




 本文介绍了爬虫相关知识。阐述做爬虫的原因,指出可解决数据获取难题。解释爬虫是模拟人类请求网站的程序,还说明了使用爬虫需学习的内容。介绍了通用、聚焦等爬虫种类,重点讲解通用搜索引擎工作原理,包括抓取网页、数据存储、预处理和提供检索服务等步骤,也提及了其局限性。
本文介绍了爬虫相关知识。阐述做爬虫的原因,指出可解决数据获取难题。解释爬虫是模拟人类请求网站的程序,还说明了使用爬虫需学习的内容。介绍了通用、聚焦等爬虫种类,重点讲解通用搜索引擎工作原理,包括抓取网页、数据存储、预处理和提供检索服务等步骤,也提及了其局限性。
一、爬虫与数据
(一)为什么要做爬虫
都说现在是大数据时代,但是与之相对应的问题是,大数据中的数据从何而来。可以人工收集数据,但是人工收集数据的效率却免不了太过低下。也可以找一些专门从事数据服务的公司进行购买,但会花费不菲的代价。下面是经常用到的一些数据类的网站。
1、 企业产生的用户数据:
百度指数: http://index.baidu.com/
阿里指数: https://alizs.taobao.com/
TBI 腾讯浏览指数: http://tbi.tencent.com/
新浪微博指数: http://data.weibo.com/index
2、 数据平台购买数据:
数据堂: http://www.datatang.com/about/about-us.html
国云数据市场: http://www.moojnn.com/data-market/
贵阳大数据交易所: http://trade.gbdex.com/trade.web/index.jsp
3、 政府/机构公开的数据:
中华人民共和国国家统计局数据: http://data.stats.gov.cn/index.htm
世界银行公开数据: http://data.worldbank.org.cn/
联合国数据: http://data.un.org/
纳斯达克: http://www.nasdaq.com/zh
4、 数据管理咨询公司:
INS(500 人, 一年产值 300 亿)
麦肯锡: http://www.mckinsey.com.cn/
埃森哲: https://www.accenture.com/cn-zh/
艾瑞咨询: http://www.iresearch.com.cn/
或者可以选择招聘/做一名爬虫工程,自己动手寻找数据。
(二)爬虫是什么
通俗理解:爬虫是一个模拟人类请求网站行为的程序。可以自动请求网页、并数据抓取下来,然后使用一定的规则提取有价值的数据。
专业解释:网络爬虫
(三)我们需要学习什么来使用爬虫
- Python 基础语法学习(基础知识)
- HTML 页面的内容抓取(数据抓取)
- HTML 页面的数据提取(数据清洗)
- Scrapy 框架以及 scrapy-redis 分布式策略(第三方框架)
- 爬虫(Spider)、 反爬虫(Anti-Spider)、 反反爬虫(Anti-Anti-Spider)之间的斗争…
三、爬虫的种类
网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫(General Purpose Web Crawler)、聚焦网络爬虫(Focused Web Crawler)、增量式网络爬虫(Incremental Web Crawler)、深层网络爬虫(Deep Web Crawler)。 实际的网络爬虫系统通常是几种爬虫技术相结合实现的。
(一) 通用爬虫
通用网络爬虫是捜索引擎抓取系统(Baidu、 Google、 Yahoo 等) 的重要组成部分。 主要目的是将互联网上的网页下载到本地, 形成一个互联网内容的镜像备份。
(二) 通用搜索引擎(Search Engine) 工作原理
通用网络爬虫 从互联网中搜集网页, 采集信息, 这些网页信息用于为搜索引擎建立索引从而提供支持, 它决定着整个引擎系统的内容是否丰富, 信息是否即时, 因此其性能的优劣直接影响着搜索引擎的效果。
第一步: 抓取网页
搜索引擎网络爬虫的基本工作流程如下:
