






背景
最近项目测试中,需要处理一枇图片数据。但是其他同事提供的是内嵌到WPS单元格内的图片,直接提取单元格内容,只能获取到形如“=DISPIMG(“ID_8646994B7F0E4E2CBDEF2BBD89791AC2”,1)”的数据,拉不到实际的图片数据。
一番搜索,发现这是wps才有的配置,将我们的.xlsx文件转成.zip后,可以发现,其中文件格式如下:
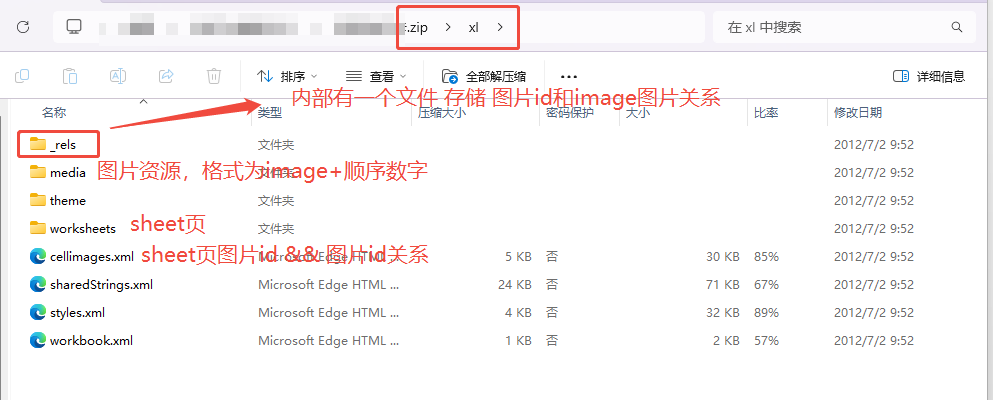
如上图所示,我们只要取出三个文档,就可以获得 单元格图片id->图片id->image图片
需要的三个文档分别为:
xl/cellimages.xml
xl/_rels/cellimages.xml.rels
xl/media/[image_name]
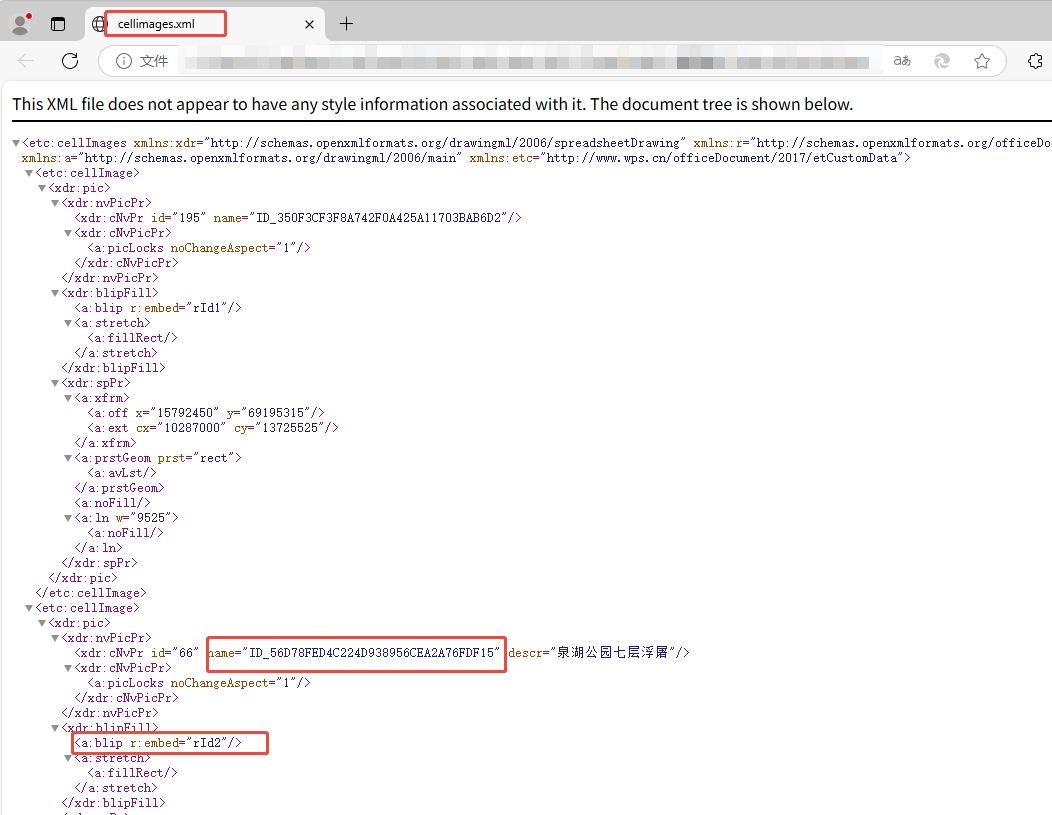
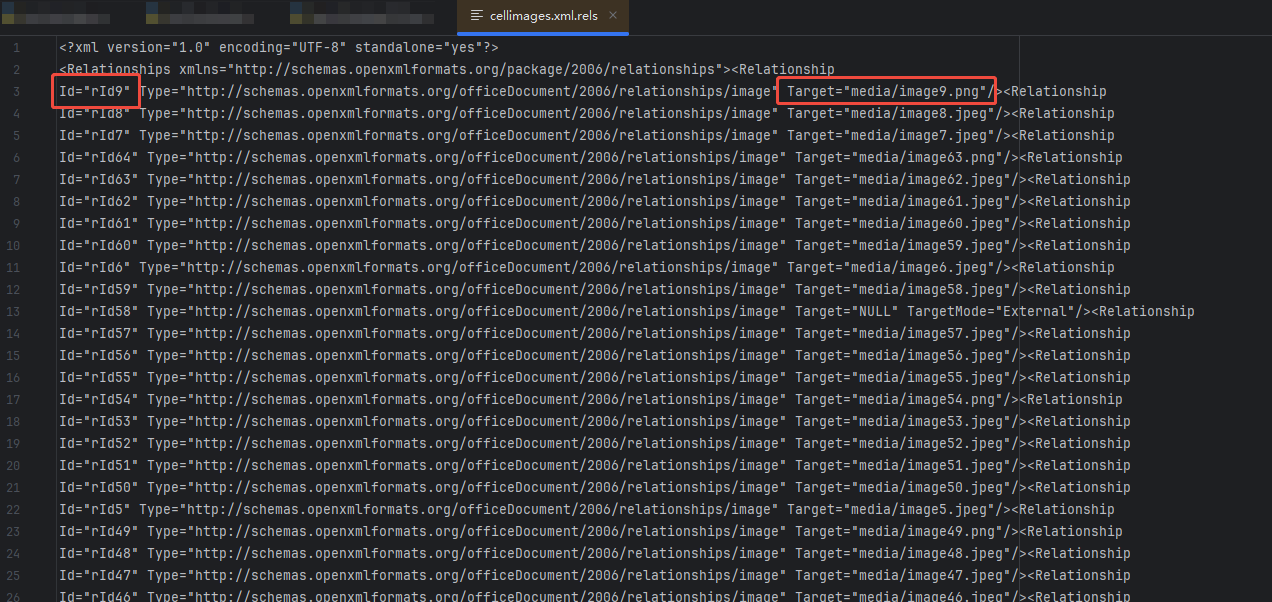
故,此处可以通过下述代码完成id的转换。
import zipfile
import os
import xml.etree.ElementTree as ET
import openpyxl
import logging
import pictUpload
# 设置日志记录
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
pictcow = '变更后图片'
travelcow = '游历卡ID'
def extract_image_id(formula):
"""
从公式中提取 image_id。
支持提取多个 image_id,并处理异常情况。
"""
image_ids = []
start = 0
while True:
start_pos = formula.find('=_xlfn.DISPIMG(', start)
if start_pos == -1:
break
end_pos = formula.find(')', start_pos)
if end_pos == -1:
break
substring = formula[start_pos:end_pos]
quote_start = substring.find('"')
if quote_start == -1:
start = end_pos + 1
continue
quote_end = substring.find('"', quote_start + 1)
if quote_end == -1:
start = end_pos + 1
continue
image_id = substring[quote_start + 1:quote_end]
image_ids.append(image_id)
start = end_pos + 1
return image_ids
def read_excel_data(filename_path, sheet_name=None):
try:
workbook = openpyxl.load_workbook(filename_path, data_only=False)
except FileNotFoundError:
logging.error(f"Error: The file '{filename_path}' was not found.")
return [], []
except openpyxl.utils.exceptions.InvalidFileException:
logging.error(f"Error: The file '{filename_path}' is not a valid Excel file.")
return [], []
try:
if sheet_name is not None:
sheet = workbook[sheet_name]
else:
sheet = workbook.active
except KeyError:
logging.error(f"Error: The sheet '{sheet_name}' does not exist in the workbook.")
