





目录
一、深度学习
正如我们在第六节课中说的那样,深度学习就是不断的增加一个神经网络的隐藏层神经元,让输入的数据被这些神经元不断的抽象和理解,最后得到一个具有泛化能力的预测网络模型。而我们一般把隐藏层超过三层的网络也就称之为深度神经网络。
如此说来,深度学习这个听起来相当高端大气上档次,尤其是近些年来被媒体包装的十分具有神秘感的名字,瞬间你就觉得没有那么的道貌岸然。至于网络中每个节点到底在理解什么,很难用精确的数学手段去分析,我们唯一能做的事情就是收集数据,送入数据,进行训练,然后期待结果。当然,也不是说我们对一个深度神经网络完全不可把控,起码我们能在比如学习率、激活函数、神经元的层数和数量等等方面调节神经网络的大致工作行为,俗称调参。
二、Tensorflow
我们以著名的Tensorflow游乐场为例:
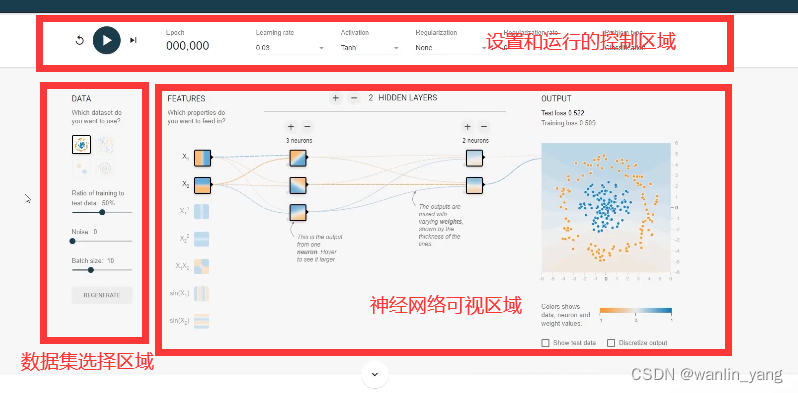 1.我们先选择第三个数据集,调参模拟训练一下:
