







 本文详细介绍如何使用SparkGraphComputer将HDFS中的数据导入到JanusGraph中,涵盖定义图模式、生成邻接列表、使用Spark进行批量加载及常见问题解决。
本文详细介绍如何使用SparkGraphComputer将HDFS中的数据导入到JanusGraph中,涵盖定义图模式、生成邻接列表、使用Spark进行批量加载及常见问题解决。
通过SparkGraphComputer方式将HDFS中的数据导入到janusgraph中,janusgraph后端存储采用hbase,索引采用es,使用spark将原始表关系型数据生成janusgraph需要的adjacent list 。
一、定义graph
- graph schemal
编写 /home/hadoop/janusgraph_data/bulkingloading-schemal-define.groovy,定义graph schemal
[hadoop@bigdat-test-graph00.gz01 ]$ cat bulkingloading-schemal-define.groovy
def defineBulkloadingSchema(janusGraph) {
m = janusGraph.openManagement();
person = m.makeVertexLabel("person").make();
address = m.makeVertexLabel("address").make();
livesIn = m.makeEdgeLabel("livesIn").multiplicity(Multiplicity.MULTI).make();
firstname = m.makePropertyKey("firstname").dataType(String.class).make();
lastname = m.makePropertyKey("lastname").dataType(String.class).make();
country = m.makePropertyKey("country").dataType(String.class).make();
region = m.makePropertyKey("region").dataType(String.class).make();
//index
index = m.buildIndex("firstnameCompositeIndex", Vertex.class).addKey(firstname).unique().buildCompositeIndex()
//使用IncrementBulkLoader导入时,去掉下面注释
//bidIndex = m.buildIndex("byBulkLoaderVertexId", Vertex.class).addKey(blid).indexOnly(person).buildCompositeIndex()
m.commit()
}
- graph conf
graph conf:socket-bulkloading-test-janusgraph-hbase-es-server.properties
[hadoop@bigdat-test-graph00.gz01]$ cat $JANUSGRAPH-CURRENT/conf/gremlin-server/socket-bulkloading-test-janusgraph-hbase-es-server.properties
gremlin.graph=org.janusgraph.core.JanusGraphFactory
#hbase storage
storage.batch-loading=true
storage.backend=hbase
storage.hostname=zk01.nm01,zk02.nm02
storage.hbase.table = jg_bulkloading_test
#使用批量导入,此处一定要配置true
storage.batch-loading=true
#用户Janusgraph给每个顶点申请ID块,为了避免冲突,可以稍微配置大点
ids.block-size=100000000
#每次与后端存储引擎批处理时buffer的数据量
storage.buffer-size=102400
#hbase region数大小
storage.hbase.region-count = 20
storage.lock.expiry-time= 1800000
storage.connection-timeout=100000
#es index
#es index ,sample set by your ,index name
index.bulkloading_test.backend = elasticsearch
#es hostname
index.bulkloading_test.hostname = 192.0.0.61,192.0.0.62
index.bulkloading_test.port = 8300
index.bulkloading_test.index-name = bulkloading_test
#cache
cache.db-cache = true
cache.db-cache-clean-wait = 20
cache.db-cache-time = 180000
cache.db-cache-size = 0.5
二、准备adjacent list
adjacent list 生成参见 Spark 生成 janusgraph adjacent list
三、准备解析adjacent list的脚本
- parse adjacent script
定义解析parse adjacent script
[hadoop@bigdat-test-graph00.gz01]$ cat csv-script-input.groovy
def parse(line) {
//按照:分隔
def (vlabel, vid, props, adjacent) = line.split(/:/).toList()
//graph是一个全局变量,可以直接使用
def v1 = graph.addVertex(T.id, vid.toInteger(), T.label, vlabel)
switch (vlabel) {
case "person":
def (first, last) = props.split(/,/).toList()
v1.property("firstname", first)
v1.property("lastname", last)
def v2 = graph.addVertex(T.id, adjacent.toInteger(), T.label, "address")
v1.addInEdge("livesIn", v2)
break
case "address":
def (country, region) = props.split(/,/).toList()
v1.property("country", country)
v1.property("region", region)
def v2 = graph.addVertex(T.id, adjacent.toInteger(), T.label, "person")
v1.addOutEdge("livesIn", v2)
break
