文章大纲 woe 简介 spark woe 实现 scala python 参考文献 woe 简介 WOE全称是Weight of Evidence,即证据权重,也叫作自变量的一种编码 WOE的公式定义如下: w o e = ∑ l o g G i / G t o t a l B i / B t o t a l woe=\sum{log\frac{G_i/G_{total}}{B_i/B_{total}}} woe=<









 超级会员免费看
超级会员免费看

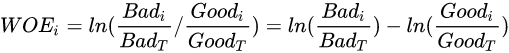

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 2103
2103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








