




在一般的linux问题排查中,机器宕机或者hung机是常见的一种问题。一般我们比较常遇到的lockup问题是hard lockup以及soft lockup问题。现在来讲讲这hard lockup的原理
什么是hard lockup?
hard lockup是linux中的一种异常状态,表现为CPU核心因内核代码长时间占用资源而完全停止响应中断和任务调度。一般情况下,出现了hard lockup的时候,dmesg中会打印出对应的日志以及会raise一个NMI Exception去走hard lockup的panic过程。
hard lockup的定义以及触发条件
-
定义:当CPU在内核态执行代码超过预设阈值(默认10秒)且完全无法响应中断(包括时钟中断、I/O中断等)时,即发生hard lockup。此时系统无法执行任何任务,包括中断处理程序。
-
可能的触发条件:
1、关中断代码异常
2、中断处理程序卡死
3、硬件或者驱动故障
详细过程分析
现在已经知道了hard lockup的定义以后,我们就从代码开始分析这个过程:
首先,我们知道,当出现hard lockup的时候,dmesg中会出现hard lockup的相关警告
Watchdog detected hard LOCKUP on cpu #
// 这段代码在linux的kernel/watchdog.c中
void watchdog_hardlockup_check(unsigned int cpu, struct pt_regs *regs)
{
if (per_cpu(watchdog_hardlockup_touched, cpu)) {
per_cpu(watchdog_hardlockup_touched, cpu) = false;
return;
}
/*
* Check for a hardlockup by making sure the CPU's timer
* interrupt is incrementing. The timer interrupt should have
* fired multiple times before we overflow'd. If it hasn't
* then this is a good indication the cpu is stuck
*/
if (is_hardlockup(cpu)) {
unsigned int this_cpu = smp_processor_id();
struct cpumask backtrace_mask;
cpumask_copy(&backtrace_mask, cpu_online_mask);
/* Only print hardlockups once. */
if (per_cpu(watchdog_hardlockup_warned, cpu))
return;
pr_emerg("Watchdog detected hard LOCKUP on cpu %d\n", cpu);
print_modules();
print_irqtrace_events(current);
if (cpu == this_cpu) {
if (regs)
show_regs(regs);
else
dump_stack();
cpumask_clear_cpu(cpu, &backtrace_mask);
} else {
if (trigger_single_cpu_backtrace(cpu))
cpumask_clear_cpu(cpu, &backtrace_mask);
}
/*
* Perform multi-CPU dump only once to avoid multiple
* hardlockups generating interleaving traces
*/
if (sysctl_hardlockup_all_cpu_backtrace &&
!test_and_set_bit(0, &watchdog_hardlockup_all_cpu_dumped))
trigger_cpumask_backtrace(&backtrace_mask);
if (hardlockup_panic)
nmi_panic(regs, "Hard LOCKUP");
per_cpu(watchdog_hardlockup_warned, cpu) = true;
} else {
per_cpu(watchdog_hardlockup_warned, cpu) = false;
}
}
这个是watchdog检查机器是否出现了hard lockup的那段代码,接下来剖析这段逻辑:
if (per_cpu(watchdog_hardlockup_touched, cpu)) {
per_cpu(watchdog_hardlockup_touched, cpu) = false;
return;
}
首先讲一下什么是per-cpu。
per-cpu
per-cpu宏是linux内核中用于访问每个CPU变量的机制,之所以需要使用per-cpu,是因为可以防止cpu在访问变量的时候出现的锁竞争。也就是说,在多核处理器场景下,每个CPU都有自己的per-cpu变量,这个是每个cpu都有的独占的一个变量副本,访问这些变量的时候不需要锁。
per-cpu的声明
#define per_cpu(var, cpu) (*per_cpu_ptr(&(var), cpu))
通过这行代码,可以获取在cpu号cpu上的val变量
eg:per_cpu(A,5)
这样就获取了5号CPU上的A变量了。
那么现在结合上面的代码:
per_cpu(watchdog_hardlockup_touched, cpu)
这里就是获取给定cpu号上的watchdog_hardlockup_touched,如果watchdog_hardlockup_touched为true;说明被touch过,那就设置为false;否则执行后续的逻辑
小总结
这里有个优化点,那就是这个判断实际上就是把watchdog_hardlockup_touched这个变量设为为false。在hard lockup的场景下,只有watchdog_hardlockup没有被touch过的前提下才会有hard lockup。因此,如果检查的时候发现watchdog_hardlockup_touched以及是被touched过了,那么这里只需要重置状态,不需要后续的检查
判断是否出现了hard lockup
判断是否出现了hard lockup是通过is_hardlockup这个函数来判断的,我们来看下这个函数的实现:
static bool is_hardlockup(unsigned int cpu)
{
int hrint = atomic_read(&per_cpu(hrtimer_interrupts, cpu));
if (per_cpu(hrtimer_interrupts_saved, cpu) == hrint)
return true;
/*
* NOTE: we don't need any fancy atomic_t or READ_ONCE/WRITE_ONCE
* for hrtimer_interrupts_saved. hrtimer_interrupts_saved is
* written/read by a single CPU.