}
return v1
}
四、使用sparkComputer进行bulkloading
- 定义graph schemal
[hadoop@bigdat-test-graph00.gz01 ~]$ $janusgraph_home/bin/gremlin.sh
#获取graph
gremlin> graph = JanusGraphFactory.open('/home/hadoop/janusgraph-current/conf/gremlin-server/socket-bulkloading-test-janusgraph-hbase-es-server.properties')
#打印当前graph schemal
gremlin> m=graph.openManagement();
gremlin> m.printSchema();
gremlin> m.commit()
#删除之前的graph
gremlin> JanusGraphFactory.drop(graph);
#重新加载graph
gremlin> graph = JanusGraphFactory.open('/home/hadoop/janusgraph-current/conf/gremlin-server/socket-bulkloading-test-janusgraph-hbase-es-server.properties')
#加载groovy
gremlin> :load /home/hadoop/janusgraph_data/bulkingloading-schemal-define.groovy
#调用刚刚加载的groovy,定义graph schemal,defineBulkloadingSchema方法是在咱们编写的bulkingloading-schemal-define.groovy文件中定义的方法
defineBulkloadingSchema(graph)
- SparkGraphComputer的配置
vi janusgraph_home/conf/hadoop-graph/hadoop-script.properties
[hadoop@bigdat-gz-graph00.gz01 ~]$ vi janusgraph_home/conf/hadoop-graph/hadoop-script.properties
gremlin.graph=org.apache.tinkerpop.gremlin.hadoop.structure.HadoopGraph
gremlin.hadoop.graphReader=org.apache.tinkerpop.gremlin.hadoop.structure.io.script.ScriptInputFormat
gremlin.hadoop.jarsInDistributedCache=true
#adjacent list在hdfs的路径,配置到目录
gremlin.hadoop.inputLocation=/user/janusgraph/input
#定义的解析 adjacent的groovy文件在hdfs的位置,精确到groovy文件
gremlin.hadoop.scriptInputFormat.script=/user/janusgraph/csv-script-input.groovy
#####################################
# GiraphGraphComputer Configuration #
#####################################
giraph.minWorkers=2
giraph.maxWorkers=2
giraph.useOutOfCoreGraph=true
giraph.useOutOfCoreMessages=true
mapred.map.child.java.opts=-Xmx1024m
mapred.reduce.child.java.opts=-Xmx1024m
giraph.numInputThreads=4
giraph.numComputeThreads=4
giraph.maxPartitionsInMemory=1
giraph.userPartitionCount=2
## MapReduce of GiraphGraphComputer ##
mapreduce.job.maps=2
mapreduce.job.reduces=1
####################################
# SparkGraphComputer Configuration #
####################################
spark.master=yarn-client
spark.executor.memory=1g
spark.executor.instances=10
spark.executor.cores=2
#序列化生产环境建议使用KryoSerializer,Kryo比java原生序列化和反序列化效率高很多
spark.serializer=org.apache.spark.serializer.JavaSerializer
spark.yarn.queue=root.bigdata_janusgraph
#cache config
gremlin.spark.persistContext=true
gremlin.spark.graphStorageLevel=MEMORY_AND_DISK
- 编写运行sparkComputerGraph的脚本
$janusgraph_home/bin/yarn-gremlin.sh
[hadoop@bigdat-test-graph00.gz01 ~]$ vi $janusgraph_home/bin/gremlin.sh
#!/bin/bash
export HADOOP_HOME=/usr/local/hadoop-current
export JANUSGRAPH_HOME=/home/hadoop/janusgraph-current
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export JAVA_OPTIONS="$JAVA_OPTIONS -Djava.library.path=$HADOOP_HOME/lib/native"
export CLASSPATH=$HADOOP_CONF_DIR
#JANUSGRAPH_HOME为用户安装janusgraph的目录/data/janusgraph/
cd $JANUSGRAPH_HOME
./bin/gremlin.sh
- 执行
[hadoop@bigdat-test-graph00.gz01 ~]$ sh janusgraph-home/bin/yarn-gremlin.sh
gremlin> local_root='/home/hadoop/janusgraph-current'
gremlin> graph = GraphFactory.open("${local_root}/conf/gremlin-server/socket-bulkloading-test-janusgraph-hbase-es-server.properties")
gremlin> graph_script = GraphFactory.open("${local_root}/conf/hadoop-graph/hadoop-script.properties")
