




 本文介绍了Poly-encoder模型,这是一种介于Bi-encoder和Cross-encoder之间的方法,旨在平衡预测精度和速度。Bi-encoder通过分别编码输入和标签,适用于大量候选标签的快速检索,而Cross-encoder通过全局交互获得高精度但速度慢。Poly-encoder采用部分交叉注意力机制,只对标签进行一次编码,从而在保持高效的同时提高了准确性。实验结果显示,Poly-encoder在多个任务上表现优于Bi-encoder,接近Cross-encoder,且在大规模候选标签情况下仍能保持快速推理,是实时应用的理想选择。
本文介绍了Poly-encoder模型,这是一种介于Bi-encoder和Cross-encoder之间的方法,旨在平衡预测精度和速度。Bi-encoder通过分别编码输入和标签,适用于大量候选标签的快速检索,而Cross-encoder通过全局交互获得高精度但速度慢。Poly-encoder采用部分交叉注意力机制,只对标签进行一次编码,从而在保持高效的同时提高了准确性。实验结果显示,Poly-encoder在多个任务上表现优于Bi-encoder,接近Cross-encoder,且在大规模候选标签情况下仍能保持快速推理,是实时应用的理想选择。
原文链接:https://openreview.net/attachment?id=SkxgnnNFvH&name=original_pdf
ICLR2020
概述
问题
预测句子对之间关系一般有两种方法:cross-encoders(通过自注意力从全局实现编码)Bi-encoder(对输入的context和label分别进行编码),前者由于每次都需要将input和label进行concate后进行编码,因此虽然可以得到更好的效果,但是其速度会很慢。
IDEA
作者想基于精度和速度之间找到一个balance,提出了Poly-encoder,将label进行分别编码后,再与能够表示全局特征的input向量去计算注意力,从而使得到比Bi-encoder更高的精确度以及比Cross-encoder更快的速度。
方法
Bi-encoder
模型结构如下图所示:
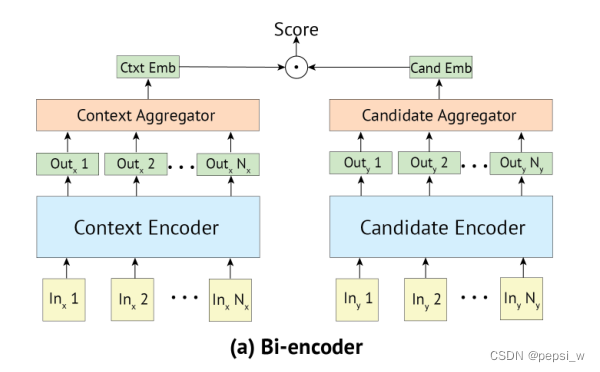
首先将输入的context和candidate label分别送入到两个transformer中,得到对应的向量表征,然后通过函数red(.)将序列向量投影为一个向量,最后进行点积得到最终预测分数。如以下公式所示:
![]()
![]()
