







 本文深入探讨MySQL索引及事务处理,解析不同索引类型及其应用策略,并介绍Redis作为NoSQL数据库的特点与数据类型,适合数据库管理和开发人员阅读。
本文深入探讨MySQL索引及事务处理,解析不同索引类型及其应用策略,并介绍Redis作为NoSQL数据库的特点与数据类型,适合数据库管理和开发人员阅读。
学习打卡第一天之mysql
索引:索引是最物美价廉的东西, 不需要加内存,不需要改程序,不需要调sql,查询速度就可以提高成千上百倍.
800W的数据在没有加上索引的时候查询时间是4.5 S在加上索引后查询时间为0.003S, 但是没创建索引文件大小为524M 创建索引后文件大小为655M
索引代价:
1, 占用磁盘空间
2. 影响增删改的效率(表有变化,需要对索引维护.)
索引类型
3. 主键索引
4. 唯一索引
5. 普通索引
6. 全文索引 开发基本上使用solr和es
查询表是不是有索引
- SHOW INDEXES FROM table
- SHOW INDEX FROM table
- SHOW KEYS FROM table
- DESC table
添加索引
1.添加唯一索引
CREATE UNIQUE INDEX id_index ON table (id);
2.添加普通索引
1. CREATE IDNEX id_index ON table (id);
2. ALTER TABLE table ADD INDEX id_index(id)
3. 添加主键索引
.CREATE TABLE table(
id INT,
‘name’ VARCHAR(32));
ALTER TABLE table ADD PRIMARY KEY (id)
)
删除索引
DROP INDEX id_index ON table
删除主键索引
ALTER TABLE table DROP PRIMARY KEY
