







 本文深入解析深度学习中各类优化器的工作原理,包括批量梯度下降法(BGD)、随机梯度下降法(SGD)、小批量梯度下降法(MBGD)、Momentum、AdaGrad、Adam和RMSprop,探讨它们在训练过程中的优势与局限。
本文深入解析深度学习中各类优化器的工作原理,包括批量梯度下降法(BGD)、随机梯度下降法(SGD)、小批量梯度下降法(MBGD)、Momentum、AdaGrad、Adam和RMSprop,探讨它们在训练过程中的优势与局限。
梯度下降法
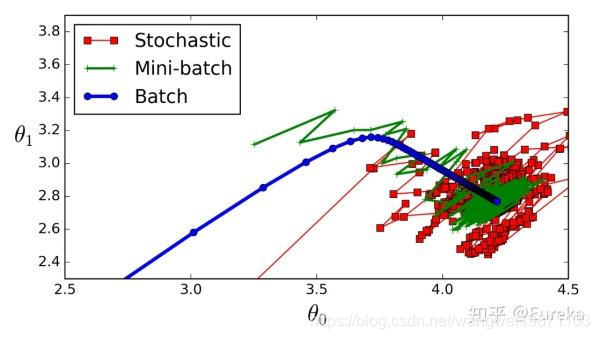
批量梯度下降法(BGD)
所谓批量,就是一次性把所有样本都进行训练,因为所有的样本一起迭代算一次,所以下降方向相对比较准确,不会有太大的偏移,同时由于样本数太多,可能迭代一次会比较慢。
随机梯度下降法(SGD)
每次只迭代一个样本,速度快,随机偏移比较大,但是总体方向是对的,容易到达局部最优,因为是单个样本训练,并非全部一起训练。
小批量梯度下降法(MBGD)
刚好在BGD 和SGD中间,取一部分训练,既保证了速度,有保证了准确性,是这一种折中的方式
Momentum
可以看做是有惯性的梯度下降法,因为有惯性,所以有时候可以跳出局部最小点。
AdaGrad