其中T1(x)、T2(x)分别表示两个预训练transformer的输出,red(.)函数将序列向量投影为一个向量。对于red函数,作者考虑了三种方法:1)直接使用transformer的第一个输出(也就是特殊token[S],这里作者将输入的contex和label都插入了特殊token[S]);2)取所有输出的额平均值;3)取前m个输出的平均值;通过实验证明,方法1的效果更好,因此作者选用特殊token[S]的输出来代表整个句子。
在对已知候选标签进行检索的情况下,Bi-encoder允许提前计算所有的候选embedding,在计算ytext后,只需要将其与每个候选embedding进行点乘就能得到对应的结果。这也是Bi-encoder的速度快的原因。
Cross-encoder
模型结构如下图所示:
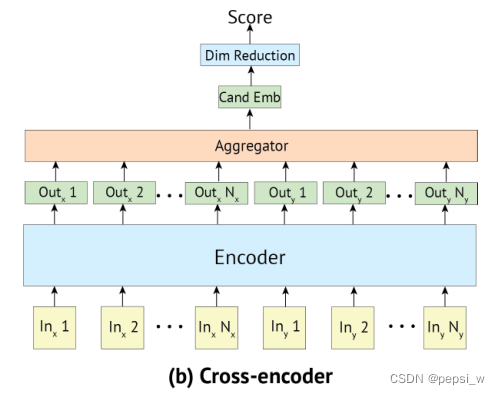
cross-encoder允许输入文本与标签之间更充分的交互。首先将带有特殊token[S]的context和candidate进行concate成一个向量,并且将transformer的第一个输出向量作为他们的embedding。最后使用一个线性层W,来将yctxt,cand这个向量还原为一个标量,得到每个candidate的得分。如以下公式表示:
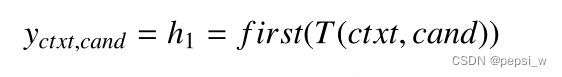
![]()
由于context和candidate是在一个transformer中,有比Bi-encoder更丰富的交互机制,通过注意力机制的计算,能够生成candidate-sensitive的context表征。也正是因为每个candidate都要和context进行concatenate一起计算,因此不能和Bi-encoder一样,重复的使用candidate的embedding,这也导致该方法在较多candidate的情况下速度很慢。
Ploy-encoder
ploy-encoder的结构就是结合这两个模型的优点,为了保持较快的推理速度,candidate同Bi-encoder中一样使用一个向量来进行表示,同时将context和candidate一起进行attention,得到更多的信息。整体结构如下图所示:
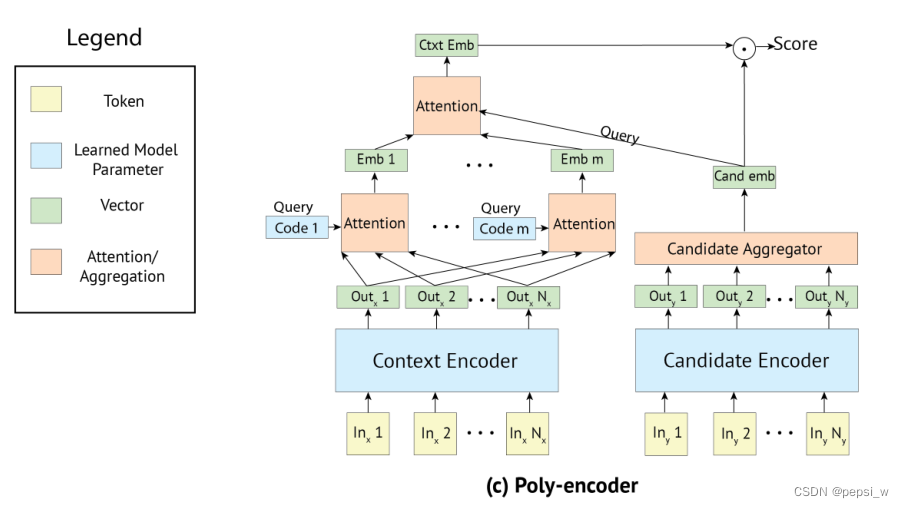
该结构分别使用两个transformer用于context和label的编码,candidate被编码成一个单一的向量,因此poly-encoder就能使用缓存的candidate。context由于通常比label要长,由m个向量进行表示(
....
),然后与candidate的embedding做attention,最后使用
和
的点积作为预测的分数。
![]()
其中通过学习(随机初始化后进行学习)m个上下文编码(
...
