




 本文介绍了图像增广在深度学习中的应用,通过左右翻转、上下翻转、随机剪裁和颜色改变等方法扩大训练集,增强模型的泛化能力。在CIFAR-10数据集上进行实验,展示了如何使用这些增广技术进行训练,并比较了不同增广策略对模型测试精度的影响。
本文介绍了图像增广在深度学习中的应用,通过左右翻转、上下翻转、随机剪裁和颜色改变等方法扩大训练集,增强模型的泛化能力。在CIFAR-10数据集上进行实验,展示了如何使用这些增广技术进行训练,并比较了不同增广策略对模型测试精度的影响。
图像增广在对训练图像进行一系列的随机变化之后,生成相似但不同的训练样本,从而扩大了训练集的规模。并且随机改变训练样本可以减少模型对某些属性的依赖,从而提高模型的泛化能力。
6.1 常用的图像增广方法
左右翻转:torchvision.transforms.RandomHorizontalFlip(p=0.5)#默认以p=0.5的概率进行左右翻转
上下翻转:transforms.RandomVerticalFlip(p=0.5)
随机剪裁:transforms.RandomResizedCrop(size, scale=(0.1, 1), ratio=(0.5, 2))#
改变颜色:torchvision.transforms.ColorJitter( brightness, contrast, saturation, hue)
如需使用多种增广方式:
torchvision.transforms.Compose([ aug1, aug2, aug3])
6.2 使用图像增广进行训练
这里使用CIFAR-10数据集,是只包含imge-net中10个种类的子数据集。该数据集中对象的颜色和大小差异比fashion_mnist更明显。
!pip install git+https://github.com/d2l-ai/d2l-zh@release # installing d2l
!pip install matplotlib_inline
!pip install matplotlib==3.0.0
%matplotlib inline
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
all_images = torchvision.datasets.CIFAR10(train=True,root="data",download=True)
d2l.show_images([all_images[i][0] for i in range(12)],3,4,scale=1.5)
color_aug = torchvision.transforms.ColorJitter(brightness=0.5,contrast=0.5,saturation=0.5,hue=0.5)
#这里我使用了随机左右翻转和改变颜色
train_augs = torchvision.transforms.Compose(
[torchvision.transforms.RandomHorizontalFlip(),
color_aug,torchvision.transforms.ToTensor()])
test_augs = torchvision.transforms.Compose(
[torchvision.transforms.ToTensor()])
def load_cifar10(is_train,augs,batch_size):
dataset = torchvision.datasets.CIFAR10(
root='data',train=is_train,transform=augs,download=True)#transform即用什么方法来进行图形增广
dataloader = torch.utils.data.DataLoader(dataset,batch_size=batch_size)
return dataloader
def train_batch_ch13(net,X,y,loss,trainer,devices):
if isinstance(X,list):
X = [x.to(devices[0]) for x in X]
else:
X = X.to(devices[0])
y = y.to(devices[0])
net.train()
trainer.zero_grad()
pred = net(X)
l = loss(pred,y)
l.sum().backward()
trainer.step()
train_loss_sum = l.sum()
train_acc_sum = d2l.accuracy(pred,y)
return train_loss_sum, train_acc_sum
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices=d2l.try_all_gpus()):
"""用多GPU进行模型训练"""
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0])#并行
for epoch in range(num_epochs):
# 4个维度:储存训练损失,训练准确度,实例数,特点数
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = train_batch_ch13(
net, features, labels, loss, trainer, devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[3],
None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
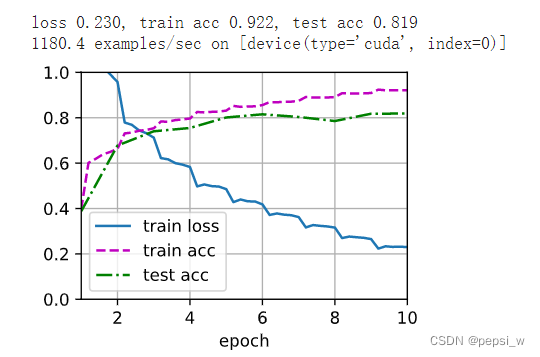
print(f'loss {metric[0] / metric[2]:.3f}, train acc '
f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on '
f'{str(devices)}')
print('time:',timer.sum())
from torch.nn.init import xavier_uniform_
batch_size=256
devices = d2l.try_all_gpus()
net = d2l.resnet18(10,3)
def init_weights(m):
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init,xavier_uniform_(m.weight)
net.apply(init_weights)
def train_with_data_aug(train_augs,test_augs,net,lr=0.001):
train_iter = load_cifar10(True,train_augs,batch_size)
test_iter = load_cifar10(False,test_augs,batch_size)
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.Adam(net.parameters(),lr=lr)
train_ch13(net,train_iter,test_iter,loss,trainer,10,devices)
train_with_data_aug(train_augs,test_augs,net)
运行结果,我这里用了两种图像增广 咋测试精度还没有老师只用了一种的高呢?

















 1113
1113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