1.我们先选择第三个数据集,调参模拟训练一下:
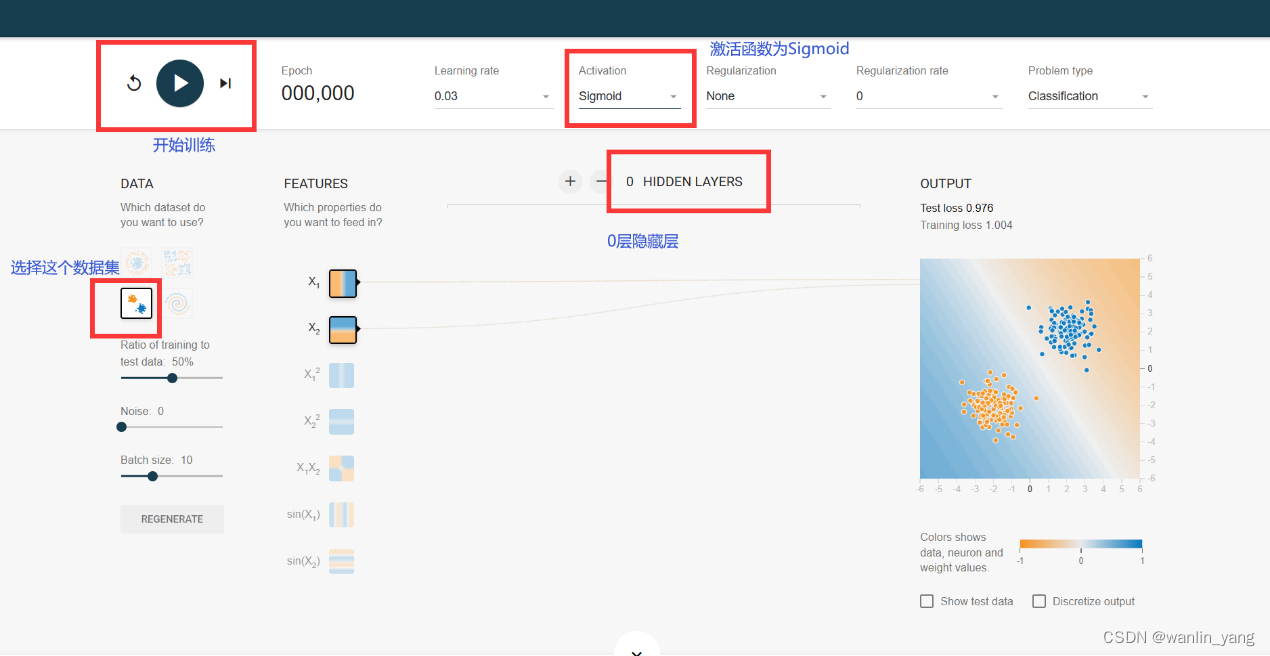
分类的方式我们也说过,那就是让预测函数曲面的0.5等高线把它们分割开来。我们知道对于这种线性可分的问题,使用单个的神经元就可以完成分类,所以我们点击隐藏层的设置区域的减号,把隐藏层减少到0层,也就是说只保留一个输出层的神经元。好的,我们再设置一下神经元的激活函数,这里它默认使用的是双曲正切tanh函数,这个激活函数目前为止我们还没有接触道,那么我们还是选择熟悉的老伙计sigmoid函数,学习率设置为0.03,然后点击运行按钮运行一下,果然很轻松的就让输出预测曲面的0.5等高线完美的分割了两类豆豆。
训练结果:
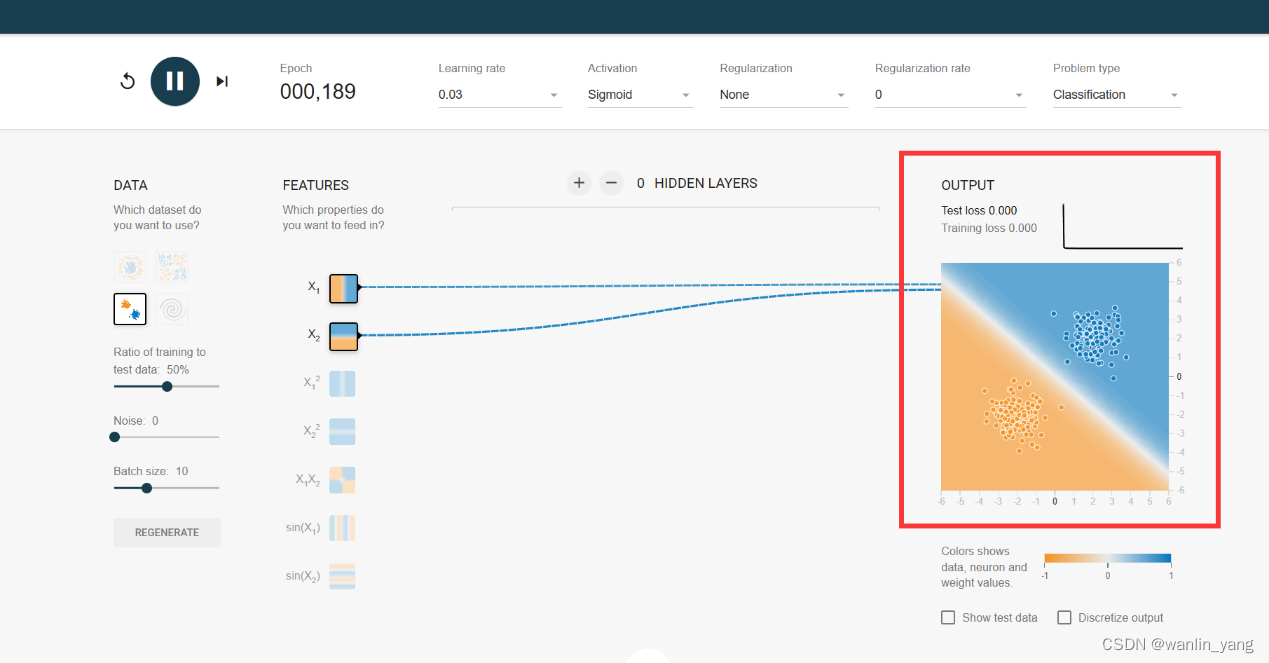
2.我们再试试第一个数据集:
我们思考,这个需要几个神经元来分类呢?
