




 本文详细介绍如何利用AWS的Kinesis、EMR、Quicksight和Elasticsearch等服务进行实时流处理、批处理分析、数据可视化及检索,通过实例搭建和清理来掌握完整的大数据处理流程。
本文详细介绍如何利用AWS的Kinesis、EMR、Quicksight和Elasticsearch等服务进行实时流处理、批处理分析、数据可视化及检索,通过实例搭建和清理来掌握完整的大数据处理流程。
实验介绍
本次实战内容将教大家如何使用 AWS 的大数据和数据湖的相关服务和组件,顺利完成大数据的收集,存储,处理,分析和可视化的完整的流程,主要会介绍以下几个 AWS 大数据服务:
- Lab1:实时流数据处理,基于 Kinesis 产品家族实现
- Lab2:批量数据处理,基于 EMR(Spark) 实现
- Lab3:数据可视化,基于 Quicksight + Athena 实现
- Lab4:数据实时检索,基于 Elasticsearch 实现
- Lab5:数据仓库构建和数据可视化展现,基于 Redshift + Quicksight 实现
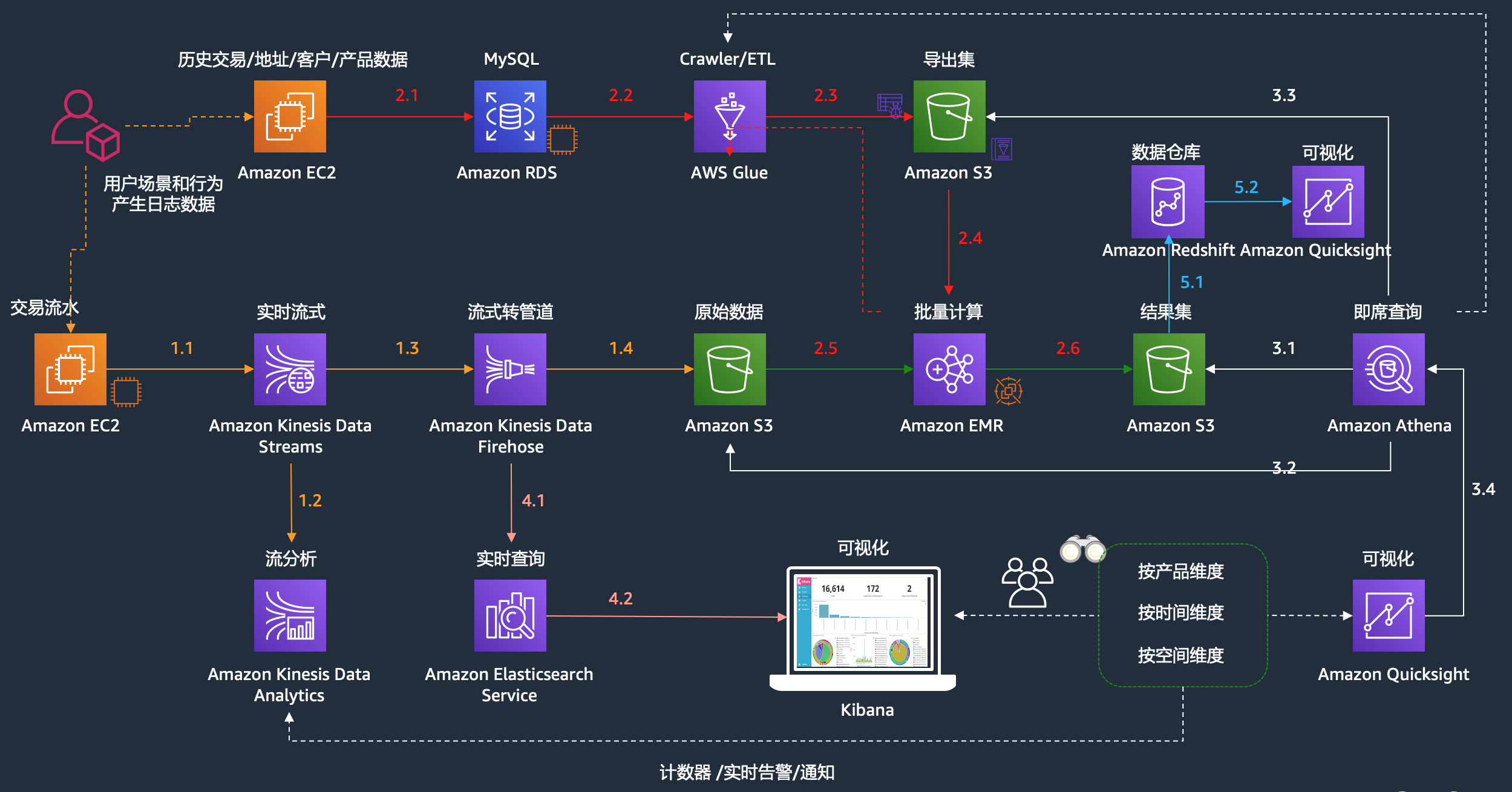
