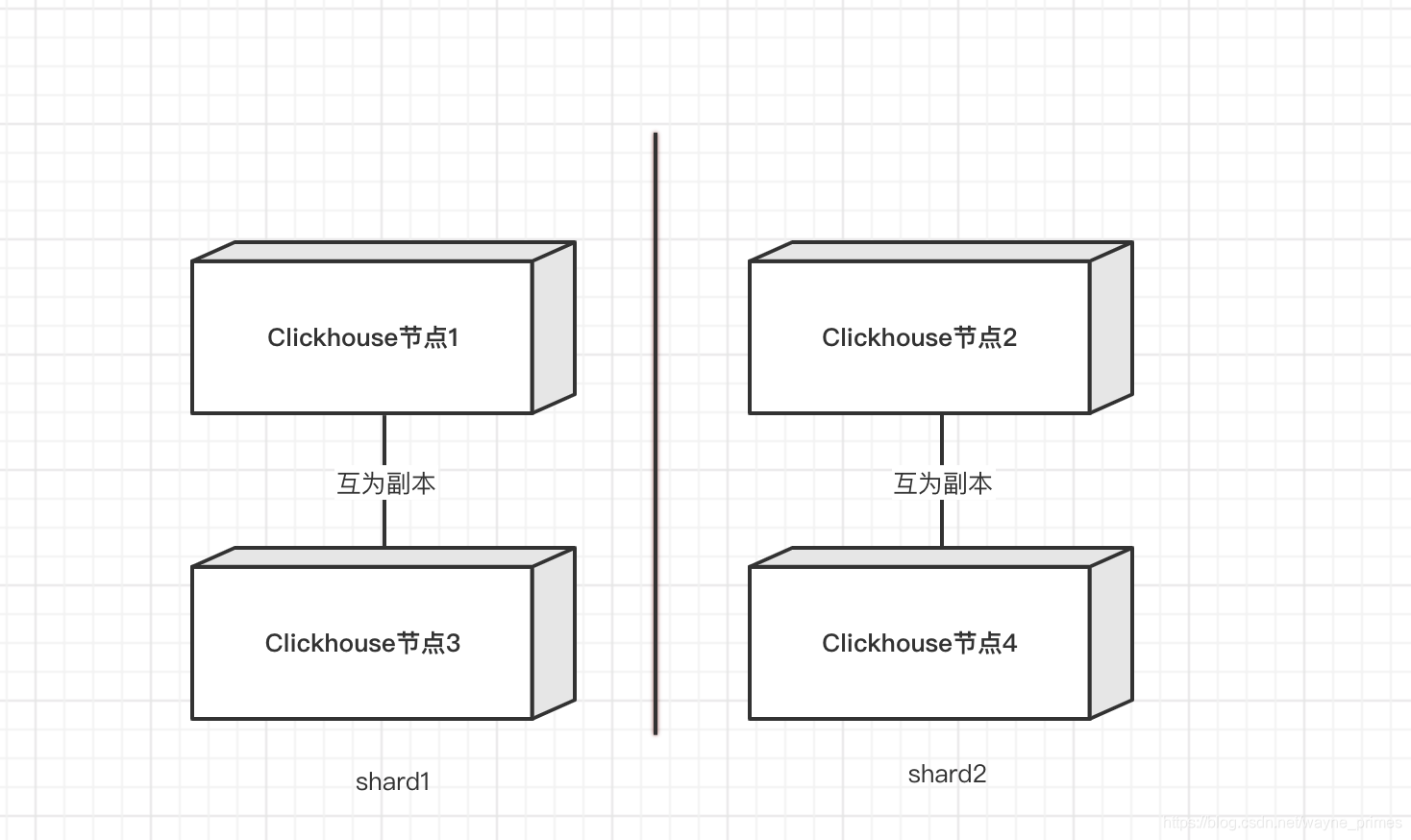
节点1和节点3互为备份数据、节点2和节点4互为备份数据
节点1和节点3为分片1、节点2和节点4为分片2
分片(shard):一个分片代表一组机器,分片内部各机器存储相同的数据(分布式文件系统),所有分片中的任一个想加起来等于完整的数据。集群的性能取决于分片的数量。各个分片可以具有不同的权重(比如说有的机器性能好存储空间大,那么可以权重设置高一点)。
节点(node):一个节点就是一台机器,上图就是一个2x2的有4个节点的分布式集群。
备份(replica):同一个分片内,各个节点互为备份,记住是互为备份,没有主次之分,因为他们是完全一模一样的,相互补位。任何时候,只要不发生故障,他们都是一模一样的,这叫同一性。上图中节点1、3, 节点2、4互为备份。
只要设置internal_replication为false,那么我们不需要任何其他的配置即可实现数据复制和同步。
个人观点
#一个副本为一个节点,节点只能是作为副本属于某一个分片
某书上的p210页
#一张表可以有多个分片,每个分片拥有自己的副本,节点只能是作为副本属于某一个分片。
某书上的p214页
#不同分片的数据不一致
某书上的p211页
只有使用了replicatedmergetree复制表系列引擎,才有应用副本的能力。,他通过zookper p211 比mregetree表增加了分布式协同的能
