







主库
[mysqld]
#唯一标志
server-id=110
character_set_server=utf8mb4
basedir=/usr/local/mysql
datadir=/data/mysql
pid-file=/data/mysql/mysql.pid
#设置75%%的内存用于 buffpool
innodb_buffer_pool_size=12884901888
# 分成6个 这个参数注意,需要根据数据量规模来自己测试,太小会有过多的锁冲突,太大会造成维护成本上升
innodb_buffer_pool_instances=6
#binlog 开启binlog,以及文件的前缀名称
log_bin=master-bin-log
#忽略哪些库不记录binlog
binlog-ignore-db=mysql
#过期时间
expire_logs_days = 7
#binlog文件大小
max_binlog_size = 512M
#记录的格式 mixed row smixed row statement
binlog_format=mixed
#gtid 同步模式 可以不开启
gtid_mode=on
enforce-gtid-consistency
#刷盘策略 0:默认不刷盘,等mysql自己控制 1:每次事务提交将redolog 刷盘 2 : 刷入OS cache(如果机器宕机也会丢失数据) 对于高要求的数据库 可以设置为1,但是吞吐量下降
innodb_flush_log_at_trx_commit=1
#分布式事务开启
innodb_support_xa = 1
# 默认32k,如果一个大事务,产生日志大于32k,那内存写不下就要写磁盘了,大批量删和更新可能会性能下降
binlog_cache_size = 64k
#错误日志
log_error = /data/mysql/mysql-error.log
#慢sql记录
slow_query_log = On
# 慢sql时间 单位秒
long_query_time = 2
slow_query_log_file = /data/mysql/mysql-slow.log
#开启 记录那些执行时没有从任何索引中受益的查询 可不开启
log-queries-not-using-indexes
#高可用的时候 主可能变成从,在这种情况下 配置下面两个,只是读写 可以不配置
relay_log_recovery = 1 # 崩溃或重启时,删除原中继器文件,重新生成 默认关
relay_log_info_repository = TABLE # 记录从库relaylog的信息,可以设置FILE或者TABLE 默认是file
#master.info(主从状态,配置信息)记录下来,默认记录到file里面,建议使用表记录
master_info_repository = TABLE
#binlog 刷盘 0 表示不由mysql控制,>0 表示多少次事务后刷盘,会消耗IO资源,性能会下降,如果每秒刷盘,性能与不刷盘相差5倍左右,主库可以考虑适用,只用来写操作
sync_binlog=1
#表名在硬盘上以小写保存,名称比较对大小写不敏感。
lower_case_table_names=1
#连接等待时间 32小时 默认是8小时 可以不设置
wait_timeout=115200从库
[mysqld]
#唯一标志ID
server-id = 61
#开启binlog
log_bin=slave-bin
#binlog 格式 ROW MIXED STATEMENT
binlog_format=MIXED
#binlog 日志时间过期时间
expire_logs_days = 7
#binlog 最大日志大小
max_binlog_size = 512M
#gtid 同步复制模式开启
gtid_mode=on
enforce-gtid-consistency
#同步的sql 记录到binlog文件,不开启 同步主库的sql是不会记录到binlog 主 -> 从 ->从 模式需要开启
log-slave-updates=ON
#启动跳过 同步开启,需要自己手动开启
skip_slave_start=1
#高可用的时候 主可能变成从,在这种情况下 配置下面两个,只是读写 可以不配置
relay_log_recovery = 1 # 崩溃或重启时,删除原中继器文件,重新生成 默认关
relay_log_info_repository = TABLE # 记录从库relaylog的信息,可以设置FILE或者TABLE 默认是file
#master.info(主从状态,配置信息)记录下来,默认记录到file里面,建议使用表记录
master_info_repository = TABLE
#忽略哪些库的同步,一般去掉mysql 常导致mysql同步异常
replicate-ignore-db=mysql
#错误日志
log_error = /data/mysql/mysql-error.log
#慢sql查询记录
slow_query_log = On
#超过2秒
long_query_time = 2
slow_query_log_file = /data/mysql/mysql-slow.log
#记录 没有从索引中获益的查询
log-queries-not-using-indexes
#redo log 刷盘策略 0:不刷盘,mysql自己控制 1:每次事务刷盘 2:刷盘到OS Cache 如果服务器宕机也会丢失
innodb_flush_log_at_trx_commit=2
#binlog 刷盘策略 0 由mysql控制,>0 表示多少次事务刷盘一次
sync_binlog=0
#表名对大小写不敏感
lower_case_table_names=1几个重要参数解释:
innodb_flush_log_at_trx_commit:(注:mysql的事务机制 是使用 redo log机制来实现的)
- 值为0:那么你提交事务的时候,不会把redo log buffer里的数据刷入磁盘文件的,等Mysql 自身决定什么时候刷入磁盘,此时可能你都 提交事务了,结果mysql宕机了,然后此时内存里的数据全部丢失,安全性最差,吞吐量最高。
- 值为1:你提交事务的时候,就必须把redo log从内存刷入到磁盘文件里去,只要事务提交成功,那么redo log就 必然在磁盘里了。
- 值为2:提交事务的时候,把redo日志写入磁盘文件对应的os cache缓存里去,而不是直接进入磁盘文件,可 能1秒后才会把os cache里的数据写入到磁盘文件里去,此时mysql宕机数据不会丢失,但是如果整个物理机器宕机,那么数据仍然会丢失。
binlog_format :
STATEMENT : 每一条会修改数据的sql语句会记录到binlog中,slave在复制的时候sql进程会解析成master端执行过的相同的sql在slave库上再次执行。但是对于函数、function等操作不是很友好,不推荐使用
ROW : 不记录每条sql语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了。而且不会出现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的问题。缺点是会产生大量的日志,尤其是alter table的时候会让日志暴涨。日志中会记录成每一行数据修改的形式,然后在slave端再对相同的数据进行修改。
