







 在单机模式下,Nebula在批量插入性能上展现出显著优势,达到ArangoDB的5-6倍。而单条插入,ArangoDB的性能约为Nebula的2倍。在聚合查询上,ArangoDB的速度是Nebula的3-4倍,分页查询也有类似差距。精准匹配两者表现相近。
在单机模式下,Nebula在批量插入性能上展现出显著优势,达到ArangoDB的5-6倍。而单条插入,ArangoDB的性能约为Nebula的2倍。在聚合查询上,ArangoDB的速度是Nebula的3-4倍,分页查询也有类似差距。精准匹配两者表现相近。
前置条件: 单机模式,默认配置,不做任何修改。 客户端测试为单线程操作测试。
服务器机器配置: 4核16g内存机器, centos7, 普通磁盘,非ssd
客户端机器配置: java driver自写的插入程序,同机器同执行环境。
批量插入1000W条数据, 单批次5000条。
nebula:
插入: 10000000, 耗时: 100878
总计耗时: 100s, tps: 10w/s
arangodb:
插入: 10000000, 耗时: 637854
总计耗时: 638s, tps: 1.57w/s
插入语句
nebula: insert vertex player(name, age) values('"t1", 42), ("t2", 42);
arangodb: arangodb.collection.insertDocument(docs);
nebula批量插入主要通过拼接nql语句方式,然后调用client.execute(nql)进行插入。
arangodb使用collection(文档)类下的批量插入文档方法,输入的参数为list对象。
结论: 批量插入 nebula的性能可以达到arangodb的6~7倍左右。
单条插入100w。
nebula
插入: 1000000, 耗时: 1815231
总计耗时:1815s, tps: 550/s
arangodb
插入: 1000000, 耗时: 935855
总计耗时: 935, tps: 1070/s
插入语句同批量插入语句
结论: 单条插入arangodb为nebula性能2倍。
聚合查询(1000w总数据)
nebula, 需要先创建字段索引,否则无法进行聚合查询,ps: 未发现使用id方式进行聚合查询,有不对地方请告知
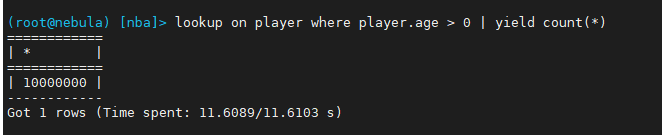
耗时&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









