




 本文详细介绍了pandas库在数据分析中的运用,包括数据读取、数据类型、DataFrame方法、统计方法、时间格式处理、数据合并、函数应用、数据清洗等方面。讲解了如何进行数据类型转换、时间序列操作、数据合并策略、数据分组和透视表、异常值检测、空值处理等关键操作,旨在提升数据处理能力。
本文详细介绍了pandas库在数据分析中的运用,包括数据读取、数据类型、DataFrame方法、统计方法、时间格式处理、数据合并、函数应用、数据清洗等方面。讲解了如何进行数据类型转换、时间序列操作、数据合并策略、数据分组和透视表、异常值检测、空值处理等关键操作,旨在提升数据处理能力。
数据读取
- 读取csv文本文件(csv文件一般编码方式为gbk)
pd.read_table(r'路径\info.csv',encoding='编码方式',seq=',')
pd.read_csv(r'路径\info.csv',encoding='编码方式',seq=',')
- 读取excel文件
pd.read_excel(r'路径\detail.xlsx',sheet_name=1,header=1)
参数:sheet_namee= 1,读取第一张表格的数据,index_col指定第几列为行索引,header=1指定第一行为列索引,
- 合并多工作表的文件:
workbook = xlrd.open_workbook("meal_order_detail.xlsx")
sheets = workbook.sheet_names()
total = DataFrame()# 定义存储所有数据的容器
for i in range(len(sheets)):# 循环遍历所有sheet,汇总多表中的所有数据
data=pd.read_excel("./matplot_data/meal_order_detail.xlsx",sheetname=i,index_col=False)
total = total.append(data)#需要有变量接收返回值
fp = pd.ExcelWriter("output.xlsx")# 将数据保存为文件
total.to_excel(write,"sheet1")
fp.save()
还可以使用拼接或堆叠的方式进行合并数据
数据类型
- 创建Series类型数据(两种方式):
s1 = pd.Series(['w','e','r'],index=[2,3,4])
s2 = pd.Series({'a':1,'b':2,'c':3}) #key:为索引值,values:数据值
series意为序列,结合了字典与列表的特点,既存在类键值对,又可以使用索引进行取值
- 创建DataFram类型数据(两种方式)
#第一种:以数组形式传入数据,可指定行列索引
df1 = pd.DataFrame([[1,2,3],[4,6,7]],columns=[0,0,0],index=[1,1])
#coolumns为列索引,index为行索引
#第二种:以键值对方式传入数据,也可以指定行列索引
df2 = pd.DataFrame({'第一列':[1,2,3,4],'第二列':[5,6,7,8]},index=[1,2,3,4])
#key为列索引,index为行索引
dataframe中的方法
-
data.columns#获取所有列名,可以用来作为键进行取值。例:
print('order_id列的数据',data['order_id']) -
data.size#元素的所有个数
-
data.ndim#维度
-
data.T#转置
-
type(data.values)) # 数据类型为数组类型(numpy.ndarray)
-
data.shape #查看结构
-
data.index 返回所有的行索引
-
data.set_index():#设置索引
-
data.rename():#为字段重新赋值,使用字典格式
-
data.reset_index():#重设索引,可以用在分组之后的数据
-
isin():查找某列或整个表中是否存在某个值,使用列表进行传值
例:
data["columns"].isin(["qq","aa","ee"]),返回的是整列的bool值 -
data[“columns”].value_counts()#对某些类别出现的次数进行计数,参数为series,另外还可以使用参数normalize计算占比,只适用于单列
强制类型转换:
data.astype(‘float’)
- float
- int
- bool
- datetime64[ns]
- datetime64[ns, tz]
- timedelta[ns]
- category
- object
- str
常用统计方法(汇总运算)
- data[].counta():某个区域中非空单元格的个数
- data[].count():某个区域中含有数字的单元格的个数
- data[].sum():求和
- data[].mean():求平均值
- data[].max():求最大值
- data[].min():求最小值
