






深入剖析JDK1.7 ConcurrentHashMap:扩容机制与size()方法的精妙设计
一、ConcurrentHashMap在JDK1.7中的核心架构
在深入分析扩容机制和size()方法之前,我们需要先了解JDK1.7中ConcurrentHashMap的整体架构。它采用了一种分段锁(Segment Locking) 的设计思想,将整个哈希表划分为多个Segment(默认为16个),每个Segment本质上是一个独立的哈希表,拥有自己的锁。这种设计大幅提升了并发性能,因为不同的线程可以同时访问不同的Segment。
核心数据结构:
-
Segment数组:每个Segment继承自ReentrantLock
-
HashEntry数组:每个Segment内部维护的哈希桶数组
-
modCount:每个Segment的修改次数计数器
-
count:每个Segment中元素的数量
🔥🔥🔥(免费,无删减,无套路):java swing管理系统源码 程序 代码 图形界面(11套)」
链接:https://pan.quark.cn/s/784a0d377810
提取码:见文章末尾
🔥🔥🔥(免费,无删减,无套路): Python源代码+开发文档说明(23套)」
链接:https://pan.quark.cn/s/1d351abbd11c
提取码:见文章末尾
🔥🔥🔥(免费,无删减,无套路):计算机专业精选源码+论文(26套)」
链接:https://pan.quark.cn/s/8682a41d0097
提取码:见文章末尾
🔥🔥🔥(免费,无删减,无套路):Java web项目源码整合开发ssm(30套)
链接:https://pan.quark.cn/s/1c6e0826cbfd
提取码:见文章末尾
🔥🔥🔥(免费,无删减,无套路):「在线考试系统源码(含搭建教程)」
链接:https://pan.quark.cn/s/96c4f00fdb43
提取码:见文章末尾
二、Segment级别的扩容机制详解
2.1 触发扩容的时机
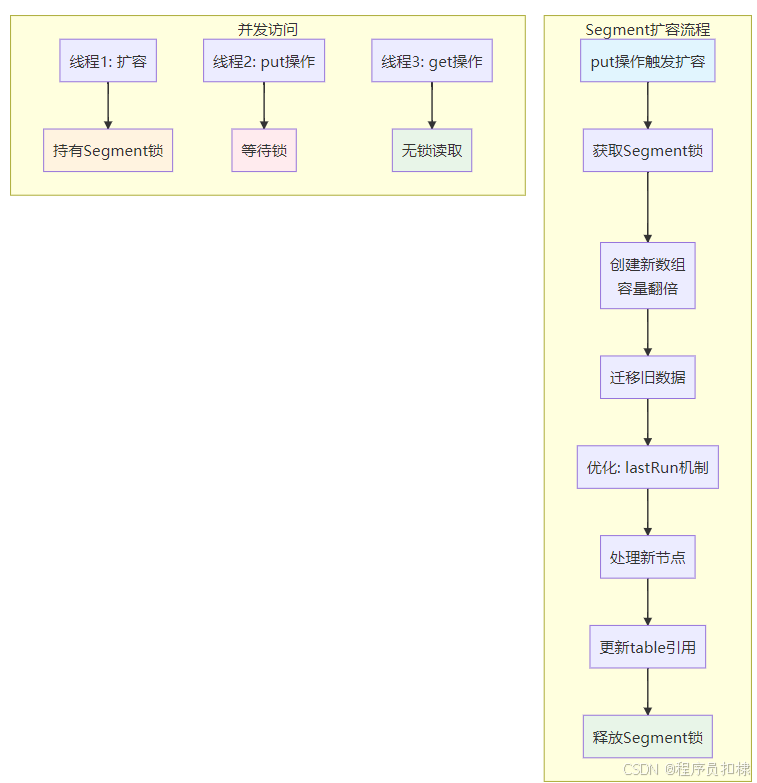
扩容发生在put操作中,当向某个Segment插入新元素时,如果发现当前Segment中的元素数量超过了阈值(容量×负载因子,默认0.75),就会触发扩容。重要的是,扩容是以Segment为单位的,不同Segment的扩容可以并行进行。
2.2 扩容过程源码分析
让我们深入源码,看看扩容的具体实现(关键步骤已添加注释):
void rehash(HashEntry<K,V> node) {
// 1. 保存旧的HashEntry数组
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
// 2. 计算新容量:翻倍
int newCapacity = oldCapacity << 1;
// 3. 计算新的阈值
threshold = (int)(newCapacity * loadFactor);
// 4. 创建新的HashEntry数组
HashEntry<K,V>[] newTable = (HashEntry<K,V>[]) new HashEntry[newCapacity];
// 5. 计算掩码,用于确定元素在新数组中的位置
int sizeMask = newCapacity - 1;
// 6. 迁移旧数据到新数组
for (int i = 0; i < oldCapacity; i++) {
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