是一种能调节学习率的梯度下降算法。
Adam
Momentum和AdaGrad的结合体。
RMSprop
可以缓解AdaGrad的学习率下降太快的问题。
具体还是看图直观
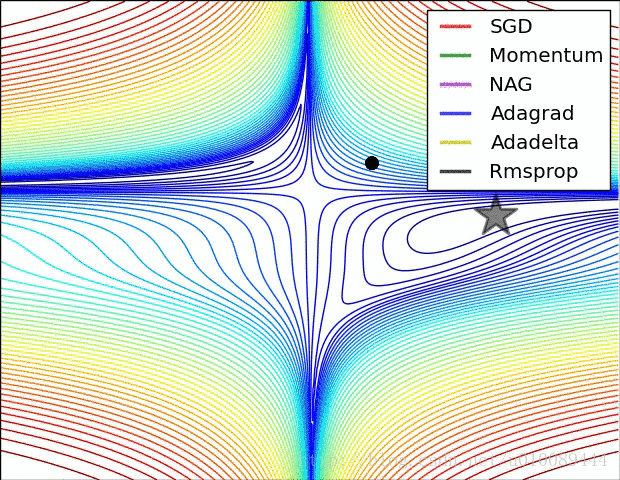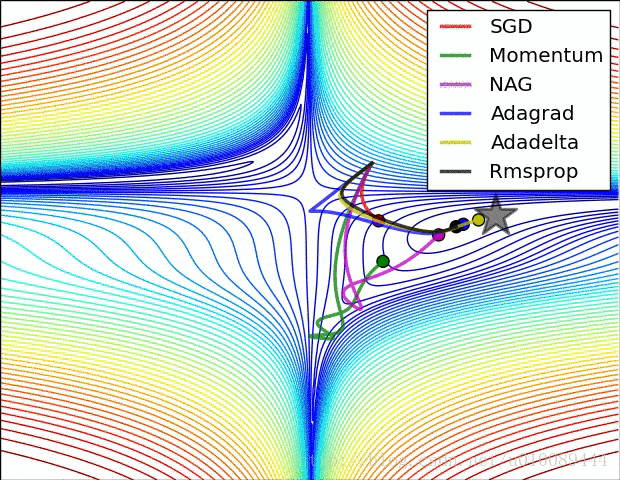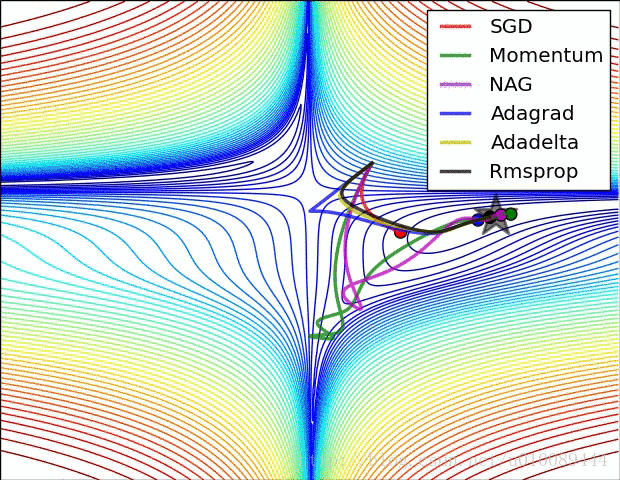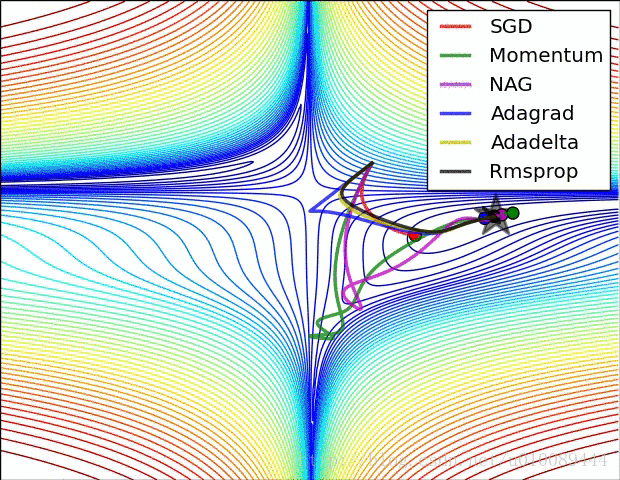
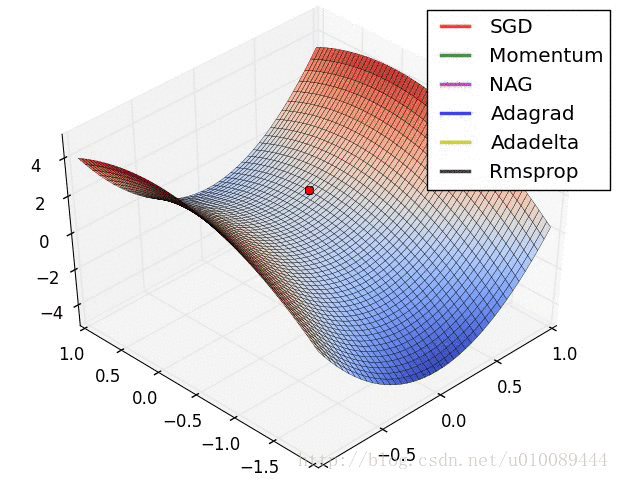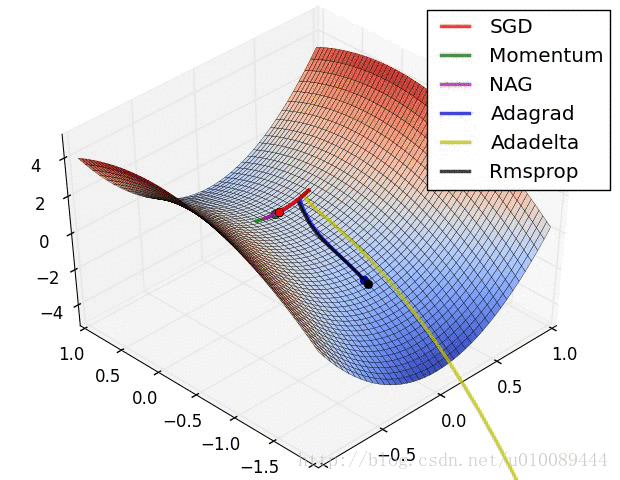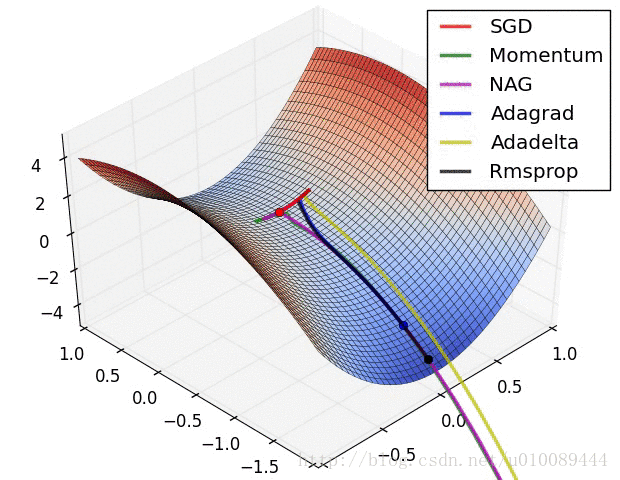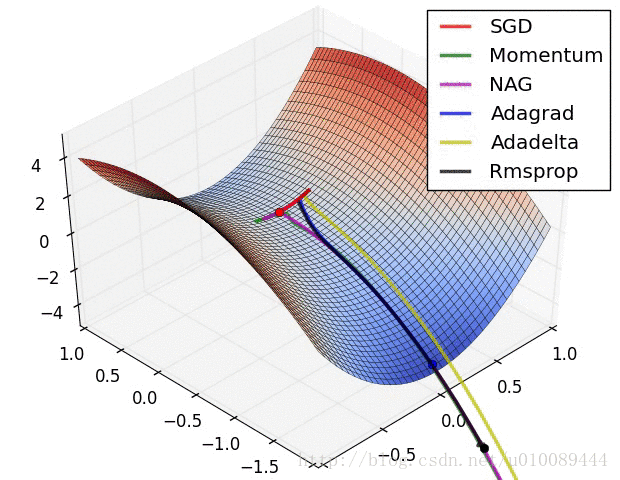
好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵,图片均来自网络,侵删。

















 1586
1586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