- data[].median():求中位数
- data[].node():求众数
- data[].std():求方差
- data[].var():求标准差
- data[].quantile():求分位数
分位数主要有四分之一分位数(0.25),四分之二分位数(0.5),四分之三分位数(0.75),其中四分之二分位数就是中位数
例:data[].quantile(0.75)
时间格式
- 时间序列格式转换为标准时间格式
data['place_order_time'] = pd.to_datetime(data['place_order_time']) - 将字符串转为timedelta格式
time = pd.to_timedelta("1 day")
日期提取(使用列表生成式获取整列所有的时间):
年、月、日、星期
year = [i.year for i in data['place_order_time']]
month = [i.month for i in data['place_order_time']]
day = [i.day for i in data['place_order_time']]
weekday_name = [i.weekday_name for i in data['place_order_time']]
注意:获取日期时,要使用date()函数来进行获取,这点与其他方法不同
获取时间要是用time()函数
时间运算
- day:日 hours:小时 seconds:秒 weeks:星期
data_time = pd.Timedelta(days=2)+data_time
可加减参数:[weeks, days, hours, minutes, seconds, milliseconds, microseconds, nanoseconds]- 计算是一年中的第几周:
data_time.weekofyear - 计算是一年中的第几天:
data_time.dayofyear - 其他方法:
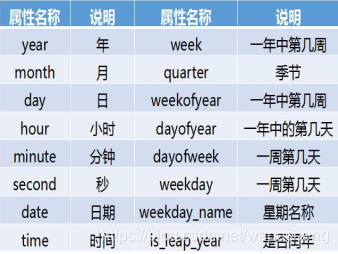
设置时间索引
- 设置:
index = pd.DatatimeIndex(["2018-01-01","2018-02-02","2019-02-18"])
data = pd.DataFrame(np.array(1,11),columns=["num"],index=index)
- 使用索引:
可直接使用data[“2018”]或data[“2018-1”]或data[“2018-1-1”]来进行索引到相应时间的数据
数据合并
主键合并
- 数据准备:
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
#print(left)
right = pd.DataFrame({'key1': ['K0', 'K5', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
-
单个主键:
pd.merge(left, right, how="inner", on="key1")
how参数属性说明:
inner为内连接,求交集
outer为外连接,求并集 -
how参数除inner与outer之外还有left左连接与right右连接
- 左连接以左表为主,根据左表中的主键去右表中寻找对应的值,当左表寻找完毕之后,不再进行寻找:
pd.merge(left, right, how="left", on=["key1","key2"]) - 右连接以右表为主,根据右表中的主键去左表中寻找对应的值,当右表寻找完毕之后,不再进行寻找:
pd.merge(left, right, how="right", on=["key1","key2"])
- 左连接以左表为主,根据左表中的主键去右表中寻找对应的值,当左表寻找完毕之后,不再进行寻找:
单个主键使用内连接:
key1 key2_x A B key2_y C D
0 K0 K0 A0 B0 K0 C0 D0
1 K0 K1 A1 B1 K0 C0 D0
2 K1 K0 A2 B2 K0 C2 D2
3 K2 K1 A3 B3 K0 C3 D3
单个主键使用外连接:
key1 key2_x A B key2_y C D
0 K0 K0 A0 B0 K0 C0 D0
1 K0 K1 A1 B1 K0 C0 D0
2 K1 K0 A2 B2 K0 C2 D2
3 K2 K1 A3 B3 K0 C3 D3
4 K5 NaN NaN NaN K0 C1 D1
单个主键使用左连接:
key1 key2_x A B key2_y C D
0 K0 K0 A0 B0 K0 C0 D0
1 K0 K1 A1 B1 K0 C0 D0
2 K1 K0 A2 B2 K0 C2 D2
3 K2 K1 A3 B3 K0 C3 D3
单个主键使用右连接:
key1 key2_x A B key2_y C D
0 K0 K0 A0 B0 K0 C0 D0
1 K0 K1 A1 B1 K0 C0 D0