修改索引,先删除,再添加新的索引
如何选择
如果某列的值,是不会重复的,则优先考虑使用唯一索引,否则使用普通索引
学习打卡第二天之mysql
索引小结
- 较为频繁的作为查询条件字段应该创建索引
- 唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
- 更新非常频繁的字段不适合创建索引
- 不会出现在where子句之中字段不该创建索引
事务:
什么是事务
事务用于保证数据的一致性,它由一组相关的dml语句组成的,该组的dml语句要么全部成功,要么全部失败.
转账问题:
A转账给B, 在数据库展现的形式就是 A减掉转账的钱 B加上转账的钱. 但是如果出现问题 就是A减掉的sql执行成功 但是B加上钱的sql执行失败那这就有问题了,这里就引出一个需求 将多个dml(update, delete, insert) 合并成一个 这就引出来事务
事务重要的操作
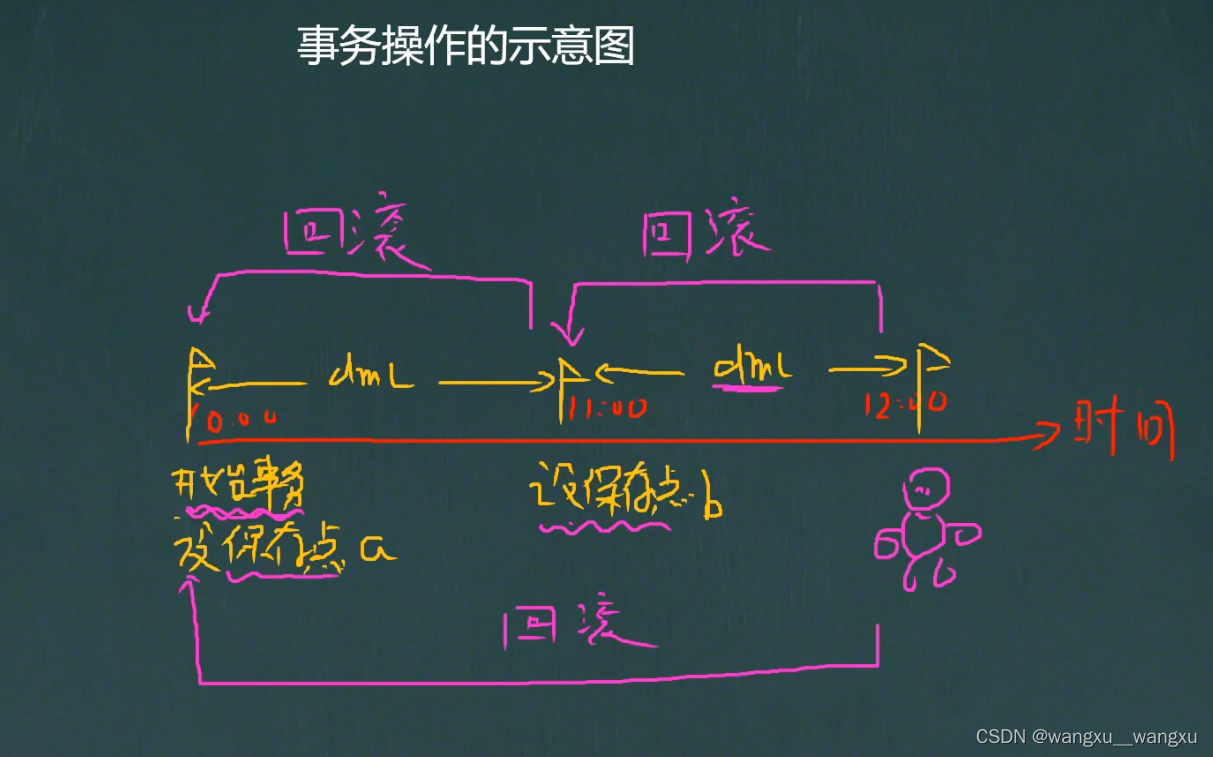
- start transaction – 开始事务
- savepoint 保存点名-- 设置保存点
- rollback to 保存点名-- 回退事务
- rollback – 回退全部事务
- commit --提交事务,所有的操作生效,不能回退


学习打卡第三天之mysql事务
事务的隔离级别
1 多个链接开启各自事务操作数据库时,书数据库负责隔离操作,以保证各个链接在获取数据的时的准确性
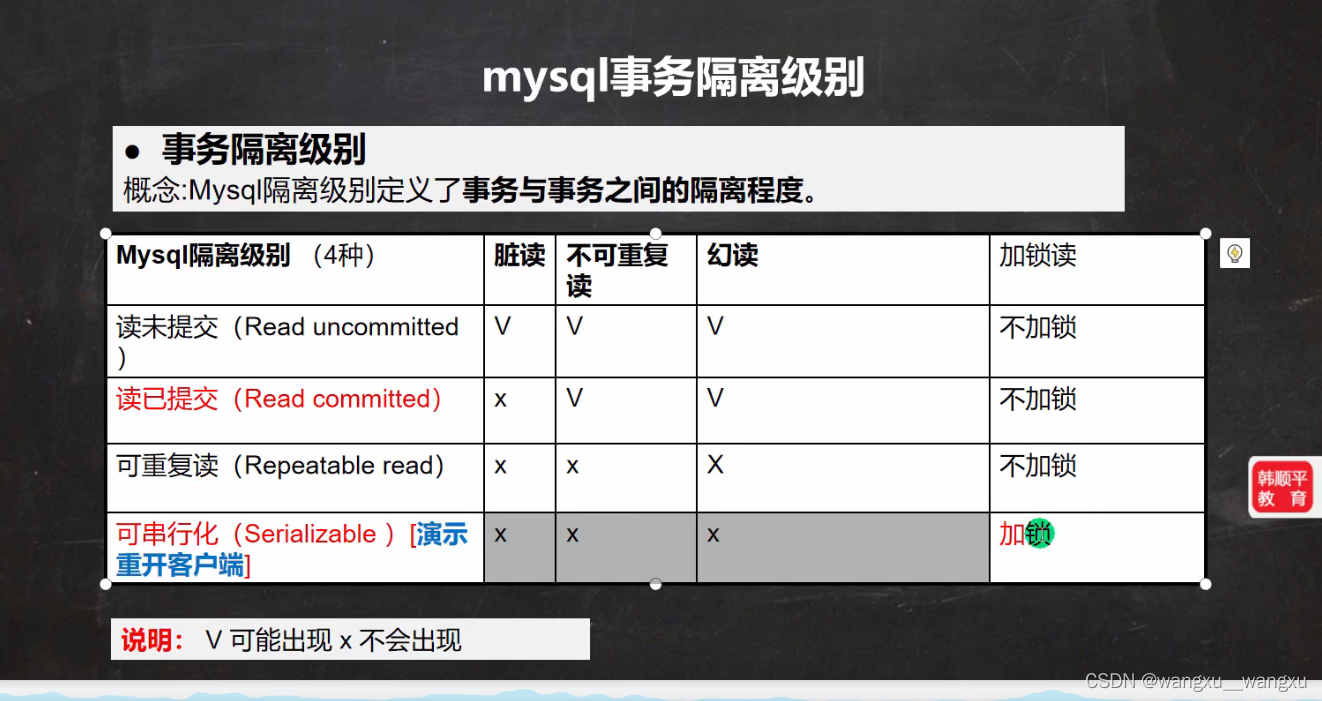
2 不考虑隔离性,可能会引发
- 脏读
- 不可重复读
- 幻读
脏读: 当一个事务读取到另一个尚未提交的修改是 这就是脏读
不可重复读: 在一个事务开启的情况下,里面很多查询并且查询出来结果是其他事务提交的修改和删除后的结果,这就是不可重复读
幻读: 在一个事务开启的情况下,里面很多查询并且查询出来结果是其他事务提交的添加后的结果,这就是幻读