int idx = e.hash & sizeMask;
// 处理链表只有一个节点的情况
if (next == null)
newTable[idx] = e;
else {
// 处理链表有多个节点的情况
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
for (HashEntry<K,V> last = next; last != null; last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
newTable[lastIdx] = lastRun;
// 复制剩余的节点
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
// 7. 处理新插入的节点
int nodeIndex = node.hash & sizeMask;
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
// 8. 更新Segment的table引用
table = newTable;
}
2.3 扩容机制的优化技巧
JDK1.7的扩容实现中有一个精妙的优化:lastRun机制。在迁移链表时,它会寻找链表中最后一段连续位置相同的节点,将这段节点整体迁移,而不是逐个复制。这减少了新建HashEntry对象的数量,提高了性能。
2.4 并发控制
扩容过程中,Segment是加锁的。这意味着:
-
同一时刻,一个Segment只能有一个线程执行扩容
-
其他线程的put/remove操作会被阻塞,直到扩容完成
-
读操作(get)可以继续进行,因为读操作不加锁
这种设计在保证线程安全的同时,最大限度地减少了锁的竞争。
三、size()方法的精妙设计
3.1 为什么size()方法不直接加锁?
如果直接加锁遍历所有Segment,需要按顺序获取所有Segment的锁。这会导致:
-
长时间持有锁:遍历所有Segment需要时间,期间会阻塞所有写操作
-
死锁风险:需要按固定顺序获取锁,但其他线程可能以不同顺序获取锁
-
性能低下:即使没有并发修改,也需要付出加锁的开销
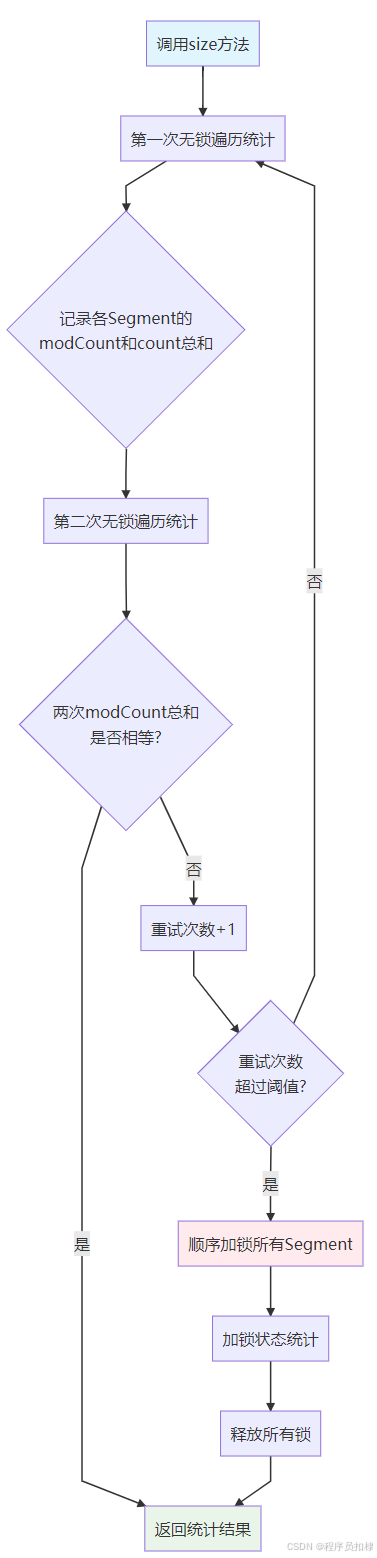
3.2 两次无锁统计策略
JDK1.7采用了一种"先乐观,后悲观"的策略:
public int size() {
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // 是否溢出(超过Integer.MAX_VALUE)
long sum; // 总修改次数
long last = 0L; // 上一次的sum
int retries = -1; // 重试次数
try {
for (;;) {
// 如果重试次数超过阈值,强制加锁
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // 加锁
}
sum = 0L;
size = 0;
overflow = false;
// 遍历所有Segment
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
// 累加modCount和count
sum += seg.modCount;
int c = seg.count;
// 检查溢出
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
// 如果是第一次迭代,或者modCount没有变化