#distributed分布式表原理解析
某书上的p236页
#问题
p214和p232副本数量矛盾
常用命令
#创建数据库 默认引擎是Ordinary
create database if not exist db_name [engine = engine]
#不同的数据库之间复制表结构
create table if not exists new_db.table_name as default.table_name engine = tinylog
#查看集群状态
select * from system.clusters;
#查看分区信息
select partition_id,name,table,database,disk_name from system.parts;
#查看远端zookeeper
select name,value,czxid,mzxid from system.zookeeper where path='/clickhouse'
#查看自身节点的宏变量
select * from system.macros
#删除数据
alter table ck.point_data_replica DELETE WHERE point_code='EC01'
问题记录
查询集群状态时host_address为localhost
解决方案
查看metrika.xml配置文件中集群名称与config.xml中配置的incl属性下的集群名是否一致。
改为一致即可解决。
两个节点是否可以实现2个分片1个副本
解决方案
根据观点中不同分片数据不一致,而作为副本副本数据是同步的。我认为是没有实现意义的。不如实际1分片1副本来的实际。
目前1分片1副本共2节点集群已经搭建完成。接下来的问题主要是分布式表规划(主要是分片规则)、表结构筛选、分区字段定义(建议用时间),以及2分片1副本共4节点集群。
解决方案
# 为集群中的所有节点创建数据库ck_default
clickhouse-client -h ${ip} -u 用户名 --password 密码 --query "create database ck_default on cluster manyun_ch_cluster;"
# 创建本地local_table
list=(ck_default)
ip=172.16.0.18
user=用户名
password=密码
for i in ${list[@]};do
db_name=$i
echo "创建$i的本地表"
clickhouse-client -h ${ip} -u ${user} --password ${password} --query "