return [], []
image_list = []
data = []
image_id_map = {}
# 获取列索引
header_row = next(sheet.iter_rows(min_row=1, max_row=1, values_only=True))
try:
image_col_index = header_row.index(pictcow)
id_col_index = header_row.index(travelcow)
except ValueError as e:
logging.error(f"Error: Column not found in the sheet. {e}")
return [], []
for row in sheet.iter_rows(min_row=2, values_only=True):
row_data = []
image_ids = []
card_id = None
for col_index, cell_value in enumerate(row):
if col_index == image_col_index and isinstance(cell_value, str) and '=_xlfn.DISPIMG(' in cell_value:
image_ids.extend(extract_image_id(cell_value))
elif col_index == id_col_index:
card_id = cell_value
row_data.append(cell_value)
data.append(row_data)
image_list.extend(image_ids)
#存储一个 card_id 和image_id的map,方便后面处理数据
if card_id and image_ids:
image_id_map[card_id] = image_ids[0] # 假设每个游历卡ID对应一个image_id
return data, image_list, image_id_map
#获取excel文件中图片id和图片路径的映射关系
def get_xml_id_image_map(xlsx_file_path):
try:
with zipfile.ZipFile(xlsx_file_path, 'r') as zfile:
with zfile.open('xl/cellimages.xml') as file:
xml_content = file.read()
with zfile.open('xl/_rels/cellimages.xml.rels') as file:
relxml_content = file.read()
except (zipfile.BadZipFile, FileNotFoundError) as e:
logging.error(f"Error: {e}")
return {}
root = ET.fromstring(xml_content)
namespaces = {
'xdr': 'http://schemas.openxmlformats.org/drawingml/2006/spreadsheetDrawing',
'a': 'http://schemas.openxmlformats.org/drawingml/2006/main'
}
name_to_embed_map = {}
for pic in root.findall('.//xdr:pic', namespaces=namespaces):
name = pic.find('.//xdr:nvPicPr/xdr:cNvPr', namespaces=namespaces).attrib['name']
embed = pic.find('.//xdr:blipFill/a:blip', namespaces=namespaces).attrib[
'{http://schemas.openxmlformats.org/officeDocument/2006/relationships}embed']
name_to_embed_map[name] = embed
root1 = ET.fromstring(relxml_content)
namespaces = {'r': 'http://schemas.openxmlformats.org/package/2006/relationships'}
id_target_map = {child.attrib['Id']: child.attrib.get('Target', 'No Target Found') for child in
root1.findall('.//r:Relationship', namespaces=namespaces)}
name_to_target_map = {name: id_target_map.get(embed, 'No Target Found') for name, embed in
name_to_embed_map.items()}
return name_to_target_map
#保存图片到指定目录,并获取excel单元格图片id与真实图片路径的映射关系
def save_images(xlsx_file_path, output_directory, new_map):
final_map = {}
try:
with zipfile.ZipFile(xlsx_file_path, 'r') as zfile:
zip_contents = set(zfile.namelist())
for key, image_path in new_map.items():
actual_image_path = f'xl/{image_path}'
if actual_image_path in zip_contents:
try:
with zfile.open(actual_image_path) as image_file:
image_content = image_file.read()
new_file_path = os.path.join(output_directory, f"{key}.png")
with open(new_file_path, 'wb') as new_file:
new_file.write(image_content)
# logging.info(f"Saved image {key} to {new_file_path}")
final_map[key] = new_file_path
except Exception as e:
logging.error(f"Error saving image {key}: {e}")
else:
logging.error(f"File {actual_image_path} (for key {key}) not found in the archive.")
except (zipfile.BadZipFile, FileNotFoundError) as e:
logging.error(f"Error: {e}")
# logging.info(f"Final Image Map: {final_map}")
return final_map
def output_id_image(xlsx_file_path, output_directory,sheet_name):
if not os.path.exists(xlsx_file_path):
logging.error(f"File {xlsx_file_path} does not exist.")
return
if not os.path.exists(output_directory):
os.makedirs(output_directory)
try:
data, image_list, image_id_map = read_excel_data(xlsx_file_path, sheet_name)
name_to_target_map = get_xml_id_image_map(xlsx_file_path)
except Exception as e:
logging.error(f"Error occurred while processing Excel or XML data: {e}")
return
new_map = {key: name_to_target_map.get(key, 'No Target Found') for key in image_list}
# logging.info(f"new Image Map: {new_map}")
final_map = save_images(xlsx_file_path, output_directory, new_map)
# 生成新的 map{key = image_id_map[key]: value=final_map[value]}
new_combined_map = {}
for card_id, image_id in image_id_map.items():
if image_id in final_map:
new_combined_map[card_id] = pictUpload.upload_image(final_map[image_id])
logging.info(f"New Combined Map: {new_combined_map}")
return new_combined_map
上述代码中,由于我需要获得excel中单独一列card_id和图片上传服务端后返回的图片id对应map表。故,我先调用save_images函数,获取excel单元格图片id与真实图片路径的映射关系,又调用了一个单独的文件上传接口pictUpload.upload_image(),获取图片上传后接口返回的pict_id,生成一个新的map new_combined_map。
over!

















 1262
1262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