查询mysql的事务隔离级别
SELECT @@tx_isolation;
设置事务隔离级别
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
学习打开第四天之mysql存储引擎
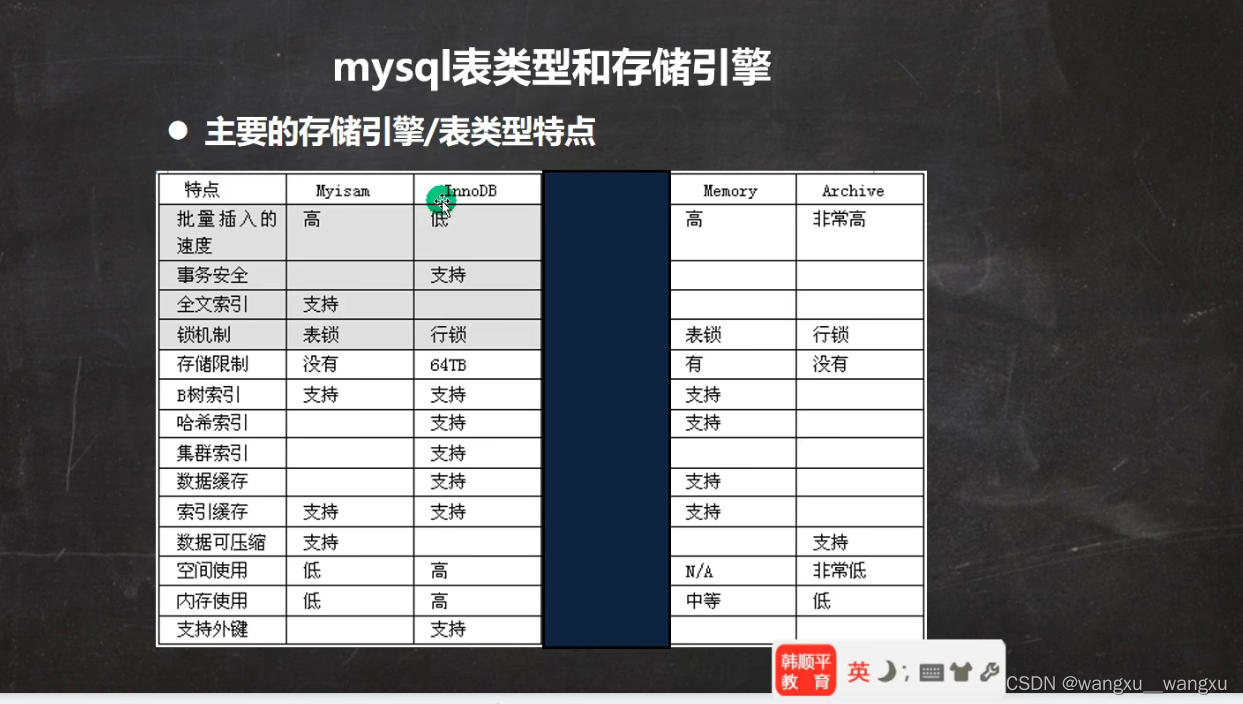
MyISam: 不支持事务,不支持外建.但是访问速度快,对事务完整性没有要求
InnoDB: 具有提交、回滚和崩溃恢复的能力的事务.但是比起MyISAM写的效率差一些并且会占用更多的磁盘空间保留数据和索引.
MEMORY: 使用内存引擎在内存中创建表.每个MEMORY表只实际对应一个磁盘文件.MEMORY类型表访问非常快,因为它的数据存在内存里面,并且默认使用HASH索引.但是服务一旦关闭,表中的数据就会丢失掉,表结构还在.

学习打卡第五天之补上昨天的
