



mysql内存优化,在哪里优化?怎么配置,配置是哪条参数,默认值是多少?
分myisam、innodb和tmp临时区
即使表用的不是myisam,但内部的临时磁盘表还是myisam表,key_buffer_size决定索引处理的速度,一般用innodb表时,key_buffer_size一般取默认值的一半32m,默认值为64m。
innodb_buffer_pool_size专用与mysql服务器设置大小,但不宜过大,一半为操作系统内存的百分之七八十
还有tmp临时区?
常用的应用服务,一个请求怎么到这个应用上?
在这个应用上怎么转发的?根据什么模块,什么协议,总得一个流程。
这个应用的核心优化!这个应用是什么语言写的,架构是什么?
比如nginx具体的配置
开机启动顺序
01)开机自检(BIOS);检测出第一个能够引导系统的设备
02)MBR引导;运行放在MBR扇区里的启动GRUB引导程序
03)GRUB菜单;获取内核和镜像文件系统的设置以及路径位置。
04)加载linux内核;把内核和镜像文件系统加载到内存中。
05)init进程初始化
fastDFS是什么?
开源的轻量级分布式文件系统
lua是什么?
小巧的脚本语言,可以进行独立编程,但是大部分情况下是嵌入到大型语言里面,作为一个库。
squid是什么?
用来缓冲Internet数据的软件
CDN是什么?
内容分发网络,能够有效解决网络带宽小,用户访问量大,网点分布不均等问题
核心:数据流向,服务的核心
mysql的储存过程?
存储过程是一组为了完成特定功能的SQL语句集合。
死锁现象?
指两个或两个以上事务在执行过程中因争抢锁资源而造成的互相等待的现象。
如何避免发生死锁现象?
01)没有长事务。
02)及时提交事务。
03)设置锁超时等待innodb_lock_wait_timeout。
04)降低事务隔离级别。
什么是事务?
事务是数据库操作的最小单元,这些操作作为一个整体一起向系统提交,要么都执行、要么都不执行;
事务四大特性:
原子性,一致性,隔离性,持久性
01)脏读?
一个事务读取到另一个事务未提交的数据。
02)不可重复读?
指一个事务多次读取同一个数据,在这个事务还没有结束的时候,另一个事务也访问了该数据,并修改了该数据,时第一个事务前后两次读取的数据不一致。重点在update,修改
03)幻读?
指一个事务读取到另一个事务的insert数据,重点在于新增或者删除
事物的隔离级别?
未提交读,已提交读,可重复读,可串行化。
什么时候创建索引?
数据量大,有特殊字段,使用率高的字段时创建索引,来提高查询性能。
存储引擎?
存储引擎就是指表的类型。数据库的存储类型决定了表在计算机中的存储方式。
用户可以根据不同的存储方式、是否进行事务处理等来选择合适的存储引擎。
视图?
视图(View)是一种虚拟存在的表,不实际存在数据库中。
你公司怎么进行mysql备份?
利用完备、增备和 binlogs 结合进行备份,一般周六凌晨1点进行完备,每天的凌晨1点进行增备。
主要备份工具:mysqldump逻辑备份工具
mysql5.6和mysql5.7的区别?
01)编译安装的区别,5.7多了一个boots库。
02)初始化方式不同:
5.6 版本使用 /usr/local/mysql/scripts/mysql_install_db 初始化;
5.7 版本使用 /usr/local/mysql/bin/mysqld 初始化。
03)MySQL5.7 提供 JSON格式 数据
MySQL5.7 支持多主一从
做高可用方式不同
mysql中内存怎么优化?优化哪个参数?默认值多少,代表了什么?
01)key_buffer_size
key_buffer_size决定MyISAM索引块缓存区的大小,直接影响MyISAM表的存取效率。对于一般MyISAM数据库,建议至少将1/4可用内存分配给key_buffer_size。
02)read_buffer_size和read_rnd_buffer_size
扫描MyISAM表,可以通过增大read_buffer_size的值来提高性能。
03)innodb_buffer_pool_size
innodb_buffer_pool_size决定InnoDB缓存区大小。在保障操作系统及其他程序有足够的内存可用的情况下该值越大,性能越好。
04)调整innodb_log_buffer_size
innodb_log_buffer_size决定InnoDB重做日志缓存池的大小。提高innodb_log_buffer_size来提高事务处理的性能。
Innodb缓冲池(占用物理内存80%)
# 控制缓冲池的大小(10G)
Innodb_buffer_pool_size = 10G
# 划分缓冲池几个区域,如果是10G的话划分5个区域,每个区域2G,默认值-1,划分8个区域,大于1G才有意义
Innodb_buffer_pool_instances = -1
mysql可以从哪些方面优化?