if (sum == last)
break;
last = sum; // 记录本次的sum,用于下次比较
}
} finally {
// 如果之前加锁了,现在要释放
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}
3.3 实现原理分析
modCount的作用: 每个Segment维护一个modCount,每次修改操作(put、remove等)都会增加这个值。通过比较两次统计的modCount总和,可以判断在统计期间是否有并发修改发生。
工作流程:
-
第一次无锁统计:遍历所有Segment,记录每个Segment的modCount和count
-
第二次无锁统计:再次遍历,比较modCount总和
-
如果一致:说明在两次统计期间没有发生修改,结果准确
-
如果不一致:说明有并发修改,需要重试
-
重试超过阈值(默认2次):退化为加锁统计
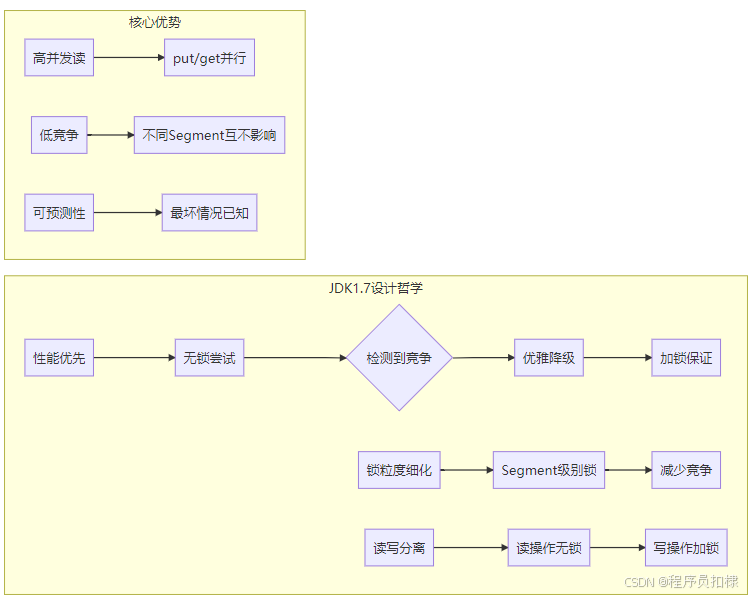
3.4 设计优势
-
无竞争时的零锁开销:在没有并发修改的情况下,完全不需要加锁
-
快速失败:通过两次统计就能检测到并发修改
-
渐进式降级:从无锁到轻量级重试,最后才加锁
-
避免死锁:不需要按顺序获取锁,统计时只读不加锁
四、性能与准确性的权衡
4.1 为什么这种设计更优?
在实际应用中,size()方法的调用频率通常远低于put/get操作。如果每次调用size()都加锁,会严重影响整体并发性能。而无锁统计虽然在并发修改时可能不准确,但在很多场景下是可以接受的:
-
监控场景:大概的数量就足够了
-
容量检查:判断是否大致接近阈值
-
调试信息:输出日志时不需要精确值
4.2 适用场景分析
适合无锁统计的场景:
-
实时监控系统状态
-
日志记录
-
启发式决策(如是否触发清理)
需要精确值的场景:
-
事务处理
-
一致性检查
-
精确计费
对于需要精确值的场景,可以:
-
使用加锁的替代方法
-
在业务层面进行控制
-
接受短暂的不一致
五、与JDK1.8的对比
JDK1.8中的ConcurrentHashMap摒弃了分段锁设计,改为使用CAS+synchronized,size()方法也采用了不同的实现:
-
JDK1.7:通过modCount检测变化,必要时加锁
-
JDK1.8:维护一个volatile的baseCount,通过CAS更新,size()返回的是一个估计值
六、最佳实践建议
-
避免频繁调用size():即使是无锁统计,遍历所有Segment也有开销
-
理解语义:size()返回的是近似值,不要依赖它的精确性
-
替代方案:如果需要精确计数,考虑使用AtomicLong或LongAdder
-
监控使用:size()更适合用于监控和调试,而不是业务逻辑
七、总结
JDK1.7中ConcurrentHashMap的扩容机制和size()方法体现了Java并发编程的精髓:
-
分段扩容:将锁的粒度缩小到Segment级别,提高并发度
-
优化迁移:lastRun机制减少对象创建
-
无锁优先:size()方法优先尝试无锁统计
-
优雅降级:检测到竞争时退化为加锁方式
这种设计在保证线程安全的前提下,最大限度地提高了并发性能,是并发编程中"读多写少"场景的优秀实践。虽然JDK1.8已经采用了更新的实现,但理解这些经典设计思想,对于深入掌握并发编程仍然具有重要价值。

















 1304
1304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