2 K1 K0 A2 B2 K0 C2 D2
3 K2 K1 A3 B3 K0 C3 D3
4 K5 NaN NaN NaN K0 C1 D1
- 多个主键:
pd.merge(left, right, how="inner", on=["key1","key2"]),需两个主键均相等 - 当两个表中主键名称不一样时,也可以进行主键合并,使用left_on与right_on参数:
pd.merge(left, right, how="inner", left_on="key2", right_on="key1")
表堆叠
- #拼接表,分为纵向拼接与横向拼接,其中纵向拼接与横向拼接又可以分为内连接与外连接
#内连接是求交集,外连接为求并集
data = pd.read_excel("meal_order_detail.xlsx",sheet_name=0)
data1 = pd.read_excel("meal_order_detail.xlsx",sheet_name=1)
data2 = pd.read_excel("meal_order_detail.xlsx",sheet_name=2)
data_total = pd.concat((data,data1,data2),axis=0,join="outer")
- concat堆叠:根据行列索引进行表的拼接,不看元素取值
- merge主键合并:根据两个表中的元素取值是否相同来进行表的拼接(与行列索引无关),如果没有指定要按哪个列进行拼接时,merge()方法会默认寻找两个表中的公共列,然后以这个公共列作为连接键进行连接
重叠合并
- 当两个表的结构相同,且都有缺失数据时,可以利用重叠合并来拼接数据,构成一个完整的表
- 数据准备:
dict1 = {'ID':[1,2,3,4,5,6,7,8,9],'System':['W10','w10',np.nan,'w10',np.nan,np.nan,'w7','w7','w8']}
dict2 = {'ID':[1,2,3,4,5,6,7,8,9],'System':[np.nan,np.nan,'w7','nan','w7','w7','w8',np.nan,np.nan]}
df1 = pd.DataFrame(dict1)
df2 = pd.DataFrame(dict2)
- 应用:
combine_first是以df1为主,当两个表中都有数据时,以df1中的数据为主,df1中的数据寻找完毕,不再填充
print(df1.combine_first(df2))
ID System
0 1 W10
1 2 w10
2 3 w7
3 4 w10
4 5 w7
5 6 w7
6 7 w7
7 8 w7
8 9 w8
- axis
axis=0表示在纵向上进行操作,改变的是表的高度
axis=1表示在横向上进行操作,改变的是表的宽度
函数
loc函数:
- loc是基于标签的,如果给出的索引中包含没有的标签,会报错
- loc索引的开闭区间机制和Python传统的不同,而是与MATLAB类似的双侧闭区间,即只要出现,就会包含该标签
- 数字也可以放入loc中当做索引,但是这时数字指的是标签而不是 位置
- loc也可以接受布尔索引来取出其中的一些行
- loc是前闭后闭
应用:print(data.loc[:, 'order_id']) #输出所有的order_id print(data.loc[2:5, ['order_id','dishes_name']]) #输出二到五行的order_id,和dishes_name print(data.loc[data['order_id']==1192, ['order_id','dishes_name']]) #订单号为1192的所有dishes_name,order_id print(data.loc[data['counts']>2, ['order_id','dishes_name','counts']])
iloc函数:
1、用法完全和numpy中的数字索引一样,开闭区间的逻辑也和Python是相同的。
2、如果iloc方括号中直接给定一个数字或者一个slice的话,默认索引的是行
3、loc是前闭后开
print(data.iloc[2:5, 1:3])#iloc只能接索引下标值print(data.iloc[1,0])#第二行第一列的值print(data.iloc[:,0])#第一列所有行的值print(data.iloc[2,:])#第三行所有的值print(data.iloc[1:4,2:5])#第二行到第四行与第三行到第五行的值,符合python前闭后开的逻辑
describe()函数
-
数值型
print(data[['counts','amounts']].describe())
count 3647.000000 3647.000000 (非空值)
mean 1.110502 44.500137 (平均数)
std 0.610403 35.163117 (标准差)
min 1.000000 1.000000 (最小值)