为了更好的模拟实际的业务需求,我们构建了一个数据库(模拟历史数据,或者部分客户已经存在的ODS库),我们构建了实时数据流(模拟例如电商,web等的点击流),我们构建了流式实时分析和批量分析的平台以及对应的可视化展现和数据实时检索的平台。如下是此次实验的整体的架构图:
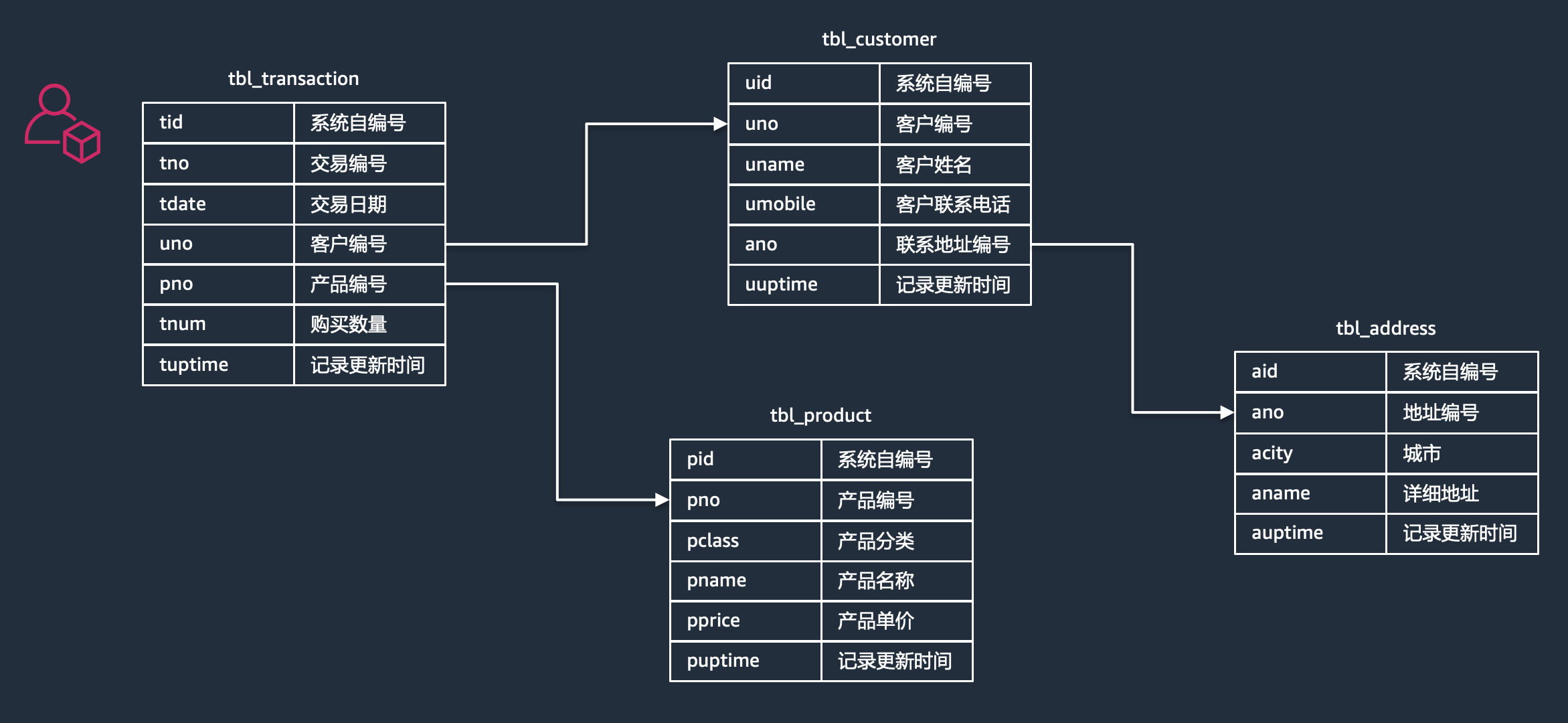
为了让大家对数据结构有个更清晰的认识,我们把RDS(关系型数据库)里面的数据表结构做了一层抽象,供参考:
实验准备
为了顺利完成全部的动手实验,需要做如下准备工作,所有的资源创建在了 AWS us-east-1 这个区域:
| 步骤 | 准备环境 | 准备内容描述 |
|---|---|---|
| 01 | 账号配置 | 熟悉AWS提供的账号和登录方式,并配置对应安全选项 |
| 02 | 部署EC2 | 部署一个EC2(Linux)用于操作的客户端并学会远程登录 |
| 03 | 配置KDS | 配置 Kinesis Data Streams 实时数据流用于产生数据 |
| 04 | 部署RDS | 配置数据库(在实验环境中,理解为历史数据或者ODS环境) |
| 05 | 部署EMR | 部署大数据平台 EMR |
