




全文摘要
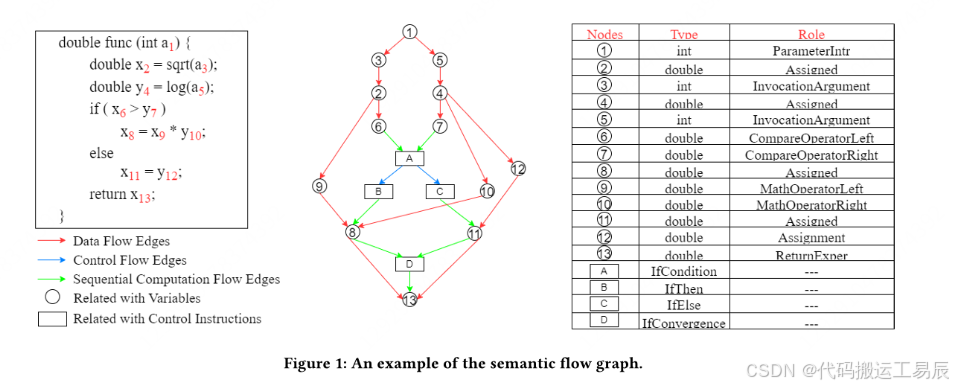
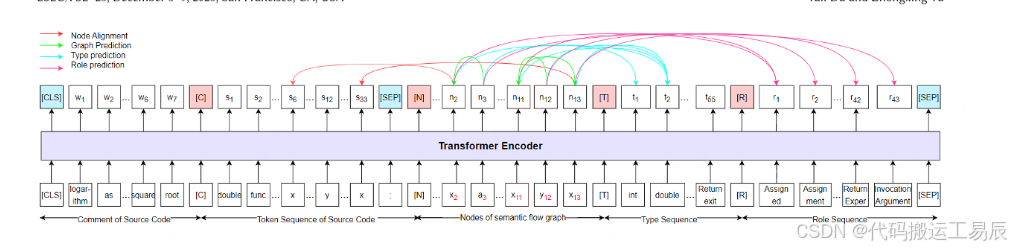
本文旨在解决自然语言处理中预训练模型在编程语言中的应用问题,并提出了针对代码语义和对比学习的新方法。传统的基于BERT的bug定位技术存在两个问题:一是无法充分捕捉程序代码的深层语义;二是忽略了大规模负样本在对比学习中的重要性以及bug报告与变更集之间的词汇相似度。为了解决这些问题,作者提出了一个名为Semantic Flow Graph(SFG)的新型有向、多标签代码图表示,可以紧凑地、充分地捕获代码语义。此外,作者还设计并训练了SemanticCodeBERT,并提出了一种新的层次化动量对比式bug定位技术(HMCBL)。实验结果表明,该方法在bug定位方面取得了最先进的性能。
论文方法
方法描述
该论文提出了一种基于深度学习的bug定位方法,其主要流程包括三个部分:表示学习、相似度估计和离线索引与检索。其中,表示学习使用了预训练的语言模型(如BERT)和代码模型(如SemanticCodeBERT),将自然语言描述和编程语言代码转化为向量表示;相似度估计算法采用了层次化对比损失函数,同时考虑了特征级、模型级和记忆库级的相似度;离线索引与检索则采用了IVFPQ算法实现快速检索。
方法改进
相比于传统的基于规则或统计学方法的bug定位方法,该方法通过深度学习的方式可以更好地捕捉语义信息,并且能够自适应地学习到不同项目之间的差异性。此外,该方法还引入了大规模负样本和记忆库机制,提高了模型的泛化能力和鲁棒性。
解决的问题
该方法解决了传统bug定位方法中无法有效处理复杂场景和大量数据的问题,同时也为后续的研究提供了新的思路和方向。</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