#adjacent list的input,hdfs目录
gremlin> graph_script.configuration().setProperty("gremlin.hadoop.inputLocation","/user/janusgraph/input")
#parse script groovy文件,hdfs文件
gremlin> graph_script.configuration().setProperty("gremlin.hadoop.scriptInputFormat.script", "/user/prod_kylin/janusgraph/csv-script-input.groovy")
#执行
gremlin> blvp = BulkLoaderVertexProgram.build().bulkLoader(OneTimeBulkLoader).writeGraph('/home/hadoop/janusgraph-current/conf/gremlin-server/socket-bulkloading-test-janusgraph-hbase-es-server.properties').create(graph_script)
gremlin> graph_script.compute(SparkGraphComputer).program(blvp).submit().get()
五、验证
#查看所有节点,用map kv形式打印出来,true打印信息更加全面,可以把label和id打印出来,否则只打印property
gremlin> gs.V().valueMap(true)
==>[country:[USA],label:address,id:4120,region:[NM]]
==>[firstname:[daniel],label:person,id:4136,lastname:[kuppitz]]
==>[firstname:[matthias],label:person,id:4280,lastname:[bröcheler]]
==>[country:[Germany],label:address,id:40964280,region:[NRW]]
==>[firstname:[marko],label:person,id:4312,lastname:[rodriguez]]
==>[country:[USA],label:address,id:8408,region:[WA]]
gremlin> gs.E().valueMap(true)
==>[label:livesIn,id:odxc3-36g-2dx-3bs]
==>[label:livesIn,id:1cruaf-oe08o-2dx-36w]
==>[label:livesIn,id:odxcr-6hk-2dx-3aw]
#查看所有边
gremlin> gs.E()
==>e[odxc3-36g-2dx-3bs][4120-livesIn->4312]
==>e[1cruaf-oe08o-2dx-36w][40964280-livesIn->4136]
==>e[odxcr-6hk-2dx-3aw][8408-livesIn->4280]
#查询一个firstname为daniel的定点
gremlin> daniel =gs.V().has('firstname','daniel').next();
==>v[4136]
#获取daniel这个定点的label
gremlin> gs.V(daniel).label();
==>person
#打印daniel这个定点的所有属性值
gremlin> gs.V(daniel).values();
==>daniel
==>kuppitz
#只打印property不答应,id和label,如果要打印id和label可以调用valueMap(true)
gremlin> gs.V(daniel).valueMap();
==>[firstname:[daniel],lastname:[kuppitz]]
//查询所有daniel节点的出边(daniel节点指向别的节点的边,箭头朝外),这里没有
gremlin> gs.V(daniel).outE();
//查询所有daniel节点的入边(别的节点指向daniel的边,箭头朝内)
gremlin> gs.V(daniel).inE();
==>e[1cruaf-oe08o-2dx-36w][40964280-livesIn->4136]
//查询所有指向daniel的节点
gremlin> gs.V(daniel).inE().outV();
==>v[40964280]
//返回某条边(gs.V(daniel).inE())的两边的定点
gremlin> gs.V(daniel).inE().bothV();
==>v[40964280]
==>v[4136]
gremlin> gs.V(daniel).inE().outV().values();
==>Germany
==>NRW
gremlin> gs.V(daniel).inE().outV().valueMap();
==>[country:[Germany],region:[NRW]]
#所有和daniel相连的定点
gremlin> gs.V(daniel).both();
==>v[40964280]
//出向定点
gremlin> gs.V(daniel).out();
//进向定点
gremlin> gs.V(daniel).in();
==>v[40964280]
六、常见问题
- org.apache.spark.SparkException: Unable to load YARN support
Caused by: org.apache.spark.SparkException: Unable to load YARN support
at org.apache.spark.deploy.SparkHadoopUtil$.liftedTree1$1(SparkHadoopUtil.scala:405)
......
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.ClassNotFoundException: org.apache.spark.deploy.yarn.YarnSparkHadoopUtil
......
at org.apache.spark.deploy.SparkHadoopUtil$.liftedTree1$1(SparkHadoopUtil.scala:401)
... 18 more
没有安装spark client,安装spark client ,设置SPARK_HOE.
[hadoop@bigdat-test-graph00.gz01 ~]$ spark-submit --version
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.3
/_/
Using Scala version 2.11.12, Java HotSpot(TM) 64-Bit Server VM, 1.8.0_77
Revision 2f6cf00c282dd8964f737d8057d8be62444dbbfb
Type --help for more information.