新版本中的mysql中对row level模式也做了优化,并不是所有的修改都会以row level来记录,像遇到表结构变更的时候就会以statement模式来记录,如果sql语句确实就是update或者delete等修改数据的语句,那么还是会记录所有行的变更。
MIXED : 以上两种模式的混合使用,一般的复制使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择日志保存方式,也是在statement和row之间选择一种。
relay_log_info_repository:
设置为FILE,MySQL会把回放信息记录在一个relay-info.log 的文件中,其中包含SQL线程回放到的Relay_log_name和Relay_log_pos,以及对应的Master的Master_log_name和Master_log_pos
+--------+ replication +-------+
| Master +--------------------> | Slave |
+--------+ +---+---+
|
| sql thread apply event
| write binary log position to file relay-info log
+--------v-------+
| relay-info.log | (sync_relay_log_info = 10000)
+----------------+- SQL线程回放event
- 将回放到的binlog的文件名和位置写到relay-info.log文件
- 参数sync_relay_log_info = 10000(fsync)代表每回放10000个event,写一次 relay-info.log,默认1w
综上:SQL线程的数据回放是写数据库操作,relay-info是写文件操作,这两个操作很难保证一致性,看下面这种情况
step1:
主上顺序插入1,2,3
step2:
从同步主,插入1,2,3,成功且已刷盘
刚好1这条记录刚好是第 N w个event,此时relay-info.log刷盘,这样就只刷到1的位置,2,3没被刷进去
step3:
无独有偶,slave挂了
这时候slave起来之后,继续回放的时就会从1后面的位置开始回放,这样问题就出来了,报1062,2,3这两条记录重复了注:即使是设置 sync_relay_log_info = 1 ,①刷盘代价很高 ②仍然会使得一条数据重复
MySQL 5.6之后,我们将relay_log_info_repository设置为TABLE,relay-info将写入到mysql.slave_relay_log_info这张表中,
原理
将event的回放和relay-info的更新放在同一个事物里面,变成原子操作,从而保证一致性(要么都写入,要么都不写)每一次事物提交,都会写入mysql.slave_relay_log_info中,sync_relay_log_info=N将被忽略。
BEGIN;
apply log event;
apply log event;
UPDATE mysql.slave_relay_log_info
SET Master_log_pos = Exec_Master_Log_Pos,
Master_log_name = Relay_Master_Log_File,
Relay_log_name = Relay_Log_File,
Relay_log_pos = Relay_Log_Pos;
COMMIT;master_info_repository :
+--------+ receive +-----------+ +----------------+
| events +-----------+sql thread +------->| relay log file |
+--------+ +-----------+ +---+------------+
|
| write received event position to file
|
+-----v---------+
|master-info.log|
+---------------+- io线程负责接收event到relay log file,每接收到一个event会在master-info.log记录一下IO线程接收到的位置(Master_log_name和Master_log_pos)
- sync_master_info=10000表示每接收10000个event,写一次master-info
这里存在同样的问题,master-info.log和relay log无法保证一致性,跟上面情况一样,主要是刷盘的问题。
解决:
- 设置master_info_repository = TABLE???
没用的,event是写到relay log文件里的,不是数据库操作,所以写表里也没用,做不到原子性 - 正确做法是配置relay_log_recovery = 1,表示当slave重启时,将所有relay log删除,通过sql线程重放的位置点去重新拉日志
- master_info_repository设置为TABLE虽然对crash-safe没有帮助,但也请设置为TABLE,这样性能会有提升(5.7bug)
tips:
如果 Slave落后Master的时间很多,超过了Master上binlog的保存时间,那Master上对应的binlog就会被删除,Slave的I/O Thread就拉不到数据了,注意监控主从落后的时间,或者重新同步数据,同时修改slave status。
因此,真正的MySQL复制的高可靠是从 5.6 版本开始的,通过设置以下三个参数确保复制的高可靠(换言,之前的版本复制不可靠很正常)
relay_log_recover = 1 #重启后,删除relay_log,重新拉取
relay_log_info_repository = TABLE
master_info_repository = TABLE
#非常建议这3个参数主从配置完全一致,主从是平等的,尽量对称并行复制(Multi-Threaded Slave)介绍
5.6开始支持多线程复制(MTS)
slave_parallel_workers 0表示只有1个线程,可以动态设置,但是要重启一下复制,线上设为8或者16
注意:5.6版本只支持基于database的并行回放,所以不能选择并行模式,有多少个库,就可以开多少个线程,每个线程回放指定的库,缺点就是只有一个库的时候就并行不了,所以说这时候的并行复制用的并不多
5.7支持并行复制模式设置
slave_parallel_type=logical_clock配置很简单,性能很棒棒,主上面怎么并行,从上面就怎么回放,基于逻辑时钟的概念
5.7才有,5.7.19之前有bug,会导致主从不一致,慎用
Slave上commit的顺序保持一致,否则可能会有GAP锁产生
Gap(间隙锁)A place in an InnoDB index data structure where new values could be inserted.