我们定性分析一下,还是看图说话,一个神经元是一条直线,三个神经元形成三条直线刚好形成闭合的形状。
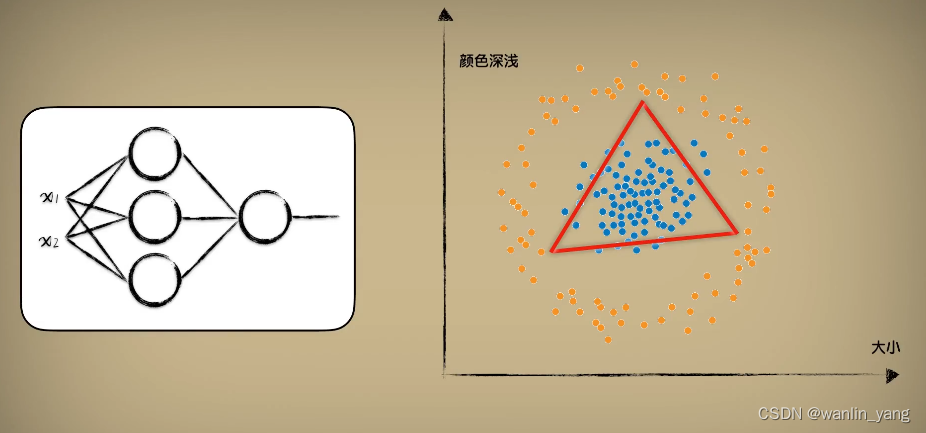
把这三个神经元的计算结果再通过一个输出层的神经元进行汇合,通过sigmoid的激活函数修饰一下之后就可以了。如此也就可以解决这种圈圈分布数据的分类问题,圈内是一类,圈外是另一类。我们点击隐藏层设置区域的加号,把隐藏层增加到1层,再点击这一层的设置区域上