)来表示,即 ci 用来抽取第 i 个隐层来表示
:
![]()
实验
作者使用测试表征:Recall@k,表示其中每个测试例子有C个可能的候选者可供选择,简称为R@k/C。
作者负样本的多少进行了实验,结果如下:

可以看出在更大规模的batch下(即更多负样本的情况下)能获得更好的性能,对于其他任务,由于数据集中存在较长的序列会使用更多的内存,因此作者在Bi-encoder中,使用batch=256,将其他batch中的元素视为负样本;cross-encoder的计算量更大,其batch设置为16,并从训练集中提供随机负样本。
作者在多个任务上对Bi、Cross、Poly三个模型进行了比较,实验结果如下:
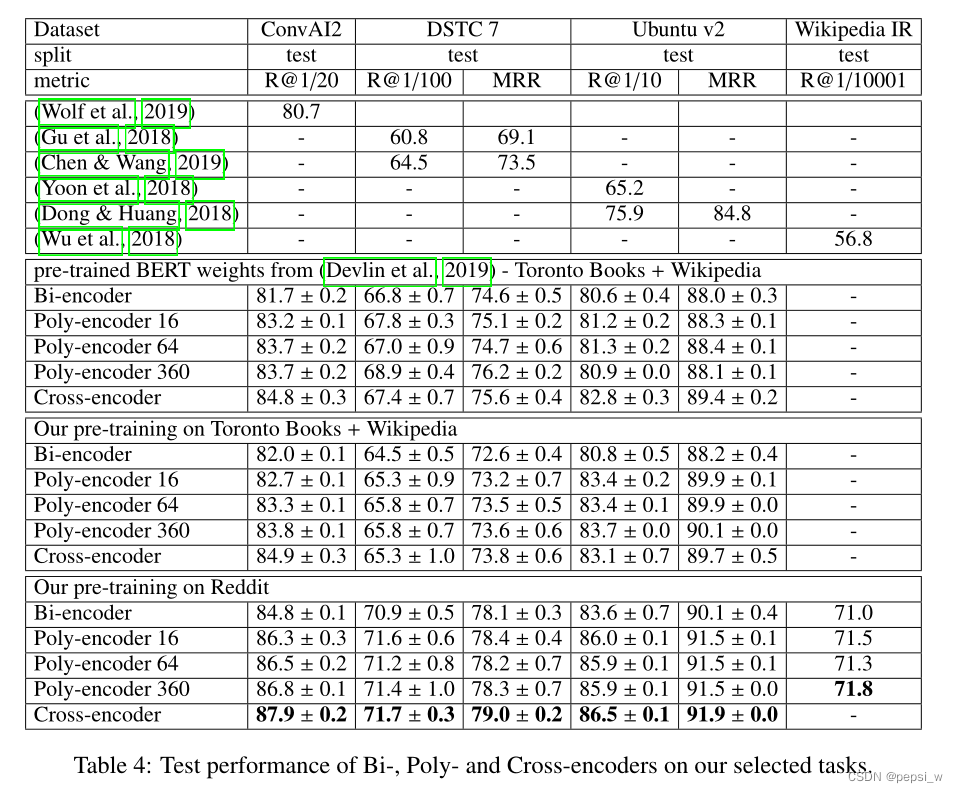
在前三个任务中,Bi-encoder和cross-encoder都比之前提出的模型表现更好,总体来说cross-encoder在三个对话任务上的表现超过了以前的所有方法。ploy-encoder16表示上下文向量m=16。可以看出ploy-encoder的表现比Bi-encoder更好,与cross-encoder稍微差一点。
作者对多个模型在ConvAI2上从C个可能的候选人中预测下一个对话话语的平均时间进行了对比,实验结果如下:
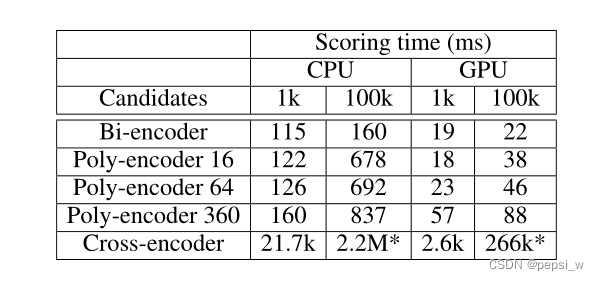
当模型只有1000个candidate需要考虑时,Bi-encoder和Poly-encoder之间的时间差异是相当小的。当考虑到10万个候选者时,差异就更明显了,这是一个更现实的设置,因为我们看到Poly-encoder变体的速度下降了5-6倍。cross-encoder比Bi-encoder和ploy-encoder慢2个数量级,使得它无法用于实时推理。因此,考虑到其理想的性能和速度权衡,Poly-encoders是首选方法。
总结
本文作者对于深度双向transformer在选择任务上提出了一种新结构和一种新的预训练策略,ploy-encoder提出了一种context和label candidate进行融合的机制,同时保持了预先计算每个candidate的表征,使得在生产中可以快速实时的推理,在准确性和速度中找到了一个平衡。在训练这些结构方面,作者表明与下游任务更相关的预训练策略会有更好的一个效果。

















 650
650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