| 06 | 部署ES | 部署实时分析平台 Elasticsearch |
账号配置
IAM(Identity and Access Management)是AWS和用户,权限以及认证等安全相关的服务,此处我们配置两个角色,一个是 EC2 访问云中一些资源使用的角色(ec2-role),还有一个是 Glue 访问云中资源使用的角色(glue-role)
为 EC2 配置角色权限
通过如下方式打开IAM控制台
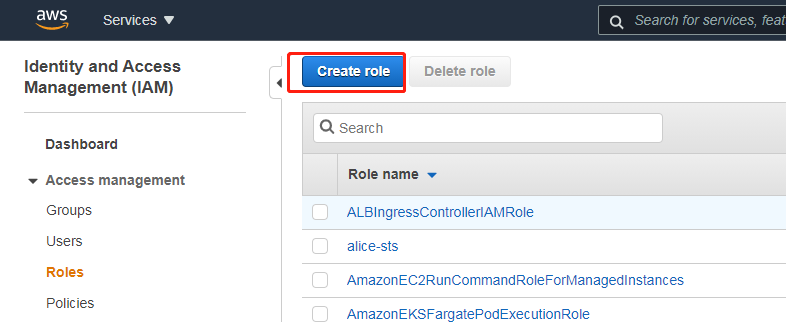
点击左边的“Role”菜单,然后选择“Create role”
在 AWS service 里面选择 EC2
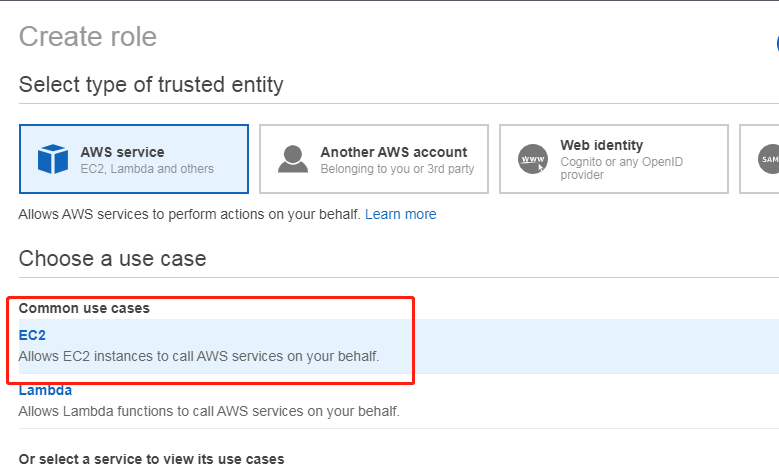
在设置权限的页面,点击“直接附加现有策略”,添加 AdministratorAccess 和 IAMFullAccess 两个权限
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 497
497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