1、主机层面:五大资源+内核
2、服务层面:服务在架构中的核心功能,–》 核心优化
3、业务层面:
4、对接(Tomcat connector)
ansible是什么?怎么用?
01)ansible是新出现的自动化运维工具,基于Python开发。实现了批量系统配置、批量程序部署、批量运行命令等功能。
02)ansible是基于模块工作的,本身没有批量部署的能力。真正具有批量部署的是ansible所运行的模块,ansible只是提供一种框架。
主要包括:
(1)、连接插件connection plugins:负责和被监控端实现通信;
(2)、host inventory:指定操作的主机,是一个配置文件里面定义监控的主机;
(3)、各种模块核心模块、command模块、自定义模块;
(4)、借助于插件完成记录日志邮件等功能;
(5)、playbook:剧本执行多个任务时,非必需可以让节点一次性运行多个任务。
LVS?四层 七层
LVS三种工作模式:
01)NAT模式:
通过数据报头的修改,使得位于企业内部的私有IP地址可以访问外网,以及外部用用户可以访问位于公司内部的私有IP主机。
LVS负载调度器可以使用两块网卡配置不同的IP地址,
eth0设置为私钥IP与内部网络通过交换设备相互连接,eth1设备为外网IP与外部网络联通。
02)tun(隧道)模式:
将请求与响应数据分离,让调度器仅处理数据请求,而让真实服务器响应数据包直接返回给客户端。
03)DR模式(直接路由模式):
直接路由模式(DR模式)要求调度器与后端服务器必须在同一个局域网内,VIP地址需要在调度器与后端所有的服务器间共享,
因为最终的真实服务器给客户端回应数据包时需要设置源IP为VIP地址,目标IP为客户端IP,
这样客户端访问的是调度器的VIP地址,回应的源地址也依然是该VIP地址(真实服务器上的VIP),
客户端是感觉不到后端服务器存在的。
Redis啥语言开发的?
Redis使用C语言开发的一个开源高性能键值对(key-value)数据库。
适用场景:缓存,秒杀,在线列表,网站访问统计等;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4zCSU75c-1640693221465)(C:\Users\杨醇\AppData\Roaming\Typora\typora-user-images\1640693151321.png)]](https://i-blog.csdnimg.cn/blog_migrate/eb2fc02306129fed2822d3adff6b562c.png)
qos?
服务质量,能够解决网络延迟和阻塞等问题的一种技术,能够根据用户的要求分配和调度资源,对不同数据流提供不同的服务质量,对实时性强且重要的数据优先处理,对普通的数据,降低处理优先级,网络阻塞时甚至丢弃
tsdb?
可伸缩的时间序列数据库
redisDMZ区域–》dmz.xml文件(非军事区域防火墙规则文件)
用于:对于非军事区域中的计算机,这些计算机可公开访问,并且对内部网络的访问权限有限。
允许:明确指定的<入站连接>
拒绝:未明确指定的<入站连接>
关系数据库和非关数据库(nosql,不仅仅是spl) 的区别
①数据存储方式不同
关系型数据库:依赖于关系模型E-R图,同时以二维表格式的方式存储数据
非关数据库:除了以表格形式存储以外,通常会以大块的形式组合在一起进行存储数据(例如键值对)
②扩展方式不同
关系型数据库:纵向扩展,天然表格式
非关数据库:横向扩展,天然分布式,增加节点,扩展架构
③对事务性的支持不同
关系型数据库:特别适合高事务性要求和需要控制执行计划的任务,并且易于回滚事务
非关数据库:虽然非关数据库也可以使用事务操作,但稳定性不如关系数据库,其价值点在于高扩展性和大数据量处理方面
在读写分离的MySQL数据库环境中,可以把经常访问的数据存储在非关数据库中(即把非关数据库作缓存数据库),来提升访问速度。
cpu–》内存—》磁盘 cpu的一级缓存二级缓存三级缓存
MySQL高热数据—》redis
web-----》redis—》mysql
redis 集群模式 存储机制------》在redis cluster中,如果想要存入一个key-value,这个key首先会通过CRC16算法(和16384取余), 结果会对应上0-16383之间的哈希槽(hash slot), 最后,redis cluster会将key-value放置在对应的哈希槽中。
redis是内存数据库,基于内存运行,所以处理速度快
是单进程模型
单进程快速的原因: epoll i/o多路复用机制 + 回调函数机制
epoll机制的优势:①epoll没有最大并发连接限制,它的上限是系统的最大文件打开数
②epoll只管你活跃的连接,而跟连接总数无关(活跃状态根据fd文件描述符绑定socket套接字来监听的)
③内存拷贝,epoll在这点上使用了共享内存,内存拷贝也就省略了。
i/o多路复用就是通过一种机制,可以监视多个描述符,一旦某个描述符就绪,能够通知程序进行相应的操作。
即使用一个线程来追踪多个socket的状态来管理多个I/O。
回调函数即预先定义具体的执行过程(定义一个方法),等待调用,当一个线程执行时,可以根据触发器和钩子来完成回调。目的是提高处理性能和节省资源。
redis优点:具有极高的数据读写速度,支持丰富的数据类型,支持数据的持久化,原子性: ,支持数据备份
redis 分布式锁 目的是为了缓解高并发压力
setnx + 分布式锁 执行setnx,若成功再执行expire添加过期时间
持久化功能?