- Caused by: java.lang.NoClassDefFoundError: org/apache/spark/AccumulatorParam
Exception in thread "main" java.util.ServiceConfigurationError: org.apache.tinkerpop.gremlin.jsr223.GremlinPlugin: Provider org.apache.tinkerpop.gremlin.spark.jsr223.SparkGremlinPlugin could not be instantiated
.....
Caused by: java.lang.NoClassDefFoundError: org/apache/spark/AccumulatorParam
at java.lang.ClassLoader.defineClass1(Native Method)
.....
Caused by: java.lang.ClassNotFoundException: org.apache.spark.AccumulatorParam
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 28 more
缺少spark-core.jar包,将 s p a r k / j a r s / s p a r k − c o r e . j a r 拷 贝 到 spark/jars/spark-core.jar拷贝到 spark/jars/spark−core.jar拷贝到janusgraph_home/lib/下,使用spark客户端的jar包,之前lib下下的core jar包删除,避免包冲突
- java.util.concurrent.ExecutionException: java.lang.NoSuchFieldError: MAX_ROUNDED_ARRAY_LENGTH
java.util.concurrent.ExecutionException: java.lang.NoSuchFieldError: MAX_ROUNDED_ARRAY_LENGTH
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
......
Caused by: java.lang.NoSuchFieldError: MAX_ROUNDED_ARRAY_LENGTH
at org.apache.spark.internal.config.package$.<init>(package.scala:398)
at org.apache.spark.internal.config.package$.<clinit>(package.scala)
at org.apache.spark.SparkConf$.<init>(SparkConf.scala:730)
.....
spark包冲突。将janusgrap_home/lib下所有spark相关的jar包替换成spark-client/jars下的版本的jar包
pwd
$janusgrap_home/lib
ll |grep spark
-rw-r--r-- 1 hadoop hadoop 12465629 Dec 4 09:46 spark-core_2.11-2.2.0.jar.bak
-rw-r--r-- 1 hadoop hadoop 13517753 Mar 18 15:35 spark-core_2.11-2.4.3-102.jar
-rw-r--r-- 1 hadoop hadoop 132242 Dec 4 09:46 spark-gremlin-3.3.3.jar
-rw-r--r-- 1 hadoop hadoop 66818 Dec 4 09:46 spark-launcher_2.11-2.2.0.jar
-rw-r--r-- 1 hadoop hadoop 2375104 Dec 4 09:46 spark-network-common_2.11-2.2.0.jar
-rw-r--r-- 1 hadoop hadoop 62448 Dec 4 09:46 spark-network-shuffle_2.11-2.2.0.jar
-rw-r--r-- 1 hadoop hadoop 15457 Dec 4 09:46 spark-tags_2.11-2.2.0.jar
-rw-r--r-- 1 hadoop hadoop 46531 Dec 4 09:46 spark-unsafe_2.11-2.2.0.jar
- Caused by: java.lang.NoClassDefFoundError: org/apache/spark/util/kvstore/KVStore
java.util.concurrent.ExecutionException: java.lang.NoClassDefFoundError: org/apache/spark/util/kvstore/KVStore
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
......
Caused by: java.lang.NoClassDefFoundError: org/apache/spark/util/kvstore/KVStore
at org.apache.spark.SparkContext.<init>(SparkContext.scala:443)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2576)
at org.apache.spark.SparkContext.getOrCreate(SparkContext.scala)
at org.apache.tinkerpop.gremlin.spark.structure.Spark.create(Spark.java:52)
at org.apache.tinkerpop.gremlin.spark.structure.Spark.create(Spark.java:60)
at org.apache.tinkerpop.gremlin.spark.process.computer.SparkGraphComputer.lambda$submitWithExecutor$1(SparkGraphComputer.java:233)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.ClassNotFoundException: org.apache.spark.util.kvstore.KVStore
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 10 more
缺少spark-kvstore_2.11-2.4.3.jar包,将spark-client/jars下的此包拷贝到/janusgraph-home/lib/下
源码pom.xml中可添加:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-kvstore_2.11</artifactId>
<version>2.3.1</version>
</dependency>
- java.util.concurrent.ExecutionException: org.apache.spark.SparkException: Could not parse Master URL: ‘yarn’
java.util.concurrent.ExecutionException: org.apache.spark.SparkException: Could not parse Master URL: 'yarn'
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
......