*/
per_cpu(hrtimer_interrupts_saved, cpu) = hrint;
return false;
}
可以看到,机器上是否出现了hard lockup主要是通过hrtimer_interrupts这个变量来判断的
hrint是通过per_cpu函数把`cpu``号cpu上的hrtimer_interrupts变量读取出来(毕竟现在是在判断 当前cpu是否是出现了hard lockup )
然后判断当前cpu中的保存的hrtimer_interrupts_saved的中断数与当前的hrtimer_interrupts中断数进行比较,如果发现了先前保存的中断数跟当前的中断数是一致的,说明了CPU没有对之前中断进行响应,判断出现了hard lockup。如果是正常的话,那么就没有出现hard lockup,同时更新hrtimer_interrupts_saved。
回归主线,回到原来的那个代码上,现在已经知道了is_hardlockup是怎么工作的了。
后面我们来看下下一个代码:
unsigned int this_cpu = smp_processor_id();
smp_processor_id
smp_processor_id()是一个宏,用于获取当前正在运行代码的CPU的ID。在SMP(对称多处理)系统中,这个返回就是返回当前执行线程所在的CPU的核心编号
在当前代码中,就是获取执行当前CPU的ID并存储在this_cpu中。对于smp_processor_id的过程在这里就先不发散了
当发现了当前CPU出现了hard lockup的时候,就会打印出模块以及中断事件信息等
cpumask
cpumask是什么?
cpumask是CPU掩码,是一个位图
/* Don't assign or return these: may not be this big! */
typedef struct cpumask { DECLARE_BITMAP(bits, NR_CPUS); } cpumask_t;
cpumask是linux中用于表示CPU集合的一种数据结构。每个CPU的编号对应一个位:
- cpumask是一个位图
- 每个位代表对应的CPU
- 如果某位被设置为1,表示对应的CPU在集合中
- 如果这个位为0,表示对应的CPU不在集合中
这样,我们通过cpu_online_mask可以知道当前在线并且可被调度的CPU有哪些。
下面提供一些关于cpumask的操作API:
- cpumask_copy():复制一个cpumask到另一个地方
- cpumask_set_cpu():将指定的CPU添加到cpumask中
- cpumask_clear_cpu(): 从cpumask中移除指定的CPU
- cpumask_test_cpu(): 测试指定CPU是否在cpumask中
- cpumask_and():执行两个cpumask的AND操作
- cpumask_or():执行两个cpumask的OR操作
因此,在上面的代码中,是将当前在线且可被调度的CPUmask复制到backtrace_mask中,并且在出现了hard lockup的时候,从缓冲区backtrace_mask中清除掉当前出现hard lockup的cpu(我个人认为就是因为当前cpu出现了hard lockup,因此这个cpu已经是不属于在线且可被调度的状态,因此需要从backtrace_mask中清除掉)
/*
* Perform multi-CPU dump only once to avoid multiple
* hardlockups generating interleaving traces
*/
if (sysctl_hardlockup_all_cpu_backtrace &&
!test_and_set_bit(0, &watchdog_hardlockup_all_cpu_dumped))
trigger_cpumask_backtrace(&backtrace_mask);
if (hardlockup_panic)