25% 1.000000 25.000000
50% 1.000000 35.000000
75% 1.000000 55.000000
max 10.000000 178.000000 (最大值)
-
类别型
print(data['dishes_name'].describe())
dishes_name
count(非空值) 3647
unique(非重复数) 152
top(频数最高的) 白饭/大碗
freq(最高频数) 122
分组与透视表
-
groupby
data_group = detail[['order_id','counts','amounts']].groupby(by='order_id')
分组聚合之后是需要接统计函数从才能打印聚合之后的print(data_group.sum().head())#取出结果的前5行
-
透视表与交叉表
-
透视表
- 透视表:根据一个或多个键值对数据进行聚合,根据行和列将数据划分到各个区域 #margins=true为数据添加总数,相当于总结
data_pivot = pd.pivot_table(data,index=['order_id','dishes_name'],fill_value=0,margins=True)#fill_value将空值填充为0
-
交叉表
- 交叉表是特殊的透视表,能够完成透视表不能完成的工作,但是有的工作使用透视表也能够完成,具体使用哪一种,还要根据实际业务需要来决定
data_cross = pd.crosstab(index=data['order_id'],columns=data['dishes_name'])
-
分组与透视表的区别
- 两者相类似却又不相同,数据分组是在一维方向上不断进行拆分,而数据透视表是在行列方向上同时进行拆分
-
聚合函数
-
agg()函数
- 1:对不同的字段,求相同的统计函数
print(detail[['counts','amounts']].agg([np.sum,np.mean])) - 2、对不同字段求不同的统计函数(使用字典):
print(data.agg({'counts': np.sum, 'amounts': [np.mean, np.sum]}))
print(data.agg({'counts': np.sum, 'amounts': np.mean}))
- 1:对不同的字段,求相同的统计函数
-
apply()函数
- apply()函数与agg()函数使用方式相似,都可以对某一行某一列执行相同的操作,可以与匿名函数lambda搭配使用,可以使用多个统计方法,使用列表传值
-
applymap()函数
- applymap()函数可以对表中的所有数据执行相同的操作,可以与匿名函数lambda搭配使用
-
transfrom函数:
参数:ufuncprint(data[['counts','amounts']].transform(lambda x: x * 2).head())#将两列值变为自身的2倍
删除数据:drop()
data.drop(labels=i,inplace=True,axis=1)
#labels传的是索引,可以是行索引或者列索引
排序:sort_vlues()
data.sort_values(by=['info_id'],ascending=False,inplace=True)
#ascending=False 降序排序
重设索引:reset_index()
detail_agg.set_index()#重设index索引,drop=true时表示删除原来的索引detail_agg.set_index('amounts')#将amounts这一列设为index
数据清洗
判断数据相似度
- 相似度:[-1:1] -1完全相反 1 完全相同 0完全不同
spearman法、kendall法,默认为pearson方法
#仅可对数值型数据进行相似度判断 corrDet = detail[['counts', 'amounts']].corr(method='kendall')
counts amounts
counts 1.000000 -0.229968
amounts -0.229968 1.000000
异常值检测
- 异常值:指数据中个别值的数据明显偏离其余的数值,成为离群点(野值)
(1.)根据实际应用场景进行剔除
(2.)3σ原则(数据特点符合正态分布的数据适合使用) - 利用3σ原则取出异常值
data_mean = data['amounts'].mean()
data_std = data['amounts'].std()
mask = (data_mean -3*data_std <data['amounts']) | (data_mean +3*data_std >data['amounts'])
print(data['amounts'][mask])
处理重复
-
数值重复
- 使用:
detail['dishes_name'].drop_duplicates()#去除dishes_name里面的重复值
