



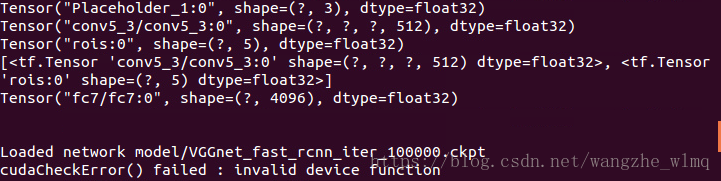
先将出现的问题截图,上图所示为我遇见的错误。
我在服务器上(ubuntu14.04),运行smallcorgi/Faster-RCNN的tensorflow代码时候出现的问题,我的显卡是Tesla K40。
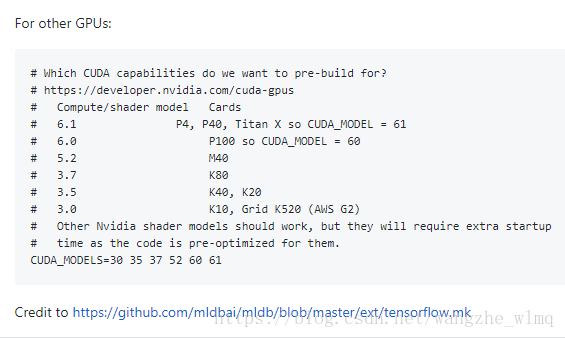
在百度后发现根本没有切实可行的方法,最后还是使用Google解决了问题,发现在运行代码时候在lib文件夹下面执行make操作的时候需要将make.sh文件进行修改,将arch参数从sm_37改为sm_35。为大家附上参数列表。
 本文记录了作者在Ubuntu 14.04服务器上运行smallcorgi/Faster-RCNN的TensorFlow代码时遇到的错误,并详细介绍了如何通过修改make.sh文件中的arch参数来解决编译问题。
本文记录了作者在Ubuntu 14.04服务器上运行smallcorgi/Faster-RCNN的TensorFlow代码时遇到的错误,并详细介绍了如何通过修改make.sh文件中的arch参数来解决编译问题。
先将出现的问题截图,上图所示为我遇见的错误。
我在服务器上(ubuntu14.04),运行smallcorgi/Faster-RCNN的tensorflow代码时候出现的问题,我的显卡是Tesla K40。
在百度后发现根本没有切实可行的方法,最后还是使用Google解决了问题,发现在运行代码时候在lib文件夹下面执行make操作的时候需要将make.sh文件进行修改,将arch参数从sm_37改为sm_35。为大家附上参数列表。
您可能感兴趣的与本文相关的镜像

TensorFlow-v2.15
TensorFlow 是由Google Brain 团队开发的开源机器学习框架,广泛应用于深度学习研究和生产环境。 它提供了一个灵活的平台,用于构建和训练各种机器学习模型


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




















 342
342