Caused by: org.apache.spark.SparkException: Could not parse Master URL: 'yarn'
at org.apache.spark.SparkContext$.org$apache$spark$SparkContext$$createTaskScheduler(SparkContext.scala:2840)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:516)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2576)
at org.apache.spark.SparkContext.getOrCreate(SparkContext.scala)
at org.apache.tinkerpop.gremlin.spark.structure.Spark.create(Spark.java:52)
at org.apache.tinkerpop.gremlin.spark.structure.Spark.create(Spark.java:60)
at org.apache.tinkerpop.gremlin.spark.process.computer.SparkGraphComputer.lambda$submitWithExecutor$1(SparkGraphComputer.java:233)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
cp $spark_home/jars/spark-yarn_2.11-2.4.3.jar $janusgraph-home/lib/
源码pom文件中添加
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-yarn_2.11</artifactId>
<version>2.3.0</version>
</dependency>
- java.lang.NoClassDefFoundError: org/apache/xbean/asm6/ClassVisitor
Application Id: application_1582793079899_12320020, Tracking URL: http://bigdata-nmg-hdprm01.nmg01:8088/proxy/application_1582793079899_12320020/
16:35:50 ERROR org.apache.spark.network.server.TransportRequestHandler - Error sending result RpcResponse{requestId=9167846791504146052, body=NioManagedBuffer{buf=java.nio.HeapByteBuffer[pos=0 lim=47 cap=64]}} to /10.83.226.37:51394; closing connection
io.netty.channel.socket.ChannelOutputShutdownException: Channel output shutdown
at io.netty.channel.AbstractChannel$AbstractUnsafe.shutdownOutput(AbstractChannel.java:587)
......
Caused by: java.lang.NoSuchMethodError: org.apache.spark.network.util.AbstractFileRegion.transferred()J
at org.apache.spark.network.util.AbstractFileRegion.transfered(AbstractFileRegion.java:28)
at io.netty.channel.nio.AbstractNioByteChannel.doWrite(AbstractNioByteChannel.java:232)
at io.netty.channel.socket.nio.NioSocketChannel.doWrite(NioSocketChannel.java:282)
at io.netty.channel.AbstractChannel$AbstractUnsafe.flush0(AbstractChannel.java:879)
... 21 more
java.lang.NoClassDefFoundError: org/apache/xbean/asm6/ClassVisitor
[hadoop@bigdat-test-graph00.gz01 $ cp $spark_home/jars/xbean-asm6-shaded-4.8.jar $janusgraph-home/lib/
- java.lang.IllegalArgumentException: Compression codec com.hadoop.compression.lzo.LzoCodec not found.
io.netty.channel.socket.ChannelOutputShutdownException: Channel output shutdown
at io.netty.channel.AbstractChannel$AbstractUnsafe.shutdownOutput(AbstractChannel.java:587)
......
Caused by: java.lang.NoSuchMethodError: org.apache.spark.network.util.AbstractFileRegion.transferred()J
at org.apache.spark.network.util.AbstractFileRegion.transfered(AbstractFileRegion.java:28)
at io.netty.channel.nio.AbstractNioByteChannel.doWrite(AbstractNioByteChannel.java:232)
at io.netty.channel.socket.nio.NioSocketChannel.doWrite(NioSocketChannel.java:282)
at io.netty.channel.AbstractChannel$AbstractUnsafe.flush0(AbstractChannel.java:879)
... 21 more
java.lang.IllegalArgumentException: Compression codec com.hadoop.compression.lzo.LzoCodec not found.
[hadoop@bigdat-test-graph00.gz01]$ cp $hadoop-home/share/hadoop/tools/libhadoop-lzo-0.4.19.jar $janusgraph-home/lib/
- java.lang.ClassNotFoundException: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
MultiException[javax.servlet.UnavailableException: Class loading error for holder org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter-331f25f2, javax.servlet.UnavailableException: Class loading error for holder org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter-331f25f2]
......
Caused by: javax.servlet.UnavailableException: Class loading error for holder org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter-331f25f2
at org.spark_project.jetty.servlet.BaseHolder.doStart(BaseHolder.java:102)
at org.spark_project.jetty.servlet.FilterHolder.doStart(FilterHolder.java:92)
at org.spark_project.jetty.util.component.AbstractLifeCycle.start(AbstractLifeCycle.java:68)
at org.spark_project.jetty.servlet.ServletHandler.initialize(ServletHandler.java:872)
... 26 more
copy $hadoop_home/share/yarn/线下的所有server关键字的 jar包
- com.esotericsoftware.kryo.KryoException: Buffer underflow.