说白了gap就是索引树中插入新记录的空隙。相应的gap lock就是加在gap上的锁,还有一个next-key锁,是记录+记录前面的gap的组合的锁。
slave_preserve_commit_order=1并行复制时,slave上coordinator协调者线程负责任务指派,work thread负责回放如下:
(root@172.16.0.10) [test]> show processlist;
+----+-------------+-----------+------+---------+-------+--------------------------------------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-------------+-----------+------+---------+-------+--------------------------------------------------------+------------------+
| 1 | system user | | NULL | Connect | 26277 | Waiting for master to send event | NULL |
| 2 | system user | | NULL | Connect | 26217 | Slave has read all relay log; waiting for more updates | NULL |
| 4 | system user | | NULL | Connect | 26277 | Waiting for an event from Coordinator | NULL |
| 5 | system user | | NULL | Connect | 26277 | Waiting for an event from Coordinator | NULL |
| 6 | system user | | NULL | Connect | 26277 | Waiting for an event from Coordinator | NULL |
| 7 | system user | | NULL | Connect | 26277 | Waiting for an event from Coordinator | NULL |
| 10 | root | localhost | NULL | Query | 0 | starting | show processlist |
+----+-------------+-----------+------+---------+-------+--------------------------------------------------------+------------------+
7 rows in set (0.00 sec)tips:
这里的并行复制指的是SQL Thread,而非IO Thread
Waiting for master to send event 这个State在show processlist中只有一个,即只有一个IO Thread
理解logical_clock
这是一种基于组提交的并行复制
如果一批事务在一组里提交,这些事务之间是没有锁冲突的(有锁冲突就要等待了,不可能在一组里提交)
此时,binlog就会记录组提交的信息,从回放的时候就可以知道哪些事务是一组里面的,一组里面的就丢到不同线程去回放,不是一组里的就等待,以此来提升并行度
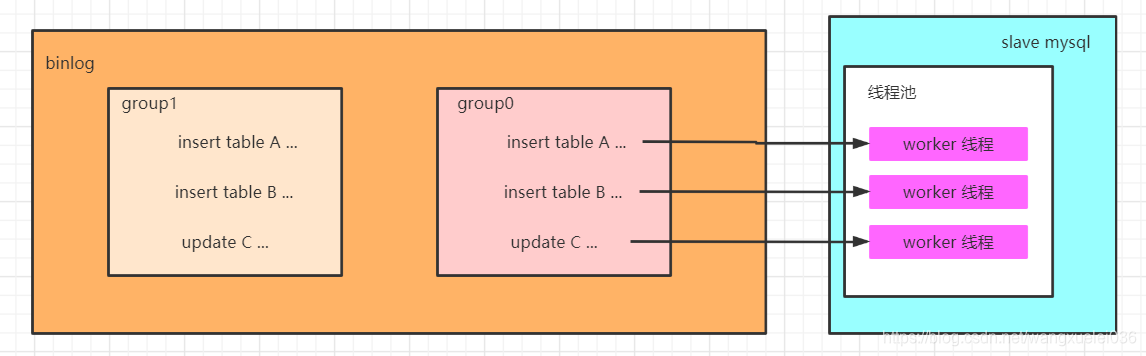
为了兼容MySQL 5.6基于库的并行复制,5.7引入了新的变量slave-parallel-type,其可以配置的值有:
- DATABASE:默认值,基于库的并行复制方式
- LOGICAL_CLOCK:基于组提交的并行复制方式
相关测试
单线程,从机回放速度只能达到5k的qps
设置为logical_clock,从的qps能超过2.5w
tips:
- 如何看哪些事务在一组?
[root@VM_0_5_centos ~]# mysqlbinlog xxx |grep last_comitted
last_comitted相等的事务是在同一组里提交的- last_commited记录了上一组提交的事务号,而每个事务的sequence_number是一直递增的
- 每组的last_committed值,都是上一个组中事务的sequence_number最大值,也是本组中事务sequence_number最小值减1
- last_committed和sequence_number作用域不得跨文件
MySQL 8.0出了一个更屌的复制并行回放,即使主上面是单线程执行了几个事务(更改了很多行,但是这些行不相关),从也可以并行回放这些事务
tips:
这种并行复制的前提是,binlog_format必须是row模式

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









