




01、操作

02、Hash与String的主要区别?
1、把所有相关的值聚集到一个key中,节省内存空间
2、只使用一个key,减少key冲突
3、当需要批量获取值的时候,只需要使用一个命令,减少内存/IO/CPU的消耗
03、操作命令
hset key1 f 6
hset key1 e 7
hmset key1 a 5 b 4 c 3
hget key1 f
hmget key1 a b c
hkeys key1
hvals key1
hgetall key1
hget key1
hdel key1
hlen key1
04、存储(实现)原理
Hash本身也是一个KV的结构,类似于Java中的HashMap。
外层的哈希(RedisKV的实现)只用到了hashtable。当存储hash数据类型时,我们把它叫做内层的哈希。
内层的哈希底层可以使用两种数据结构实现:
ziplist:OBJ_ENCODING_ZIPLIST(压缩列表)
hashtable:OBJ_ENCODING_HT(哈希表)

05、 ziplist
【1】、ziplist压缩列表
ziplist是特殊编码的双向链表,它不存储指向上一个链表节点和指向下一个链表节点的指针,而是存储上一个节点长度和当前节点长度,通过牺牲部分读写性能,来换取高效的内存空间利用率,是一种时间换空间的思想。只用在字段个数少,字段值小的场景里面。
【2】、ziplist的内部结构


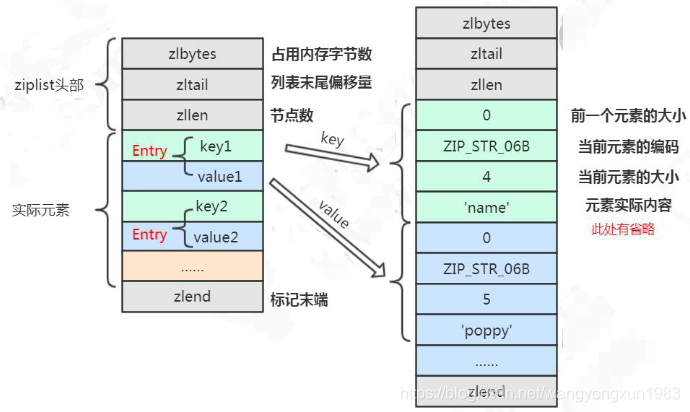
【3】、什么时候使用ziplist存储?
1、所有的键值对的健和值的字符串长度都小于等于64byte
2、哈希对象保存的键值对数量小于512个。

【4】、什么时候成为hashtable
一个哈希对象超过配置的阈值(键和值的长度有>64byte,键值对个数>512个)时,会转换成哈希表(hashtable)。
06、hashtable(dict)
hashtable被称为字典(dictionary),它是一个数组+链表的结构。
【1】、代码结构
dictEntry的多层的封装

dictEntry放到了dictht(hashtable里面):如下

ht放到了dict里面:如下

从最底层到最高层dictEntry——dictht——dict——OBJ_ENCODING_HT
【2】、哈希的存储结构

【3】、为什么要定义两个哈希表呢?ht[2]
redis的hash默认使用的是ht[0],ht[1]不会初始化和分配空间。
哈希表dictht是用链地址法来解决碰撞问题的。哈希表的性能取决于它的大小(size属性)和它所保存的节点的数量(used属性)之间的比率:
- 比率在1:1时(一个哈希表ht只存储一个节点entry),哈希表的性能最好;
- 如果节点数量比哈希表的大小要大很多的话(这个比例用ratio表示,5表示平均一个ht存储5个entry),那么哈希表就会退化成多个链表,哈希表本身的性能优势就不再存在。
在这种情况下需要扩容。Redis里面的这种操作叫做rehash。
1、rehash的步骤:
- 为字符ht[1]哈希表分配空间,这个哈希表的空间大小取决于要执行的操作,以及ht[0]当前包含的键值对的数量。扩展:ht[1]的大小为第一个大于等于ht[0].used*2。
- 将所有的ht[0]上的节点rehash到ht[1]上,重新计算hash值和索引,然后放入指定的位置。
- 当ht[0]全部迁移到了ht[1]之后,释放ht[0]的空间,将ht[1]设置为ht[0]表,并创建新的ht[1],为下次rehash做准备。
2、什么时候触发扩容?

- ratio=used/size,已使用节点与字典大小的比例
- dict_can_resize为1并且dict_force_resize_ratio已使用节点数和字典大小之间的比率超过1:5,触发扩容
06、应用场景
比String节省了更多key的空间,也更加便于集中管理。
购物车
key:用户id;field:商品id;value:商品数量。
+1:hincr。-1:hdecr。删除:hdel。全选:hgetall。商品数:hlen。
07、细节可参考
https://blog.youkuaiyun.com/qiezikuaichuan/article/details/46574301

















 2125
2125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