分类:RDB持久化:将redis某一时刻的数据持久化到磁盘中,是一种快照式的持久化方法
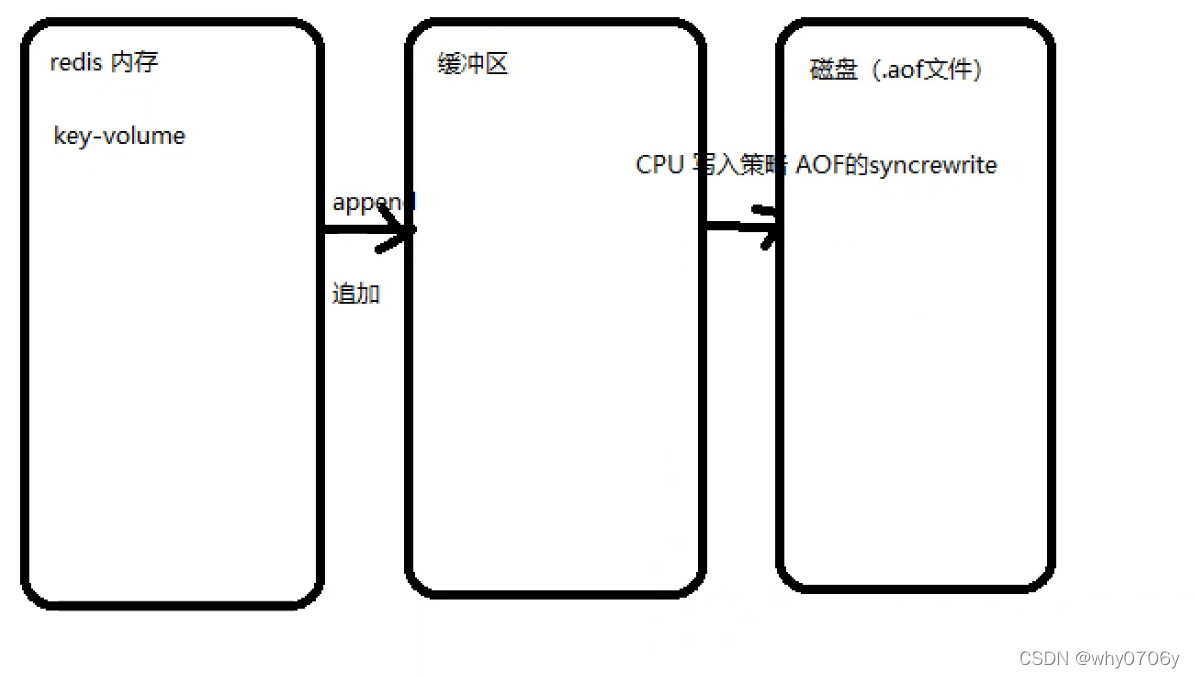
AOF持久化:将redis执行过的所以写指令记录下来,在下次redis重新启动时,只要把这些从前到后再重复执行一遍,就可以实现数据恢复了。
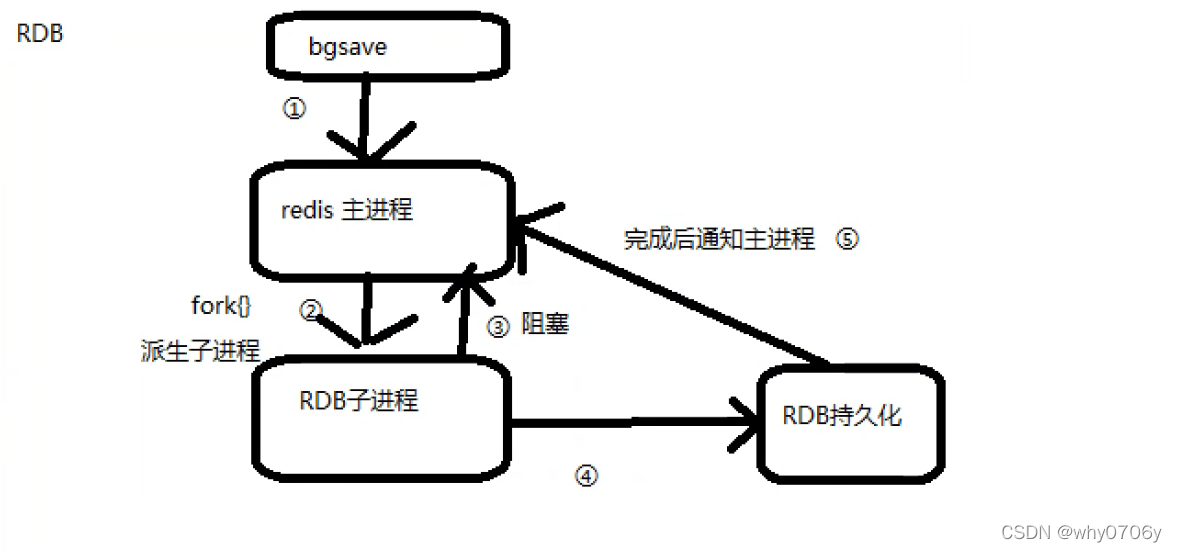
RDB持久化触发方式:①手动触发:直接执行bgsave持久化命令
②自动出发:按照规定周期执行的语句的数量来触发,配置文件中例如save m n ——》save 90 10
bgsave执行时,会控制RDB子进程在指定的位置创建.rdb文件,特性是RDB持久化生产的文件只记录的结果
同时为了提高处理效率和减少落地在磁盘中占用体积,RDB会对数据进行压缩处理
特殊的触发方式:主动关闭redis,但RDB持久化优先级较低
应用场景:①主动关闭时,触发RDB(redis默认开启RDB)
②主从复制时,master同步给slave时,会触发RDB(全量复制),然后触发AOF的增量复制。
③在redis重启时,当AOF未开启时,默认开启RDB恢复数据。
AOF持久化触发方式:①always:每产生一条,就同步一条
②no :不自动触发
③every second:每秒同步一次
redis缓冲区溢出过载问题的解决办法:单进程变多进程,提高并发能力
在redis入口处限流(流量控制):令牌桶算法
漏桶算法
LRU算法(缓存淘汰机制)
redis命中机制 遗忘机制
redis过期策略:定期删除 :保证两种持久化完成的情况下,同时业务不繁忙/终止业务的时候,删除。为了解决缓存压力过大而导致使用swap交换分区以及牵扯到的其他功能模块(AOF的持久化)问题
+
惰性删除(默认):随机淘汰,淘汰近期命中较少的数据
rsync+sersync双向同步
**MySQL优化:优化索引,在合适的地方创建索引,MySQL进行架构优化(读写压力不均匀或压力都很大,做读写分离),冗余架构mha,需要同步做主从复制,优化日志做日志分割,优化查询语句。重视读,选择磁盘阵列,采取bgp的方式来进行路由同步,网卡做bond,链路做冗余,考虑到mha的小缺陷(触发主从切换过后mha会断掉),做mm架构
redis主从模式:①从—》主发送sync同步请求
