







 超级会员免费看
超级会员免费看
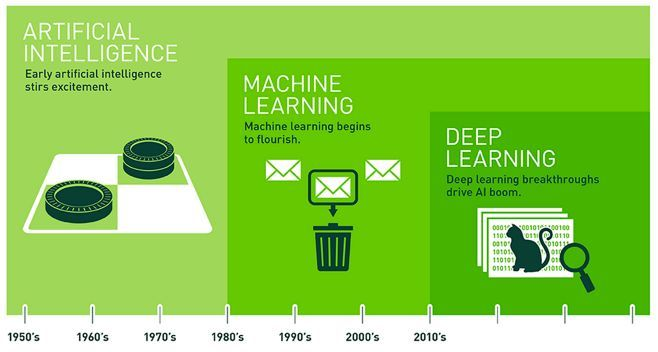
随着实验科学所面临的数据集规模的迅速增长,机器学习、深度学习作为越来越重要的基础技术,它们需要解决的问题包括完整的pipeline 流程构建工程,建立一整套ETL(Extract-Transform-Load),连接不同观测值的预测函数,对观测值进行分类,或者在未标记的数据集中学习不同的结构。
- 神经网络的回归
在大数据时代,云计算和大规模并行处理基础架构的共同发展,使得机器处理能力在二十一世纪初得到了极大的提升。我们不再局限于低功耗/简单的模型。例如,当今最流行的两种主流机器学习模型是随机森林和梯度提升树。 尽管如此,两者都非常强大,并且提供了非线性模型拟合的训练数据,但数据科学家仍然需要仔细地创建特征以获得良好的性能。
与此同时,计算机科学家重新使用神经网络的许多层来完成这些人类模仿的任务。这给DNN(深度神经网络)带来了新的生机,并在图像分类和语音识别任务方面提供了重大突破。DNN和传统机器学习的主要区别在于,你可以将原始信号(例如RGB像素值)直接输入DNN,而不需要创建任何域特定的输入功能。通过多层神经元(这就是为什么它被称为“深度”神经网络),DNN可以“自动”通过每一层产生适当的特征,最后提供一个非常好的预测结果。
这极大地消除了寻找“特征工程”的麻烦,这是数据科学家们最喜欢看到的。DNN也演变成许多不同的网络拓扑结构,所以有CNN(卷积神经网络

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