18:37:56 ERROR org.apache.spark.scheduler.TaskResultGetter - Exception while getting task result
com.esotericsoftware.kryo.KryoException: Buffer underflow.
Serialization trace:
org$apache$spark$storage$BlockManagerId$$topologyInfo_ (org.apache.spark.storage.BlockManagerId)
org$apache$spark$scheduler$CompressedMapStatus$$loc (org.apache.spark.scheduler.CompressedMapStatus)
at com.esotericsoftware.kryo.io.Input.require(Input.java:199)
......
at org.apache.spark.scheduler.TaskResultGetter$$anon$3.run(TaskResultGetter.scala:62)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
org.apache.spark.SparkException: Job aborted due to stage failure: Exception while getting task result: com.esotericsoftware.kryo.KryoException: Buffer underflow.
Serialization trace:
或者先试试指定成Java的序列化器: conf.set(“spark.serializer”, “org.apache.spark.serializer.JavaSerializer”)
加在spark-defaults.conf也可以或者配置在hadoop-scripts.properties中
- java.lang.IllegalArgumentException: Undefined type used in query: bulkLoader.vertex.id
gremlin> graph_script.compute(SparkGraphComputer).program(blvp).submit().get()
Application Id: application_1582793079899_12878627, Tracking URL: http://bigdata-nmg-hdprm01.nmg01:8088/proxy/application_1582793079899_12878627/
org.apache.spark.SparkException: Job aborted due to stage failure: Task 3 in stage 1.0 failed 4 times, most recent failure: Lost task 3.3 in stage 1.0 (TID 11, bigdata-nmg-hdp6804.nmg01.diditaxi.com, executor 3): java.lang.IllegalArgumentException: Undefined type used in query: bulkLoader.vertex.id
at org.janusgraph.graphdb.query.QueryUtil.getType(QueryUtil.java:71)
at org.janusgraph.graphdb.query.QueryUtil.constraints2QNF(QueryUtil.java:161)
......
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Driver stacktrace:
Type ':help' or ':h' for help.
这个错误通常是使用incrementLoad时才会报错,通常为定义的graph schemal中没有设置bulkLoader.vertex.id property
def defineGratefulDeadSchema(janusGraph) {
m = janusGraph.openManagement()
//人信息节点label
person = m.makeVertexLabel("person").make()
address = m.makeVertexLabel("address").make()
//properties
//使用IncrementBulkLoader导入时,去掉下面注释
//blid = m.makePropertyKey("bulkLoader.vertex.id").dataType(Long.class).make()
firstname = m.makePropertyKey("firstname").dataType(String.class).make()
lastname = m.makePropertyKey("lastname").dataType(String.class).make()
country = m.makePropertyKey("country").dataType(String.class).make()
region = m.makePropertyKey("region").dataType(String.class).make()
//index
index = m.buildIndex("firstnameCompositeIndex", Vertex.class).addKey(name).unique().buildCompositeIndex()
//使用IncrementBulkLoader导入时,去掉下面注释
//bidIndex = m.buildIndex("byBulkLoaderVertexId", Vertex.class).addKey(blid).indexOnly(person).buildCompositeIndex()
m.commit()
}
graph配置文件中
storage.backend=hbase
schema.default = none
# true:在批量导入或api添加时,会进行一致性校验,否则不会进行
# 本例子中的一致性:在name属性上建立了唯一索引,所以name不允许有重复值。
storage.batch-loading=true
graph = GraphFactory.open('conf/hadoop-graphson.properties')
blvp = BulkLoaderVertexProgram.build().bulkLoader(OneTimeBulkLoader).writeGraph('conf/janusgraph-test.properties').create(graph)
graph.compute(SparkGraphComputer).program(blvp).submit().get()
graph_script.compute(SparkGraphComputer).program(blvp).submit().get()
- java.lang.NoSuchMethodError: com.google.common.base.Stopwatch.createStarted()Lcom/google/common/base/Stopwatch;
java.util.concurrent.ExecutionException: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 1.0 failed 4 times, most recent failure: Lost task 0.3 in stage 1.0 (TID 14, bigdata-nmg-hdp297.nmg01.diditaxi.com, executor 9): java.lang.NoSuchMethodError: com.google.common.base.Stopwatch.createStarted()Lcom/google/common/base/Stopwatch;
at org.janusgraph.graphdb.database.idassigner.StandardIDPool$IDBlockGetter.<init>(StandardIDPool.java:269)
.....
at org.apache.tinkerpop.gremlin.process.traversal.step.map.AddVertexStartStep.processNextStart(AddVertexStartStep.java:91)
at org.apache.tinkerpop.gremlin.process.traversal.step.util.AbstractStep.next(AbstractStep.java:128)
at org.apache.tinkerpop.gremlin.process.traversal.step.util.AbstractStep.next(AbstractStep.java:38)
.....
