




 本文详细介绍了Java中synchronized关键字的三种使用方式及其底层实现原理,包括实例方法、静态方法和代码块的同步。通过分析字节码和对象头的MarkWord,揭示了锁的状态变化,涉及无锁、偏向锁、轻量级锁和重量级锁。此外,还讨论了JDK1.6后的锁优化,如自旋锁和自适应自旋锁。
本文详细介绍了Java中synchronized关键字的三种使用方式及其底层实现原理,包括实例方法、静态方法和代码块的同步。通过分析字节码和对象头的MarkWord,揭示了锁的状态变化,涉及无锁、偏向锁、轻量级锁和重量级锁。此外,还讨论了JDK1.6后的锁优化,如自旋锁和自适应自旋锁。
转载文章:https://www.cnblogs.com/semi-sub/p/12906660.html
相信对Java程序员来说,synchronized关键字对大家来说并不陌生,当我们遇到并发情况时,优先会想到用synchronized关键字去解决,synchronized确实能够帮助我们去解决并发的问题,但是它会引起一些其他问题,比如最突出的一点就是程序效率问题,不过后面随着JDK1.6对synchronized关键字做出了许多优化,让synchronized和java.util.concurrent.locks.ReentrantLock等并发包中的类效率差不多。下面主要来分析一下synchronized底层的实现原理。
1 基本使用
synchronized关键字可以用来修饰三个地方:
1.synchronized放在实例方法上,锁对象是当前的this对象
2.synchronized放在类方法上,也就是我们所说的静态方法上,锁对象是方法区中的类对象,是一个全局锁
3.synchronized修饰代码块,也就是synchronized(object){},锁对象是()中的对象synchronized关键字用来修饰的位置不同,其实现原理也是不同的。锁住的对象也是不同的。
在Java中,每个对象里面隐式的存在一个叫monitor(对象监视器)的对象,这个对象源码是采用C++实现的,下面来看一下Monitor对象的源码:
ObjectMonitor() {
_header = NULL;
_count = 0; // 记录个数
_waiters = 0,
_recursions = 0;
_object = NULL;
_owner = NULL;
_WaitSet = NULL; // 处于wait状态的线程,会被加入到_WaitSet
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;
FreeNext = NULL ;
_EntryList = NULL ; // 处于等待锁block状态的线程,会被加入到该列表
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}
当monitor对象被线程持有时,Monitor对象中的count就会进行+1,当线程释放monitor对象时,count又会进行-1操作。用count来表示monitor对象是否被持有.
2 同步原理
针对synchronized修饰的地方不同,实现的原理不同
1.先看synchronized放在实例方法上的代码:
public class Test {
public synchronized void test() {
}
}用javap -verbose查看反编译结果:
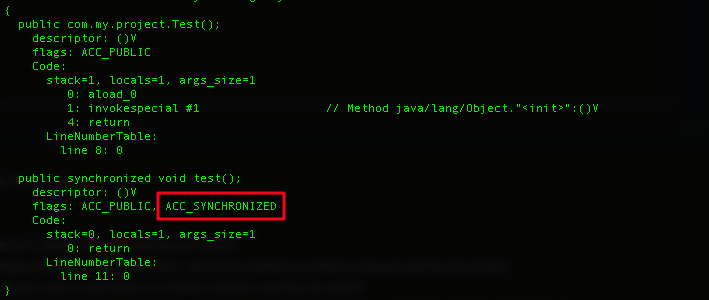
从反编译的结果来看,我们可以看到test()方法中多了一个标识符。JVM就是根据该ACC_SYNCHRONIZED标识符来实现方法的同步:
当方法被执行时,JVM调用指令会去检查方法上是否设置了ACC_SYNCHRONIZED标识符,如果设置了ACC_SYNCHRONIZED标识符,则会获取锁对象的monitor对象,线程执行完方法体后,又会释放锁对象的monitor对象。在此期间,其他线程无法获得锁对象的monitor对象
2.第二种情况,synchronized放在类方法上:
public class Test {
public synchronized static void test(){
}
}反编译结果:

我们可以看到跟放在实例方法相同,也是test()方法上会多一个标识符。可以得出synchronized放在实例方法上和放在类方法上的实现原理相同,都是ACC_SYNCHRONIZED标识符去实现的。只是它们锁住的对象不同
3.第三种情况,synchronized修饰代码块:
public class Test {
public void test(){
synchronized (this) {
}
}
}反编译结果:
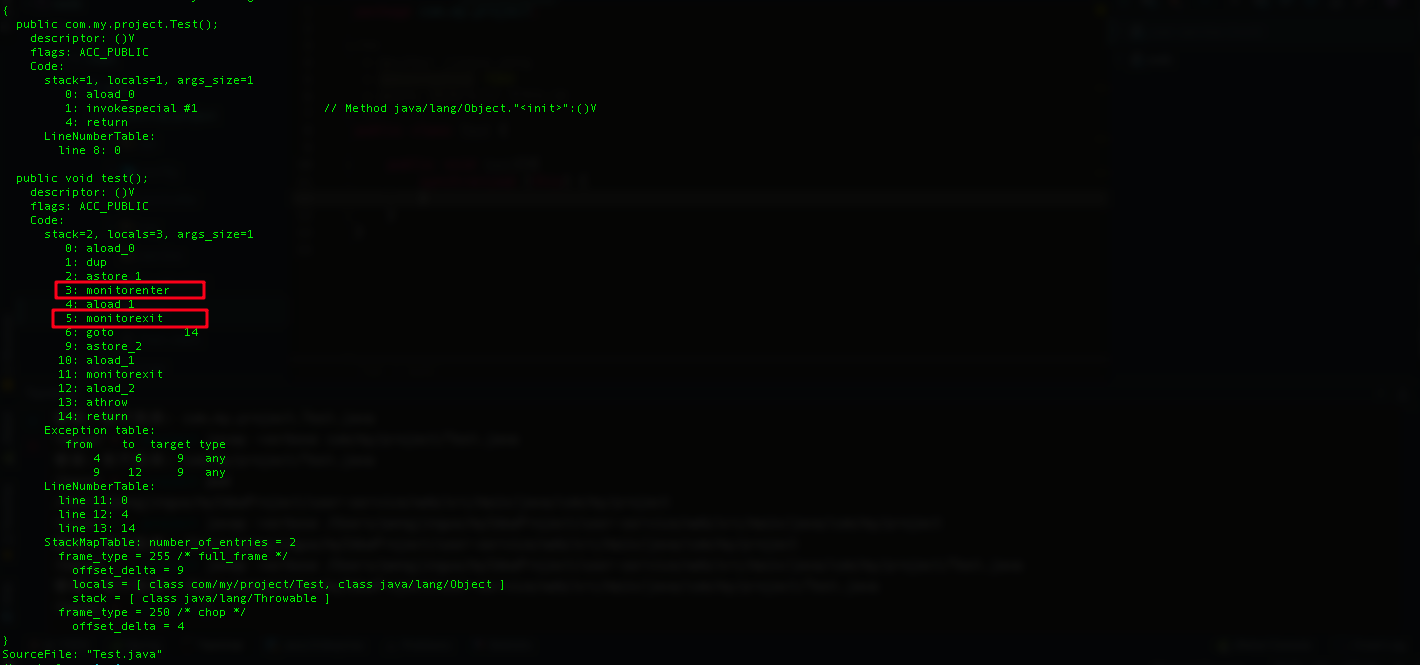
我们可以看到test()字节码指令中会有两个monitorenter和monitorexit指令,
(1)monitorenter: monitorenter指令表示获取锁对象的monitor对象,这是monitor对象中的count并会加+1,如果monitor已经被其他线程所获取,该线程会被阻塞住,直到count=0,再重新尝试获取monitor对象
(2)monitorexit: monitorexit与monitorenter是相对的指令,表示进入和退出。执行monitorexit指令表示该线程释放锁对象的monitor对象,这时monitor对象的count便会-1变成0,其他被阻塞的线程可以重新尝试获取锁对象的monitor对象
从synchronized放置的位置不同可以得出,synchronized用来修饰方法时,是通过ACC_SYNCHRONIZED标识符来保持线程同步的。而用来修饰代码块时,是通过monitorenter和monitorexit指令来完成
3 同步概念
3.1 Java对象头
像我们上面所提到的monitor监视器对象存在于Java对象的对象头Mark Word中,
什么是Java对象头的Mark Word了?这就跟Java对象在JVM中的内存布局有关系,Java对象在JVM内存中分为三块区域:对象头,实例数据和对齐填充。
1. 对象头:对象头又包含以下部分:Mark Word, 类型指针,如果对象是数组的话,还会存在一个数据数组长度,用来记录数据长度。其中Mark Word又包含:哈希码(HashCode),GC分代年龄,锁状态标志,线程持有的锁等信息。
2. 实例数据:这部分是对象真正存储的有效信息,也就是我们在程序中所定义的各种类型的字段内容。
3. 对齐填充:这部分数据并不是必然存在的,JVM内存管理系统要求我们定义的对象大小必须是8字节的整数倍,如果对象大小不是整数倍,这时就会有对齐填充这块数据,来将对象大小补全成为8字节的整数倍如图所示:

下面结合锁的优化,来讲一下Mark Word中的锁状态发生的变化:
-
无锁
也就是代表对象的monitor对象并没有被线程所持有,代表的是对象处于无锁状态
-
偏向锁
偏向锁是JDK1.6后面引起的一项锁优化技术,在无锁竞争的情况下,一个线程通过一次CAS操作来尝试将对象头中的Thread ID字段设置为自己的线程号,如果设置成功,则获得锁,那么以后线程再次进入和退出同步块时,就不需要使用CAS来获取锁,只是简单的测试一个对象头中的Mark Word字段中是否存储 着指向当前线程的偏向锁。如果使用CAS设置失败时,说明存在锁的竞争,这时偏向锁便会升级成轻量级锁和重量级锁。偏向锁指的是这个锁会偏向于第一个获得它的线程。
下面来看一下对象在无锁和偏向锁状态下,Mark Word的锁状态位变化:
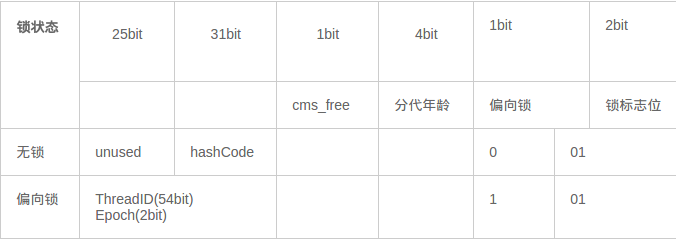
我们可以看到这是偏向锁的标志位被至为了1,表示现在处于偏向模式 -
轻量级锁
表示线程通过一定的数量CAS操作(JDK1.6后默认10次)完成加锁和解锁操作,如果锁获取失败,会通过自旋来获取,竞争的线程不会阻塞,如果还是获取失败,表示此时存在其他线程竞争锁(两条或两条以上的线程竞争同一个锁),则轻量级锁会膨胀成重量级锁。 -
重量级锁
当一个锁被两条或两条以上的线程竞争的时候,这时候轻量级锁就会演变成重量级锁。
在轻量级锁和重量级锁的情况下,锁状态标记位:
除了以上几种锁外,其实还有自旋锁,自适应自旋锁 -
自旋锁
当两个线程去竞争同一把锁时,一个线程获取成功,一个线程获取失败,这时可能会出现获取成功的线程持有锁的时间非常短,如果这时候将获取失败的线程进行挂起的话,会造成功线程上下文的切换,到时候又需要唤醒线程,这时我们可以让获取失败的线程进行一个自旋,无需将线程挂起。等到锁释放。但是这种方案适用于锁被占用的时间很短的情况,如果锁被持有的时间很长,然后线程将会一直处于自旋状态,白白消耗处理器资源。自旋等待的时间必须要有一定的限度,如果超过此数还是没有获取到,则将线程挂起。自旋此数的默认值是10次,可以使用JVM参数-XX:PreBlockSpin来进行更改。 - 自适应自旋锁
自适应自旋锁是在自旋锁的基础上产生的,进行了一次优化。自适应意味着自旋的时间不再固定,而是由前一次在同一个锁上的自旋时间几锁的拥有者的状态来决定的。
锁的优缺点对比

结论:
从上面分析得出:synchronized关键字底层实现主要是通过monitor对象去完成的,修饰的位置不同,实现的方式有点差异,但是底层都是通过monitor对象去实现的。后面还讲了JDK1.6对synchronized关键字做出的锁优化。

















 566
566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