detail.drop_duplicates(subset=['order_id', 'emp_id'])#去除order_id和emp_id都一样的数据 - #默认保留第一个重复值,inplace=False 表示不对原表修改,返回一个新的数据表;True表示对原表进行操作,返回为none,重复值返回NaN
其中有参数keep:意为保留第几个重复值,可取first,last,false,默认为first
多列去重,同一行数据中多个字段必须均相等才被认为是重复
- 使用:
-
特征重复
- 使用:
corr_det = data[["counts", "amounts", "dishes_name"]].corr(method=“pearson”) mask = corr_det == 1 index = corr_det.index print(index[mask["counts"]]) - 特征重复(多列数据之间的相关性)取值范围是:[-1,1],从完全不相似到完全相似
#参数method的取值为:kendall (肯德尔等级)相关系数,spearman斯皮尔曼等级相关系数,默认为pearson(皮尔逊)相关系数
- 使用:
空值的检测与处理
-
空值检测
- notnull() 非空时返回True
mask = data.notnull().sum()==0#非空时为False(也可使用isnull来判断为空)
del1 = data.columns[mask]#返回上一步中值为True的列名 - isnull() 空值时返回True;
is_null = data.isnull().sum()
mask = data.shape[0] == is_null
#利用值进行寻找索引,还可以使用索引的位置进行寻找索引
labels = mask.index[mask]
- notnull() 非空时返回True
-
空值删除
- 删除全空列:
data.drop(labels=del1,axis=1)#通过列名删除空值所在的列 - dropna: 使用dropna时,会自动定位到none值,使用axis来控制删除行或列
detail.dropna(axis=1, how='any')或者在原表基础上进行修改:
detail.dropna(axis=1, how='any',inplace=True)
参数说明:axis=0,按行删除;how="any"存在空值时删除,how="all"全为空值时删除
- 删除全空列:
-
空值填充与插值
-
插值时不能超过因变量的起始范围
-
线性插值
from scipy.interpolate import interp1d Line = interp1d(x, y1, kind='linear') print(Line([6, 7])) -
拉格朗日插值
from scipy.interpolate import lagrange lagrange = lagrange(x, y1) print(lagrange([6, 7]))#非线性可以用来估计线性 -
牛顿插值
-
样条插值
from scipy.interpolate import spline new_data = spline(x,y1,xnew=([6,7]))常用中位数、众数、均值来填充缺失值,需要对单独一列进行计算
detail.fillna(data[].mean(), inplace=True)
-
标准化数据
- 离差标准化:
x=(x-min)/(max-min),标准化后的数据范围为:[0,1]
注意:保证最大值与最小值非异常值,否则结果会趋近于0 - 标准差标准化:
x=(x-mean)/std,目的是将数据化为均值为0,方差为1的列 - 小数定标标准化:
x=x/10^k(k = np.ceil(np.log10(data[].abs().max())))
数据转换
-
哑变量处理
- 将类别型特征转化为稀疏矩阵(将非数值型转换为数值型)onehot编码
pd.get_dummies(data["dishes_name"]) - 对一列非数值型的的数据将其记为n行n列的矩阵,在矩阵的每一行将该列数据对应的值记为1,该行其他数据记为0.应用到每一行
- 将类别型特征转化为稀疏矩阵(将非数值型转换为数值型)onehot编码
-
离散化连续型数据
- 等宽法:将数据平均分为具有相同的宽度的区间(前开后闭)
da = pd.cut(detail['amounts'], 5) print(da.value_counts()) - 等频法:使得不同区间内的值的数量尽可能的接近
detail['amounts'].quantile(np.arange(0, 1 + 0.2, 0.2)) pd.qcut(detail['amounts'], 5).value_counts()
- 等宽法:将数据平均分为具有相同的宽度的区间(前开后闭)

















 1639
1639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