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
将Stopwatch 包冲突,可以在janusgrap中将stopwatch的代码在janusgraph-core和janusgraph-hbase-core中repackaged,主要是StandardIDPool引用。创建一个新的包(如:com.shade.google.common.base),之前Stopwatch在com.google.common.base包下,如果报名相同还是有可能有覆盖的风险。然后将StandardIDPool import com.shade.google.common.base.Stopwatch

当然也可以使用maven的插件maven-shade-plugin进行包重命名:
<plugins>
<plugin>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<relocations>
<relocation>
<pattern>com.google.common.base</pattern>
<shadedPattern>com.shade.google.common.base</shadedPattern>
</relocation>
</relocations>
</configuration>
</execution>
</plugin>
</plugins>
- java.lang.IllegalArgumentException: Edge Label with given name does not exist: livesIn
at org.janusgraph.graphdb.types.typemaker.DisableDefaultSchemaMaker.makeEdgeLabel(DisableDefaultSchemaMaker.java:37)
at org.janusgraph.graphdb.types.typemaker.DisableDefaultSchemaMaker.makeEdgeLabel(DisableDefaultSchemaMaker.java:37)
at org.janusgraph.graphdb.transaction.StandardJanusGraphTx.getOrCreateEdgeLabel(StandardJanusGraphTx.java:1024)
at org.janusgraph.graphdb.vertices.AbstractVertex.addEdge(AbstractVertex.java:167)
at org.janusgraph.graphdb.vertices.AbstractVertex.addEdge(AbstractVertex.java:37)
at org.apache.tinkerpop.gremlin.process.computer.bulkloading.BulkLoader.createEdge(BulkLoader.java:54)
at org.apache.tinkerpop.gremlin.process.computer.bulkloading.OneTimeBulkLoader.getOrCreateEdge(OneTimeBulkLoader.java:57)
at org.apache.tinkerpop.gremlin.process.computer.bulkloading.BulkLoaderVertexProgram.lambda$executeInternal$4(BulkLoaderVertexProgram.java:252)
at java.util.Iterator.forEachRemaining(Iterator.java:116)
......
graph中缺少定义livesIn这个label,可以通过下面的方式添加,或者在define schemal的时候加上。
m = graph.openManagement();
gremlin> m.printSchema()
livesIn = m.makeEdgeLabel("livesIn").multiplicity(Multiplicity.MULTI).make();
m.printSchema()
m.commit()
15.java.lang.IllegalStateException: The property does not exist as the key has no associated value for the provided element: v[2]:bulkLoader.vertex.id
Application Id: application_1582793079899_13556183, Tracking URL: http://bigdata-nmg-hdprm01.nmg01:8088/proxy/application_1582793079899_13556183/
org.apache.spark.SparkException: Job aborted due to stage failure: Task 2 in stage 5.0 failed 4 times, most recent failure: Lost task 2.3 in stage 5.0 (TID 18, bigdata-nmg-hdp5528.nmg01.diditaxi.com, executor 9): java.lang.IllegalStateException: The property does not exist as the key has no associated value for the provided element: v[2]:bulkLoader.vertex.id
at org.apache.tinkerpop.gremlin.structure.Property$Exceptions.propertyDoesNotExist(Property.java:155)
at org.apache.tinkerpop.gremlin.structure.Element.lambda$value$1(Element.java:94)
......
https://blog.youkuaiyun.com/zyc88888/article/details/80678184
每个顶点的id不能相同,报错说明adjacent中不止一个顶点的id为2.需要把顶点的id全部改为不同。
七、jar包冲突解决
如上第六章中的各种jar包冲突问题,主要是是由于spark或者hadoop等的相关jar包冲突导致,我们可以在打包janusgraph的安装包时不将spark和hadoop的相关jar打进去,在使用的时候直接将spark和hadoop的相关jar包引用。
去除spark和hadoop jar
- janusgraph-all模块pom.xml文件中修改如下:
去除janusgraph-hadoop依赖模块中去除spark-core,hadoop-common模块的scope改为provided.