create table ${db_name}.point_data_local on cluster manyun_ch_cluster
(
device_guid String,
point_code String,
data_value Float64,
time DateTime,
device_type String
)
engine = ReplicatedMergeTree('/${db_name}/tables/{shard}/point_data_local', '{replica}')
partition by toYYYYMM(time)
ORDER BY (device_guid,point_code,time,device_type)"
echo "创建$i的分布式表"
clickhouse-client -h ${ip} -u ${user} --password ${password} --query "
create table ${db_name}.point_data on cluster manyun_ch_cluster
(
device_guid String,
point_code String,
data_value Float64,
time DateTime,
device_type String
)
engine = Distributed('manyun_ch_cluster', '${db_name}', 'point_data_local', toYYYYMM(time));"
done
集群可用性测试
4节点:A1:172.16.0.18
A2:172.16.0.20
B1:172.16.0.22
B2:172.16.0.23
A1和A2为1个分片1,互为副本
B1和B2为1个分片2,互为副本
当前分区表按YYYYMMDD数据分配,持续向集群中分区表插入数据。此时A1、A2中数据一致,B1、B2无数据
select count(*) from ck_test.point_data_local
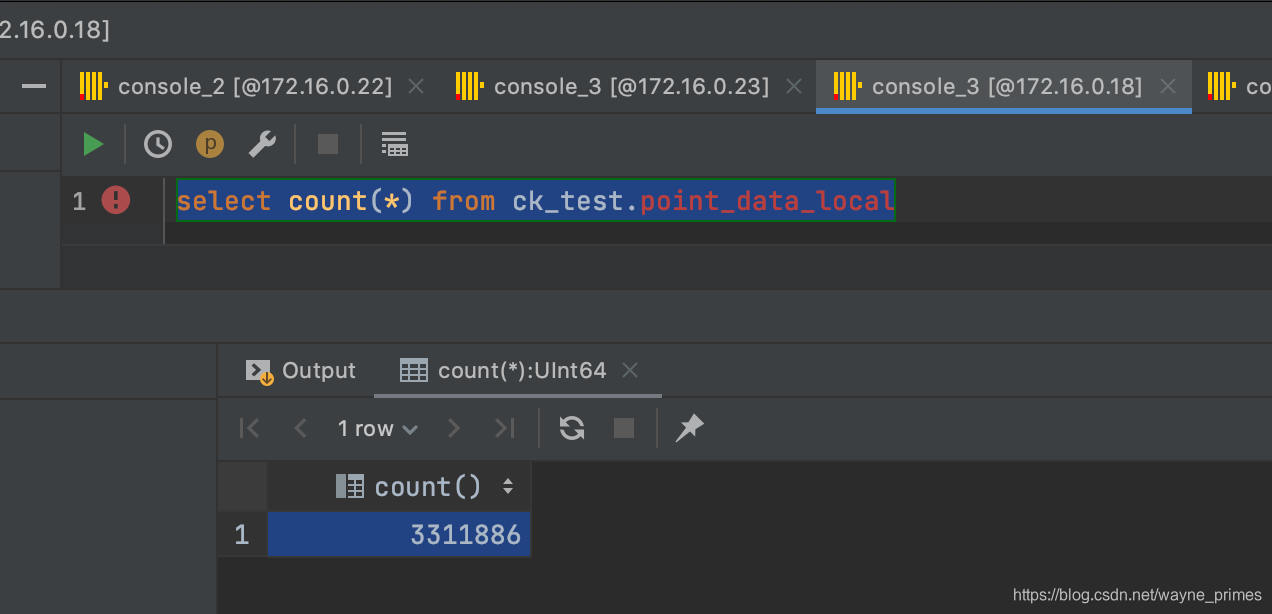
测试:停止A1 clickhouse服务,应用程序是否能正常工作
数据正常往A2插入。B1和B2中无数据,应用程序可以正常工作。
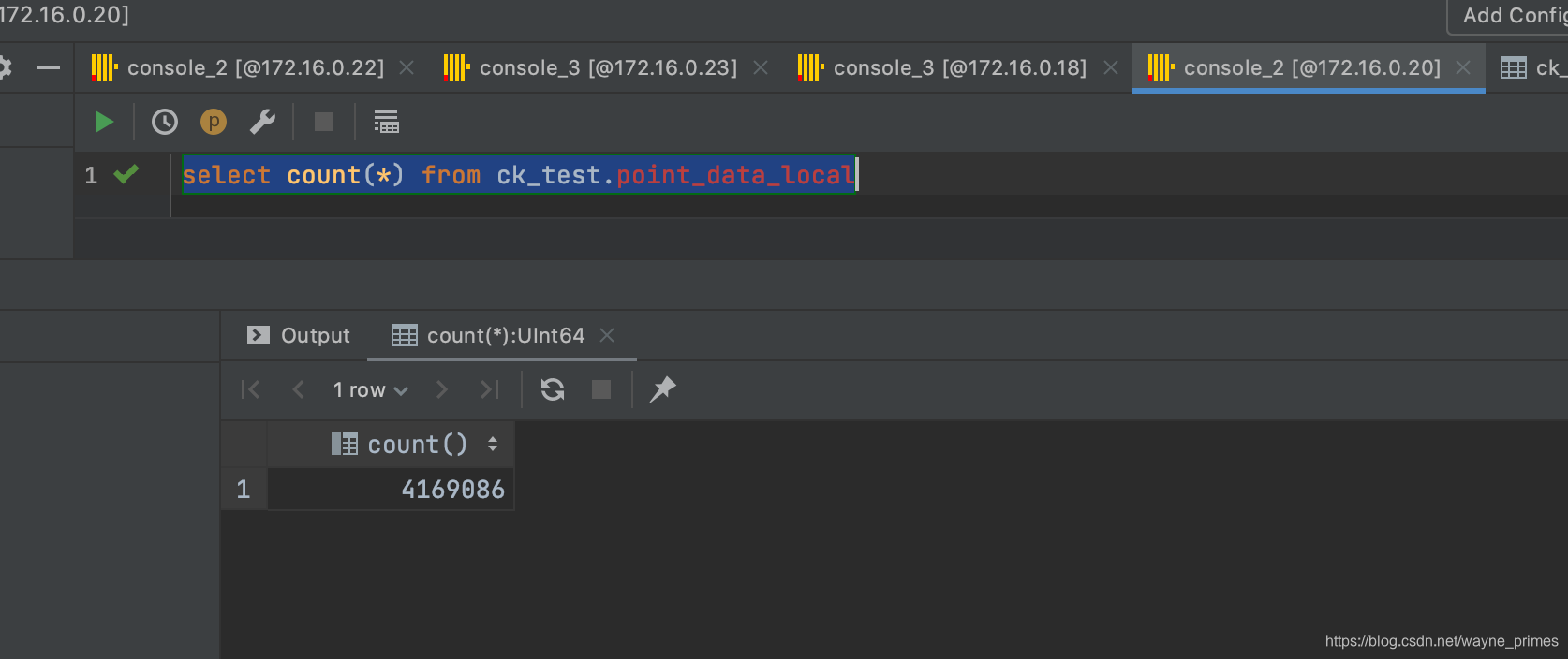
测试:重启A1 clickhouse服务,查看数据是否可以重新同步
十分钟后重启A1 clikhouse,查看数据,数据已同步A2
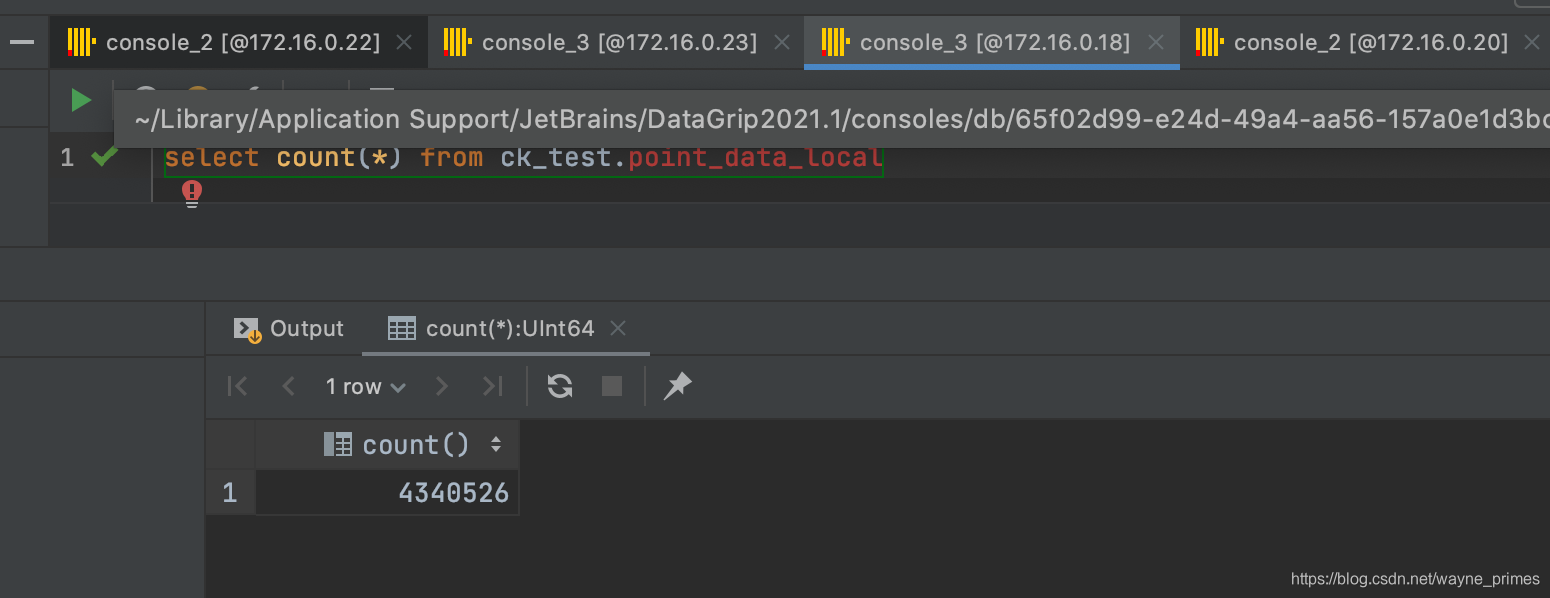
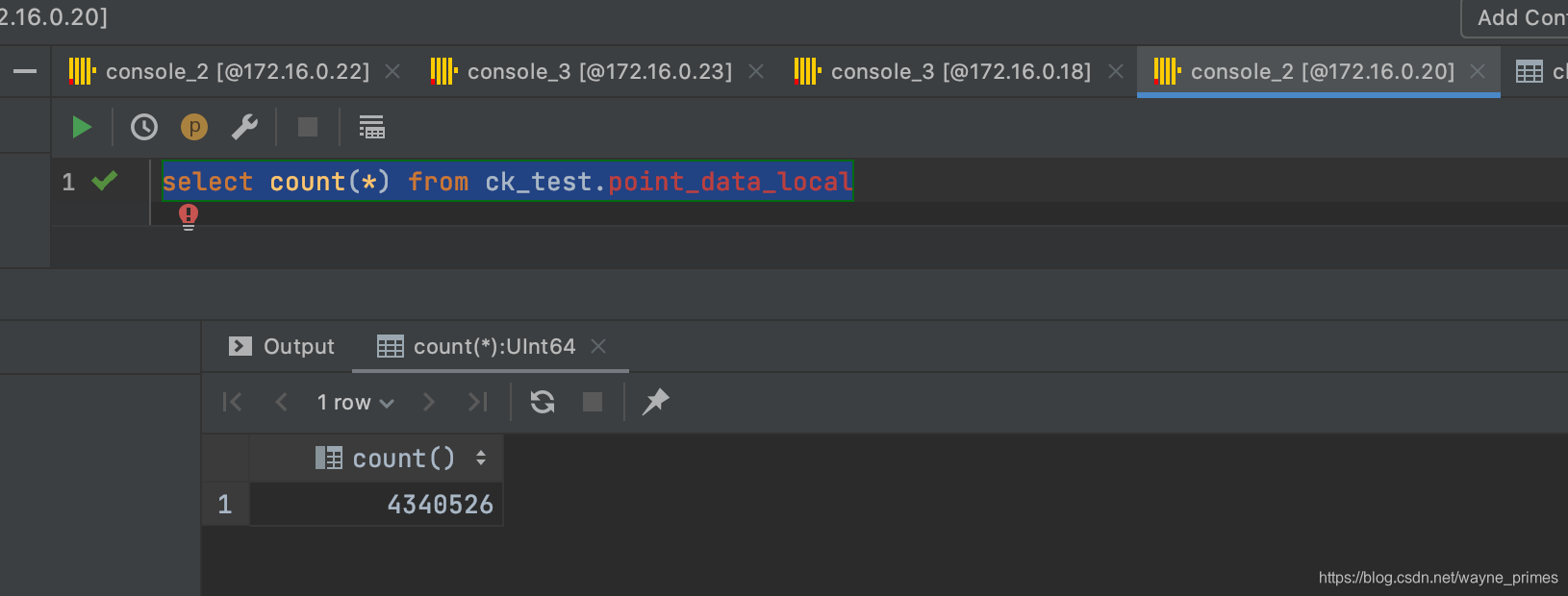