首先选取一部分的种子 URL, 将这些 URL 放入待抓取 URL 队列;
取出待抓取 URL, 解析 DNS 得到主机的 IP, 并将 URL 对应的网页下载下来, 存储进已下载网页库中, 并且将这些 URL 放进已抓取 URL 队列。
分析已抓取 URL 队列中的 URL, 分析其中的其他 URL, 并且将 URL 放入待抓取 URL队列, 从而进入下一个循环…
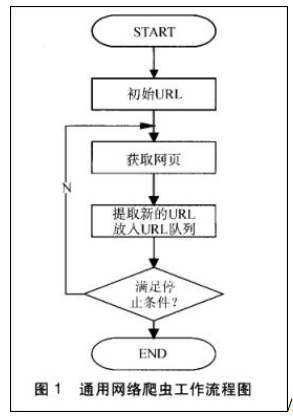
那么, 搜索引擎如何获取一个新网站的 URL:
(1) 新网站向搜索引擎主动提交网址:(如百度 http://zhanzhang.baidu.com/linksubmit/url)
(2) 在其他网站上设置新网站外链(尽可能处于搜索引擎爬虫爬取范围)
(3) 搜索引擎和 DNS 解析服务商(如 DNSPod 等) 合作, 新网站域名将被迅速抓取。
但是搜索引擎蜘蛛的爬行是被输入了一定的规则的, 它需要遵从一些命令或文件的内
容, 如标注为 nofollow 的链接, 或者是 Robots 协议。
Robots 协议(也叫爬虫协议、 机器人协议等) , 全称是“网络爬虫排除标准”(Robots Exclusion Protocol) , 网站通过 Robots 协议告诉搜索引擎哪些页面可以抓取, 哪些页面不能抓取, 例如:
淘宝网: https://www.taobao.com/robots.txt
腾讯网: http://www.qq.com/robots.txt
第二步: 数据存储
搜索引擎通过爬虫爬取到的网页, 将数据存入原始页面数据库。 其中的页面数据与用户浏览器得到的 HTML 是完全一样的。
搜索引擎蜘蛛在抓取页面时, 也做一定的重复内容检测, 一旦遇到访问权重很低的网站上有大量抄袭、 采集或者复制的内容, 很可能就不再爬行。
第三步: 预处理
搜索引擎将爬虫抓取回来的页面, 进行各种步骤的预处理。
提取文字
中文分词
消除噪音(比如版权声明文字、 导航条、 广告等……)
索引处理
链接关系计算
特殊文件处理
···
除了 HTML 文件外, 搜索引擎通常还能抓取和索引以文字为基础的多种文件类型, 如
PDF、 Word、 WPS、 XLS、 PPT、 TXT 文件等。 我们在搜索结果中也经常会看到这些文件类型。
但搜索引擎还不能处理图片、 视频、 Flash 这类非文字内容, 也不能执行脚本和程序。
第四步: 提供检索服务, 网站排名
搜索引擎在对信息进行组织和处理后, 为用户提供关键字检索服务, 将用户检索相关的信息展示给用户。
同时会根据页面的 PageRank 值(链接的访问量排名) 来进行网站排名, 这样 Rank 值高的网站在搜索结果中会排名较前, 当然也可以直接使用 Money 购买搜索引擎网站排名,简单粗暴。
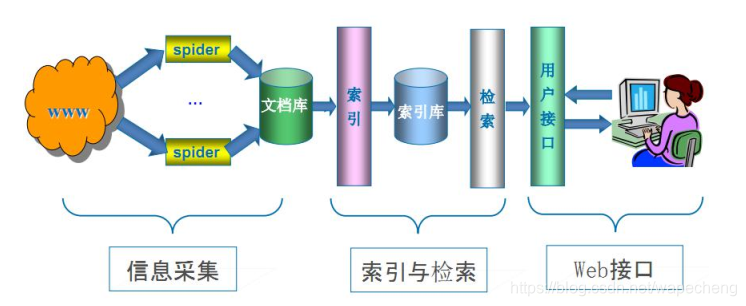
(三) 通用性搜索引擎存在一定的局限性:
通用搜索引擎所返回的结果都是网页, 而大多情况下, 网页里 90%的内容对用户来说
都是无用的。不同领域、 不同背景的用户往往具有不同的检索目的和需求, 搜索引擎无法提供针对具体某个用户的搜索结果。
万维网数据形式的丰富和网络技术的不断发展, 图片、 数据库、 音频、 视频多媒体等不同数据大量出现, 通用搜索引擎对这些文件无能为力, 不能很好地发现和获取。
通用搜索引擎大多提供基于关键字的检索, 难以支持根据语义信息提出的查询, 无法准确理解用户的具体需求。
针对这些情况, 聚焦爬虫技术得以广泛使用。
(四) 聚焦爬虫
聚焦爬虫, 是"面向特定主题需求"的一种网络爬虫程序, 它与通用搜索引擎爬虫的区别在于: 聚焦爬虫在实施网页抓取时会对内容进行处理筛选, 尽量保证只抓取与需求相关的网页信息。
想要使用爬虫,还需要了解有关HTTP协议的详细内容。
可以移步另一篇文章
HTTP协议详解

















 816
816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