的加号,把这一层的神经元数量增加到3个,如此就得到了一个有3个神经元的1层隐藏层,学习率还是0.03,不必修改,运行一下,最后输出的预测曲面的0.5等高线也完美的分割出了这两枚豆豆。
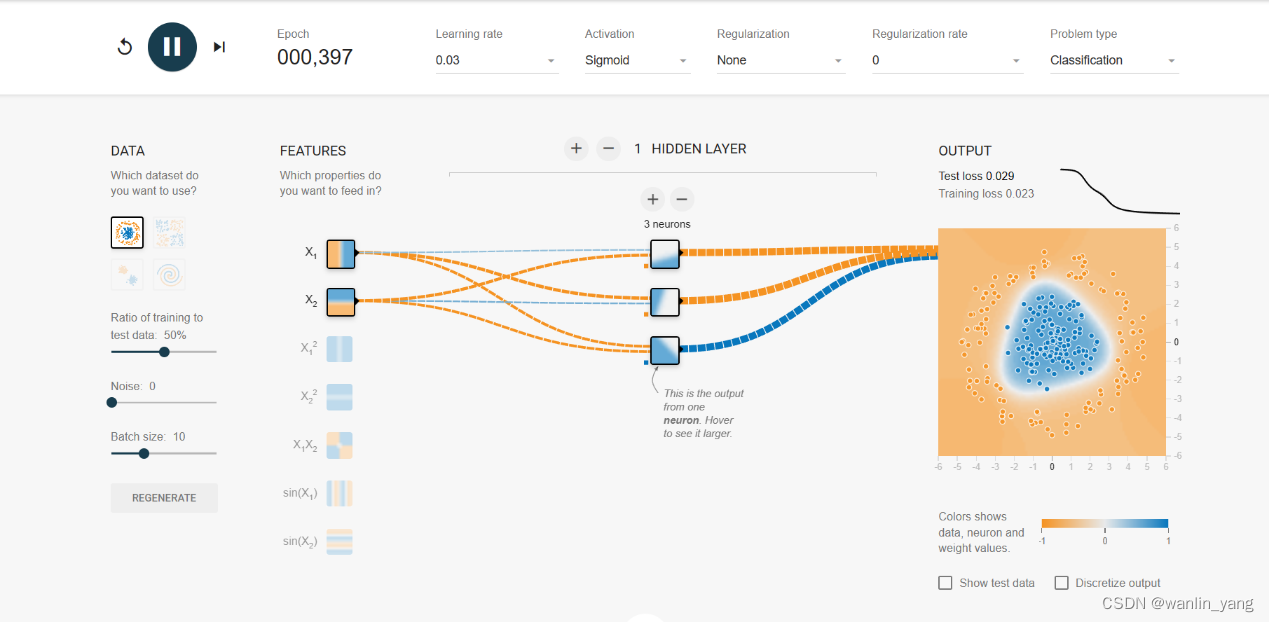
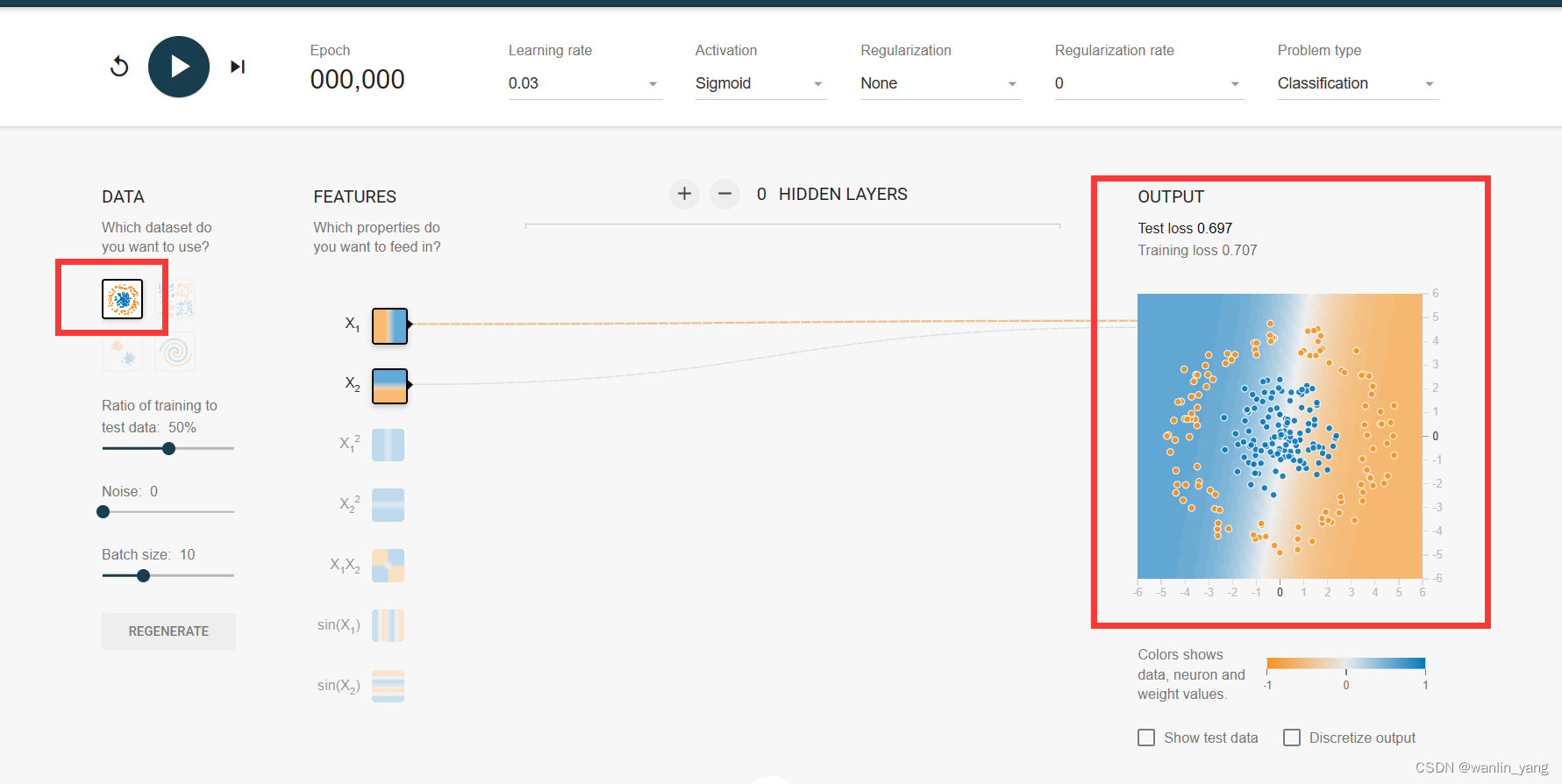
3.再来看看第二个数据集:
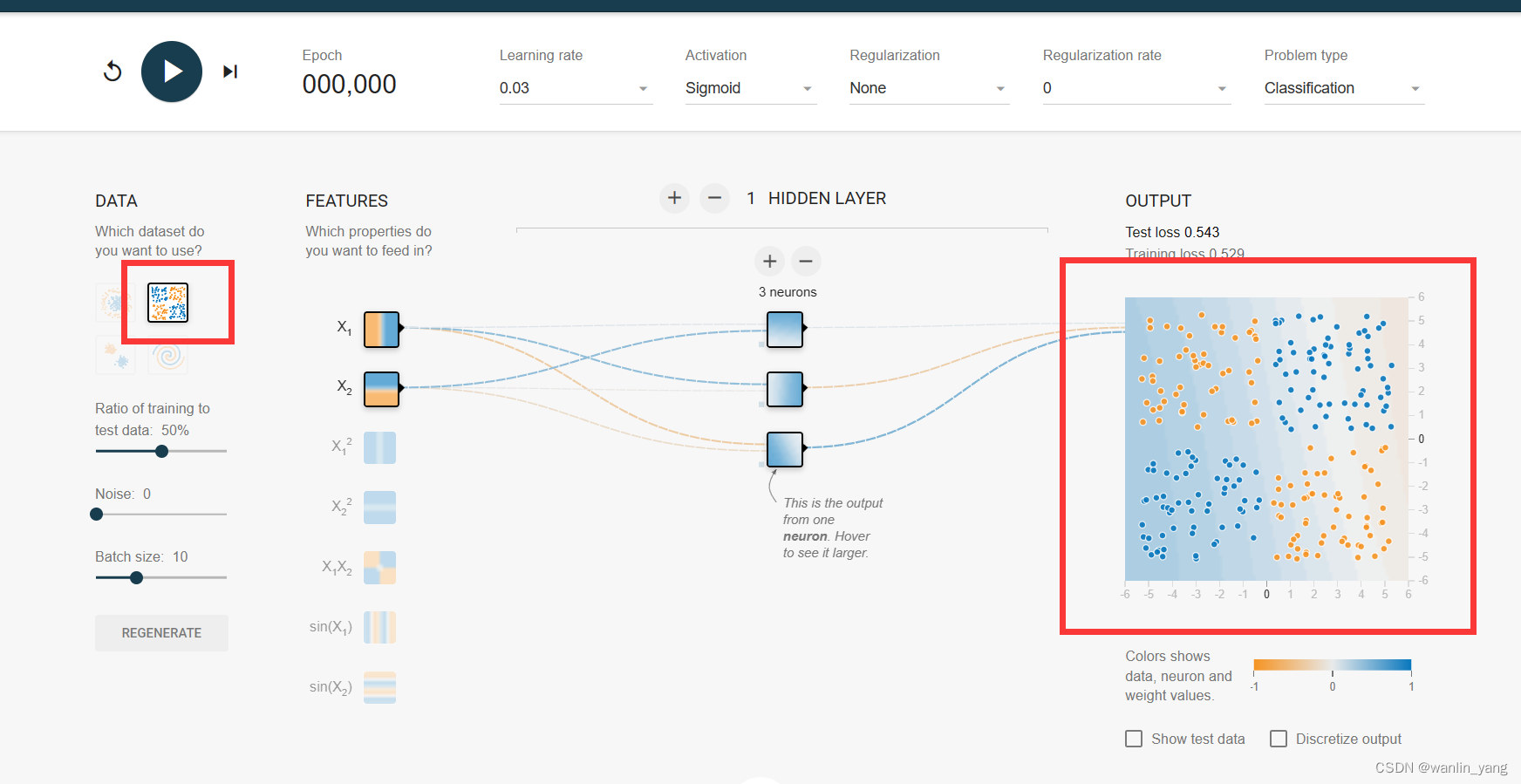
异或:这实际上就是在感知器最初发展阶段困扰研究人员很多年的一个问题。当时为了证明感知器模型并没有太大的卵用,于是人们提出了一种在计算机领域非常常见的问题,异或。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 309
309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