②主进行全量复制—》RDB快照
③主在进行完全量复制后,再将缓存中的数据通过aof的方式传递给从
以上初始化完成后
④持续性的由主—》同步给从
redis哨兵模式:①主节点的信息是配置在哨兵的配置文件中
②哨兵节点会和配置的主节点建立两个连接 命令连接和订阅连接
③哨兵会通过命令连接每10s发送一次info命令,通过info命令,主节点会返回自己的run_id和自己的从节点信息
④哨兵会对这些从节点也建立两条连接命令连接和订阅连接
⑤哨兵通过命令连接向从节点发送info命令,获取到他的一些信息:
run_id(redis服务器id)
role(职能)
从服务器的复制偏移量offset
其他
⑥通过命令连接向服务器的sentinel:hello频道发送一条信息,内容包括自己的ip端口、run id、配置
⑦通过订阅连接对服务器的sentinel:hello频道做监听,所以所有的向该频道发送的哨兵信息都能接收到
⑧解析监听到的信息,进行分析提取,就可以知道还有哪些别的哨兵服务节点也在监听这些主从节点了,更新结构体将这些哨兵节点记录下来
⑨向观察到的其他哨兵节点建立命令连接----没有订阅连接
rsync的应用场景:
增量同步
备份:辅助工具(MySQL主-从复制 rsync + inotify ——————》趋近于一致)
rsync + sersync(在并发量不高的场景中实现双向同步)
迁移:mysql从主机a迁移到主机b (一主两从模式)
一主两从模式迁移方案:
①确定迁移时间、业务线停止的时间、要写文档描述具体操作、要发邮件审批
②确认迁移后的节点的环境问题(资源环境+系统的依赖环境+mysql内部的格式环境–自增长)
③rsync + inotify持续同步
④测试、之前还要编写回滚方案
⑤提交检修申请 22:00—24:00
ib网络传输协议 弥补tcpip丢包


















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