nmi_panic(regs, "Hard LOCKUP");
sysctl_hardlockup_all_cpu_backtrace是sysctl的一个可调参数,用于控制在出现hard lockup的时候是否触发所有CPU的回溯
!test_and_set_bit(0, &watchdog_hardlockup_all_cpu_dumped)
这个是一个原子操作,用于检查watchdog_hardlockup_all_cpu_dumped这个变量,是用于确保是否已经dump过,这样,这个判断主要就是用于确保在开启了all_cpu_backtrace的时候,所有cpu只会被回溯一次,避免在多CPU出现hard lockup的时候会出现多次打印的问题(这样真的会让问题排查人员晕死的)
最后就是如果在开启了hardlockup_panic的时候,使用nmi_panic
NMI panic
void nmi_panic(struct pt_regs *regs, const char *msg)
{
int old_cpu, cpu;
cpu = raw_smp_processor_id();
old_cpu = atomic_cmpxchg(&panic_cpu, PANIC_CPU_INVALID, cpu);
if (old_cpu == PANIC_CPU_INVALID)
panic("%s", msg);
else if (old_cpu != cpu)
nmi_panic_self_stop(regs);
}
NMI是一种不可屏蔽中断,主要用于处理紧急的硬件时间等。下面我列举了一些关于NMI与普通中断的区别:
| 特性 | 普通中断 | NMI |
|---|---|---|
| 可屏蔽性 | 可以通过中断屏蔽位屏蔽 | 不可屏蔽 |
| 优先级 | 通常较低 | 最高优先级之一 |
| 用途 | 设备IO、定时器等 | 紧急硬件事件处理 |
| 处理限制 | 相对宽松 | 非常严格的环境限制 |
| 嵌套 | 通常不允许嵌套 | 可能嵌套,需要特殊处理 |
在这个代码中,raw_smp_processor_id()是用于获取当前正在执行代码的CPU编号
panic_cpu是一个全局变量,其声明方式如下:
atomic_t panic_cpu = ATOMIC_INIT(PANIC_CPU_INVALID);
panic_cpu这个变量是用于同步panic()以及crash_kexec()执行的。这个变量表示当前正在执行panic的那个cpu编号。PANIC_CPU_INVALID的值为-1的时候表示当前没有CPU进入panic或者crash_kexec的流程中
nmi_panic_self_stop的内层函数为:
void __weak __noreturn panic_smp_self_stop(void)
{
while (1)
cpu_relax();
}
其实就是让cpu空转。
结合这些解析,可以知道当出现nmi_panic的时候,具体要做的事情就是判断系统中是否已经有cpu在处理panic过程。而且系统中只需要一个cpu来处理panic过程就行。如果已经有cpu在处理panic过程,那么出现hard lockup的那个cpu就会空转
hard lockup小总结
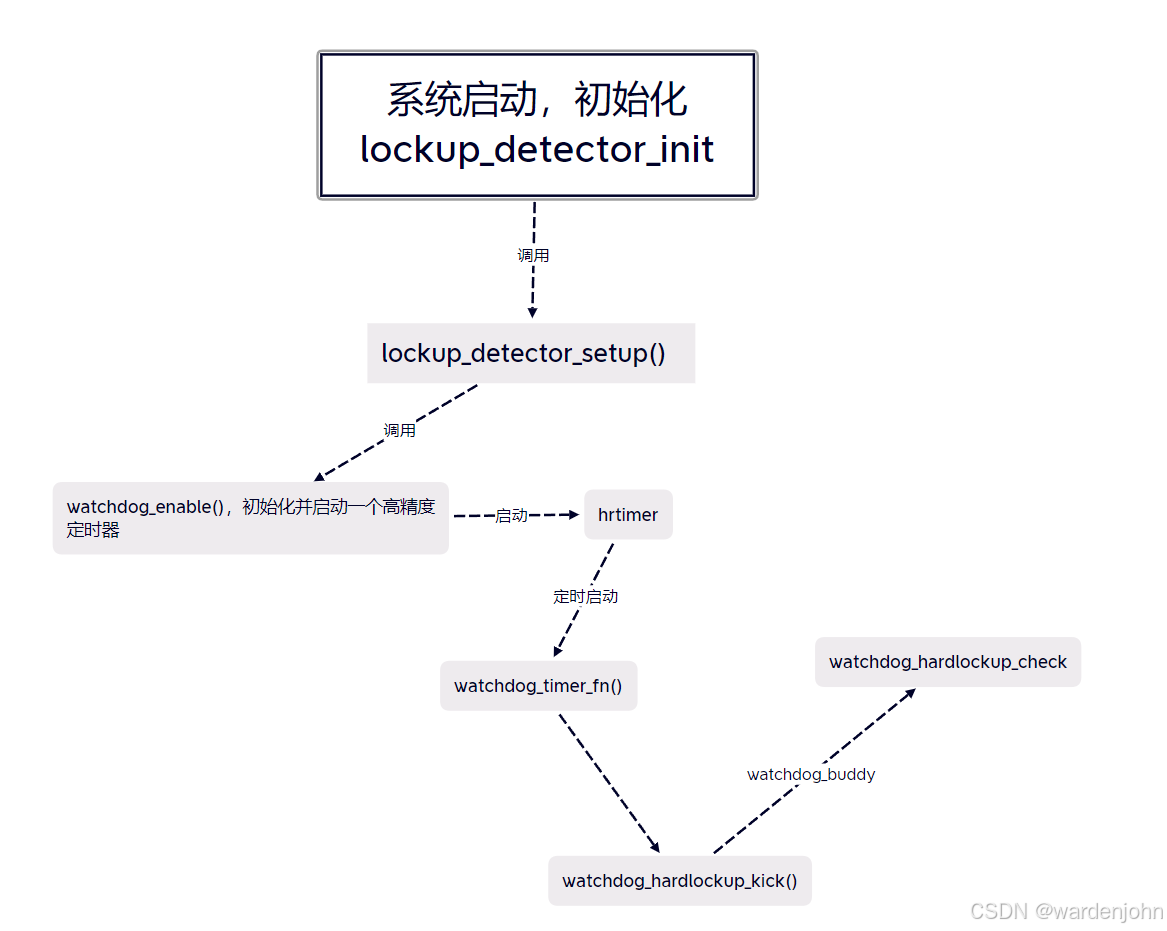
这里我总结两点:
- 1、watchdog_hardlockup_kick()是需要更新hard lockup的中断计数器,用于比较cpu是否响应中断的
- 2、watchdog_hardlockup_check()需要由watchdog_buddy来调用,我个人理解就是由当前运行CPU去检测其他CPU是否出现了hard lockup。毕竟出现了hard lockup的CPU都不响应的话,自己怎么能进入hard lockup的检测流程呢?


















 1872
1872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









