




1 官方文档地址
https://gitee.com/paddlepaddle/PaddleOCR/blob/main/docs/version3.x/algorithm/PP-OCRv5/PP-OCRv5.md#%E4%BA%94%E9%83%A8%E7%BD%B2%E4%B8%8E%E4%BA%8C%E6%AC%A1%E5%BC%80%E5%8F%91
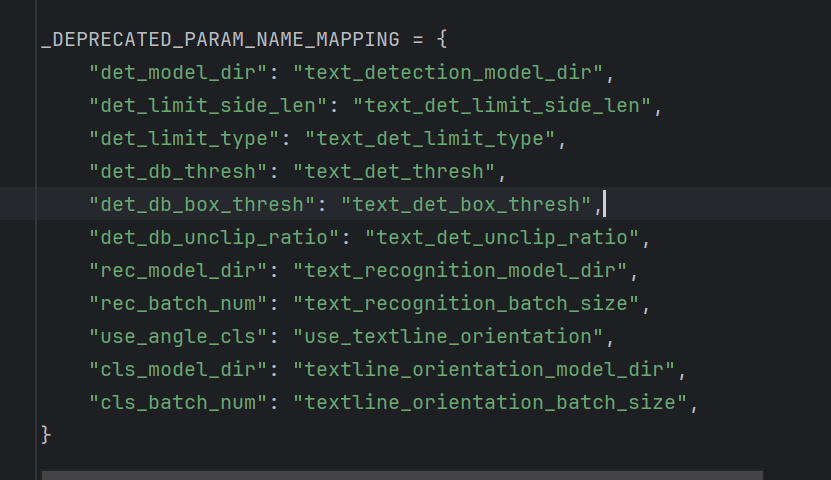
2 使用PP-OCRv5,不同的模型执行效率不一样。可以查看官网测试结果。网上给出的都是旧属性配置,需要使用最新的配置。新旧属性映射如下:
self.ocr = PaddleOCR(
use_doc_orientation_classify=False, # 禁用文档级方向分类
use_doc_unwarping=False, # 禁用文档图像扭曲矫正
use_textline_orientation=False, # 是否使用文本行方向功能。如果设置为None, 将默认使用产线初始化的该参数值,初始化为True。
# doc_unwarping_model_dir="C:\\Users\\PC\\.paddlex\\official_models\\UVDoc", # 矫正模型
# text_detection_model_dir="C:\\Users\\PC\\.paddlex\\official_models\\PP-OCRv5_server_det", # 检测模型
# text_recognition_model_dir="C:\\Users\\PC\\.paddlex\\official_models\\PP-OCRv5_server_rec", # 识别模型
lang='ch',
ocr_version="PP-OCRv5",
)
模型从哪下载呢?会自动下载保存到本地的。模型路径配置优先级:如果模型名称和路段都没配,默认会使用PP-OCRv5_server_det和PP-OCRv5_server_rec下载到本地,如C:\Users\PC.paddlex\official_models目录中(可以看控制台),如果配置了本地模型lang和ocr_version会失效,优先使用本地配置的模型;
self.ocr = PaddleOCR(
use_doc_orientation_classify=False, # 禁用文档级方向分类
use_doc_unwarping=False, # 禁用文档图像扭曲矫正
use_textline_orientation=False, # 是否使用文本行方向功能。如果设置为None, 将默认使用产线初始化的该参数值,初始化为True。
doc_unwarping_model_dir="C:\\Users\\PC\\.paddlex\\official_models\\UVDoc", # 矫正模型
text_detection_model_dir="C:\\Users\\PC\\.paddlex\\official_models\\PP-OCRv5_server_det", # 检测模型
text_recognition_model_dir="C:\\Users\\PC\\.paddlex\\official_models\\PP-OCRv5_server_rec", # 识别模型
lang='ch',
ocr_version="PP-OCRv5",
)
如果想使用mobile模型,笔记本测试使用这样效果更高些,但是精度会下降些,需要配置模型地址和模型名称,如果只配置了模型名称会自动下载;
self.ocr = PaddleOCR(
use_doc_orientation_classify=False, # 禁用文档级方向分类
use_doc_unwarping=False, # 禁用文档图像扭曲矫正
use_textline_orientation=False, # 是否使用文本行方向功能。如果设置为None, 将默认使用产线初始化的该参数值,初始化为True。
doc_unwarping_model_dir="C:\\Users\\PC\\.paddlex\\official_models\\UVDoc", # 矫正模型
text_detection_model_name="PP-OCRv5_mobile_det", # 检测模型 配了模型名称,不配地址_dir会自动下载模型
text_recognition_model_name="PP-OCRv5_mobile_rec", # 识别模型
text_detection_model_dir="C:\\Users\\PC\\.paddlex\\official_models\\PP-OCRv5_mobile_det", # 检测模型
text_recognition_model_dir="C:\\Users\\PC\\.paddlex\\official_models\\PP-OCRv5_mobile_rec", # 识别模型
text_det_limit_side_len = 900,#图像预处理时目标尺寸的参数,默认值为736像素。该参数决定了图像调整后的短边长度,若图像尺寸较小,建议将其调整为960像素以提升识别精度
)

















 5463
5463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