测试:停止分片1的clickhouse,测试是否会向分片2中的节点进行写入
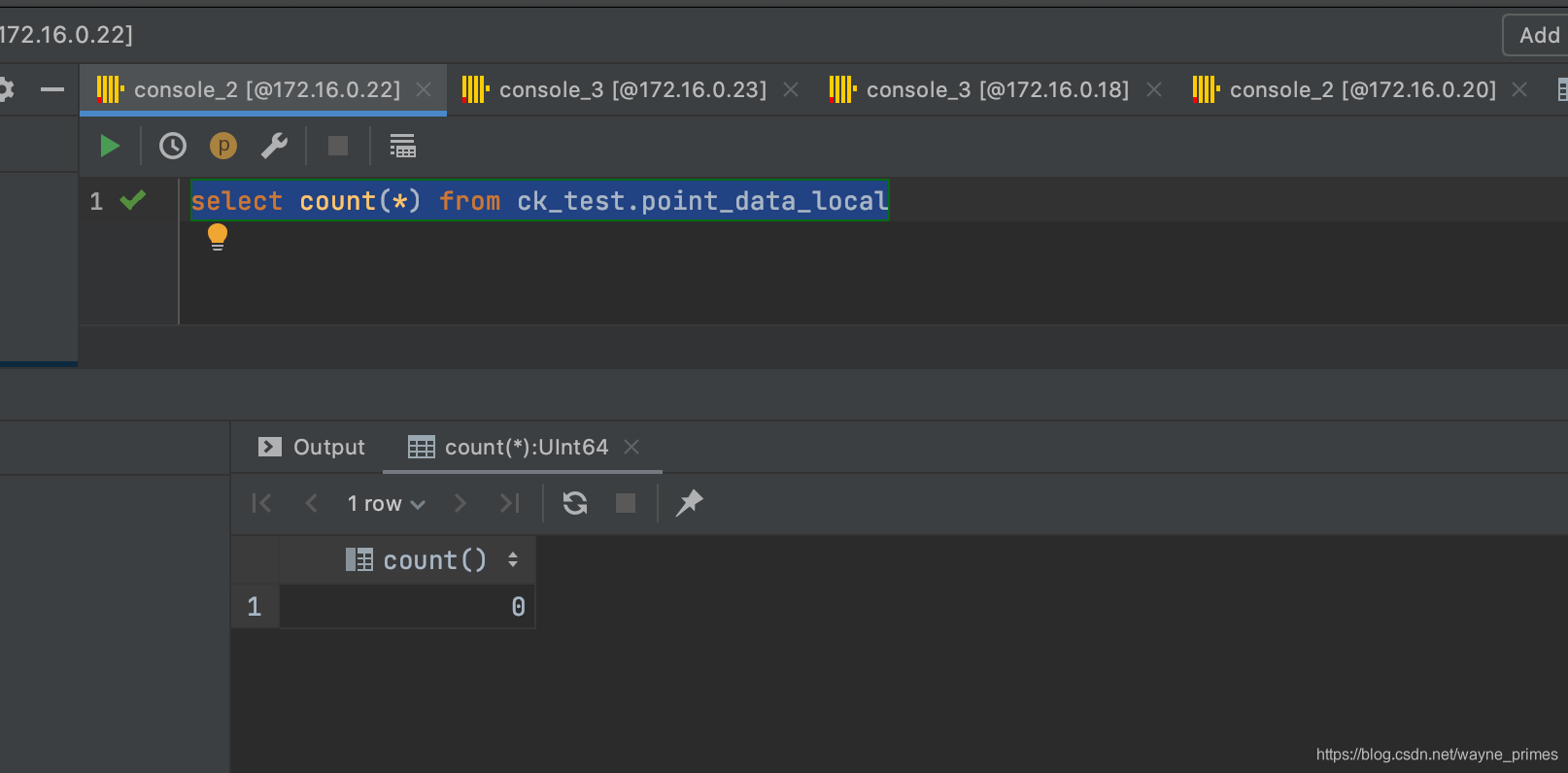
5分钟后,分片2中的节点都无数据。
分区表插入数据结论:根据分区表数据分配方式,当对应数据分配到某一个分片的时候,只会往该分片插入,即使宕机也不会往其他分片上插入数据。
测试:重启A1,应用程序是否会重连A1代替A2(修改重连策略,该问题已修复)
根据应用报错无法连接A2的clickhouse,经过讨论后,重启A1的clickhouse。
即使启动了的分片1中的A1,报错仍为同之前一致,报错无法连接A2的clickhouse,无法向A1中写入数据。
测试:重启应用程序是否能重连至A1(修改重连策略,该问题已修复)
重启应用程序后,可以重连至A1,读取上一次配置,并且可以正常写入。
分片中只要有一个副本存活既可正常工作,如果集群中某一分片中的节点全部宕机,那么分区表无法查询、写入。
测试:停止分片1的clickhouse,测试是否会向分片2中的节点进行写入
若数据未分配到新的分片,数据无法插入,这部分数据将会丢失。
若数据分配到新的分片,数据可以插入至新的分片节点中。



















 1645
1645





 到【灌水乐园】发言
到【灌水乐园】发言