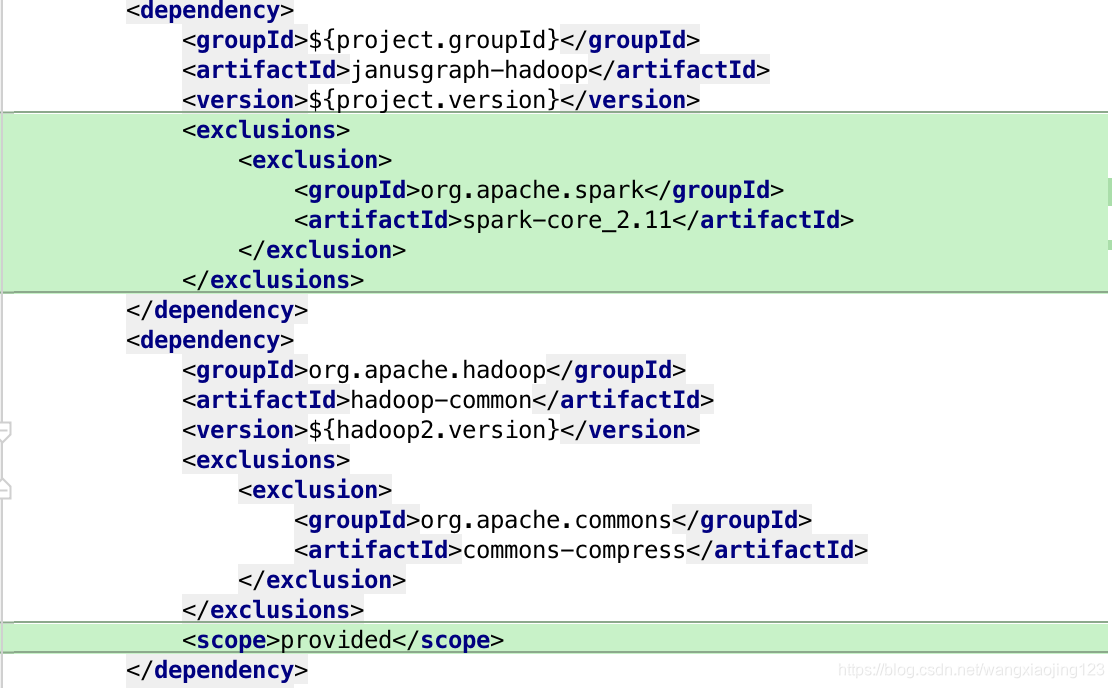
- janusgraph-dist模块pom.xml文件中修改如下:
hadoop-gremlin依赖模块中去除hadoop-hdfs,hadoop-common;spark-gremlin模块中去除spark-core依赖

执行命令直接从本地spark home和hadoop home中获取
- 添加env.sh文件
在janusgraph-dist/assembly/static/bin添加一个env.sh文件,设置基本环节和hadoop与spark 的jar包依赖
vi janusgraph-dist/assembly/static/bin/env.sh
#!/bin/bash
#
#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
#
export HADOOP_HOME=/home/hadoop/hadoop-current
export JANUSGRAPH_HOME=/home/hadoop/janusgraph-current
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/home/hadoop//spark-current
export CLASSPATH=$SPARK_HOME/jars/*:$HADOOP_CONF_DIR:$HADOOP_HOME/share/hadoop/common:$HADOOP_HOME/share/hadoop/hdfs/*:$HADOOP_HOME/share/hadoop/tools/lib/*:$HADOOP_HOME/share/hadoop/yarn/*
- 修改gremlin.sh和gremlin-server.sh文件
vi gremlin.sh
set -e
set -u
#添加引用env.sh文件
DIR="$( cd "$( dirname "$0" )" && pwd )"
source $DIR/env.sh
USER_DIR=`pwd`
......
vi gremlin-server.sh
# Load Environment Variables from file if present. This is required for System V.
#添加引用env.sh文件
DIR="$( cd "$( dirname "$0" )" && pwd )"
source $DIR/env.sh
[ -f /etc/default/janusgraph ] && . /etc/default/janusgraph
......

















 364
364




 到【灌水乐园】发言
到【灌水乐园】发言