redis
简介:
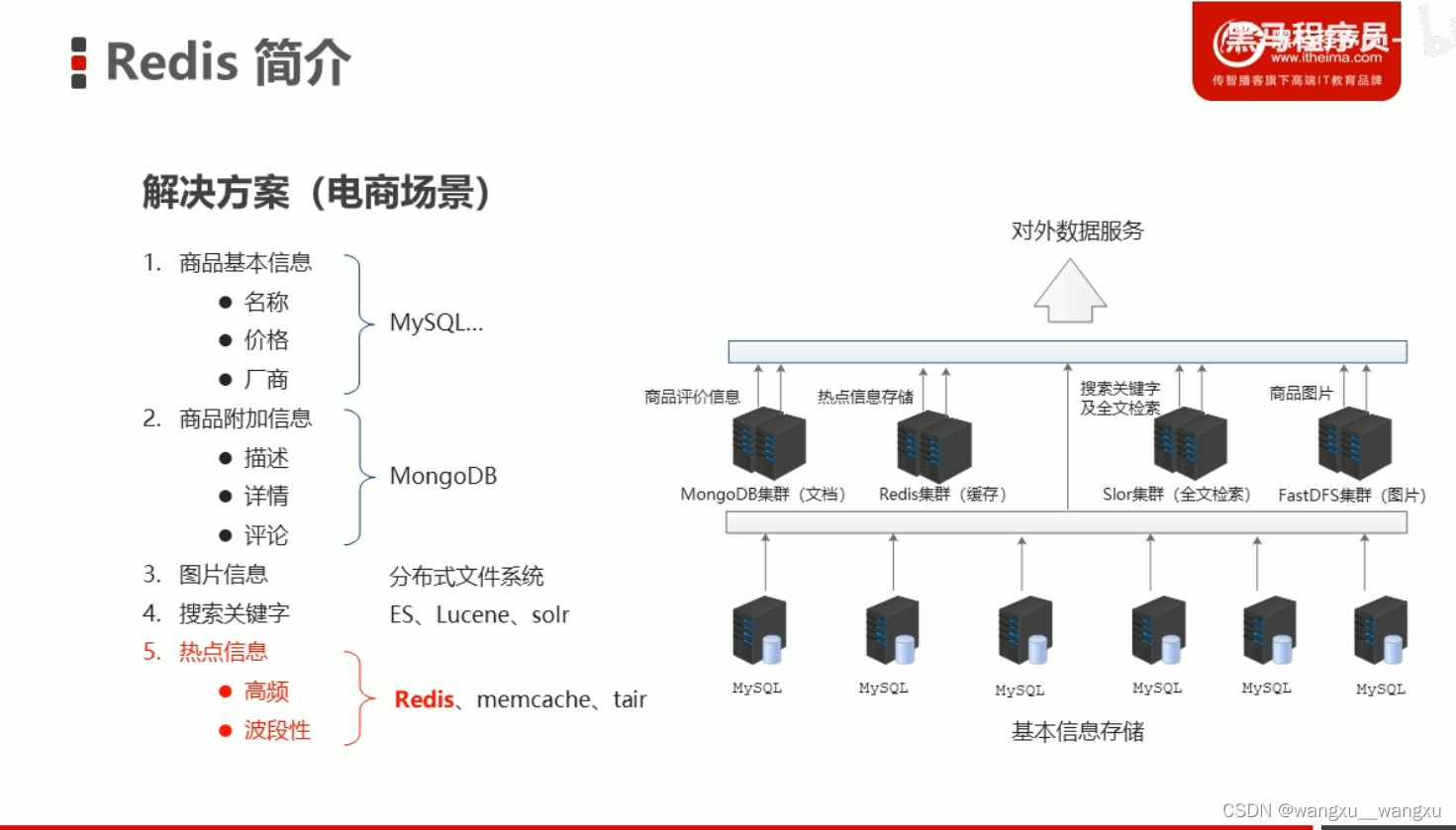
NoSql :即Not-Only SQL (泛指非关系型数据库),作为关系型数据库的补充
作用: 应对基于海量用户和海量数据前提下的数据处理问题
特征:
- 可扩容,可伸缩
- 大数据量下高性能
- 灵活的数据模型
- 高可用
常见的NoSQL数据库: - Redis
- memcache
- HBase
- MongoDB




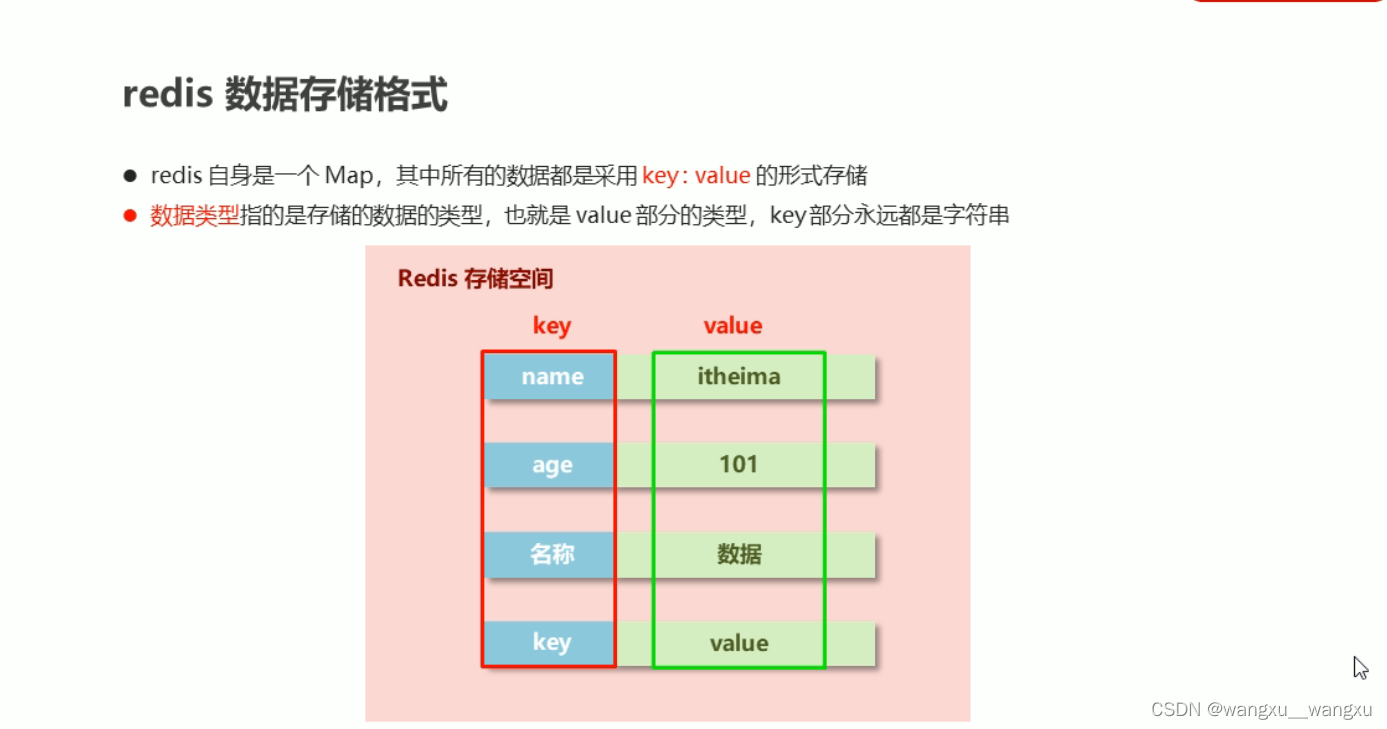
redis的数据类型 - String
- hash
- list
- set
- sorted_set

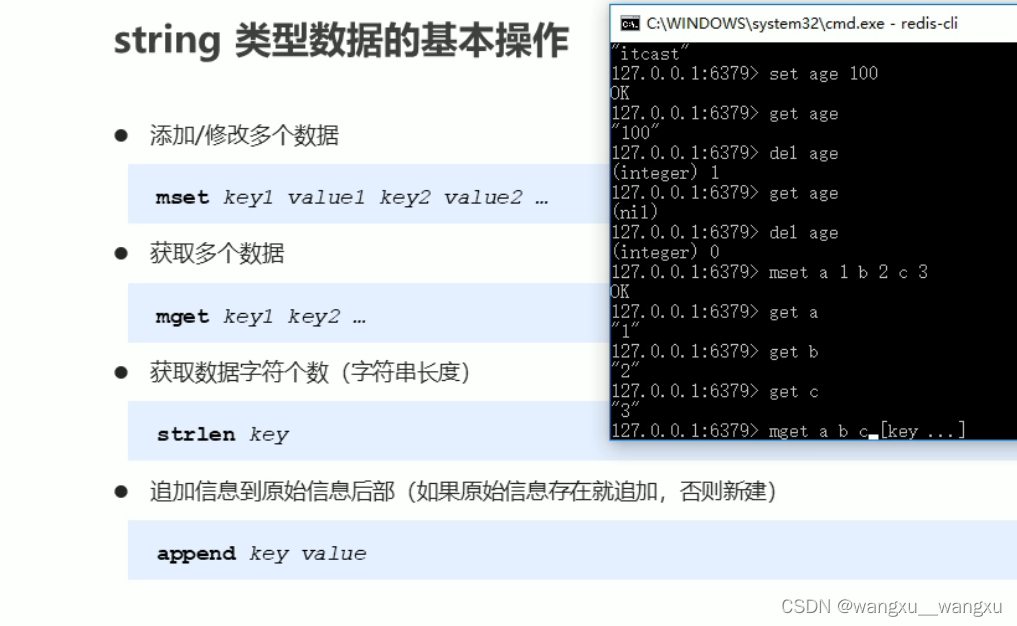



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









