



day06-异常
常见异常
NullPointException
ArrayIndexOutofBoundException
ClassCastException
ArithmeticException
NumberFormatException
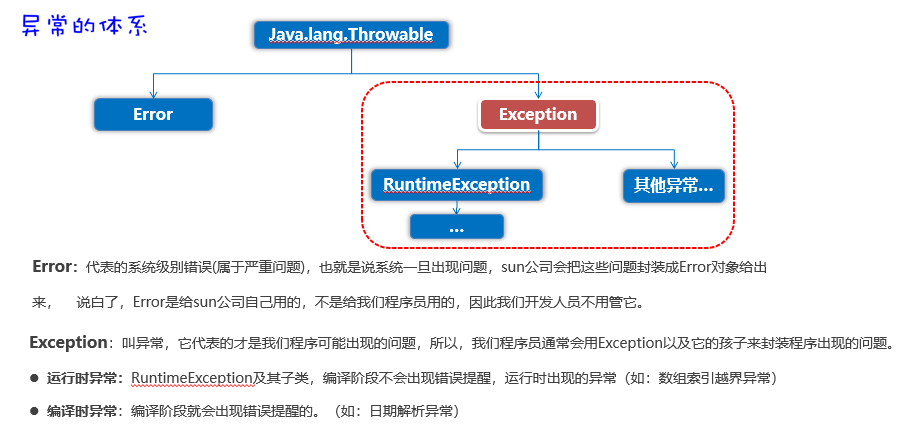
异常的体系

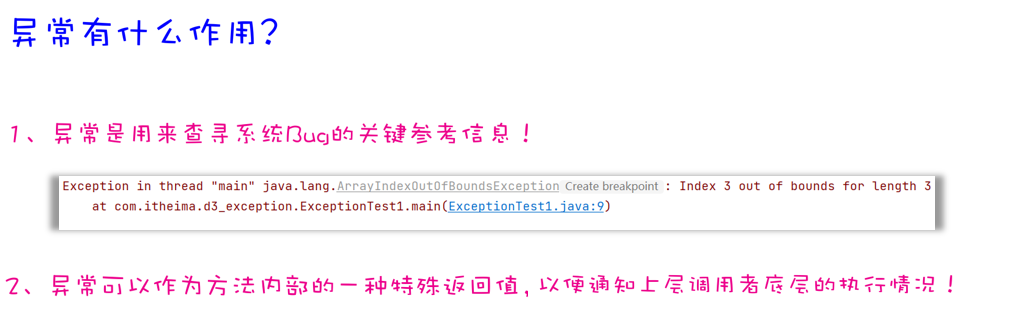
异常的作用
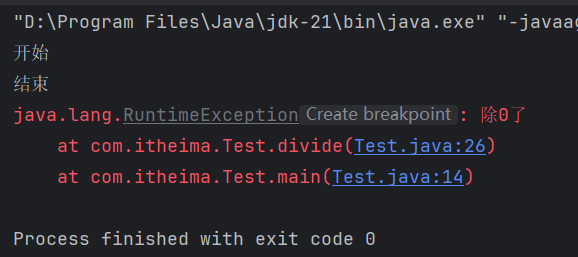
举例:异常作为方法内部的一种特殊返回值
public class Test {
public static void main(String[] args) {
System.out.println("开始");
try {
divide(10,0);
}catch (RuntimeException exception){
exception.printStackTrace();
}
System.out.println("结束");
}
public static int divide(int a, int b){
if(b==0){
//抛出一个异常作为返回值,通知上层,这里出现了bug
throw new RuntimeException("除0了");
}
return a/b;
}
}
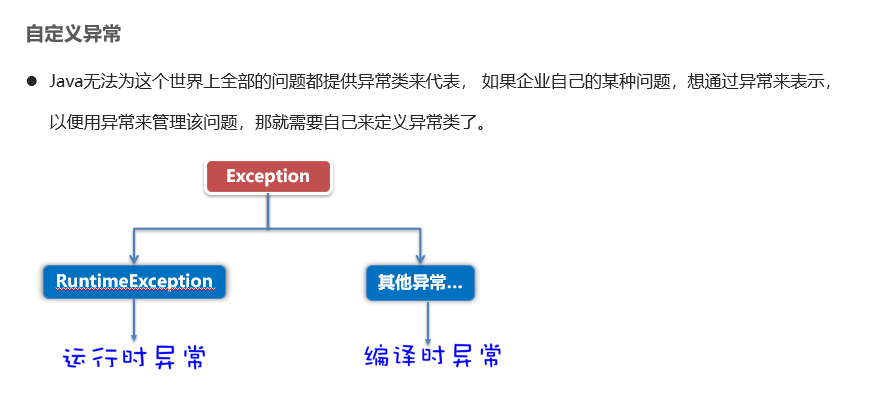
自定义异常

throw : 方法内部使用的,创建异常并从此点抛出
throws : 方法上,抛出方法内部的异常
自定义运行时异常
public class AgeIllegalRuntimeException extends RuntimeException{//继承RuntimeException
public AgeIllegalRuntimeException() {
}
public AgeIllegalRuntimeException(String message) {
super(message);
}
}
////////////////////////////////////////////////
public class ExceptionDemo {
public static void main(String[] args) {
System.out.println("开始");
try {
save(250);
} catch (Exception e) {
e.printStackTrace();//打印异常信息
}
System.out.println("结束");
}
public static void save(int age){
if(age<=0 || age>=150){
throw new AgeIllegalRuntimeException("年龄范围错误");
}
System.out.println("年龄保存成功!");
}
}
自定义编译时异常(提醒太强烈,太干扰程序员)
编译时异常一定要处理。
处理方式有两种:
- throws(抛出异常给调用者,调用者必须处理)
- 或者try catch(自己处理)
public class AgeIllegalException extends Exception{////继承Exception
public AgeIllegalException() {
}
public AgeIllegalException(String message) {
super(message);
}
}
实际使用的时候,更常用的是自定义运行时异常!!!!!!
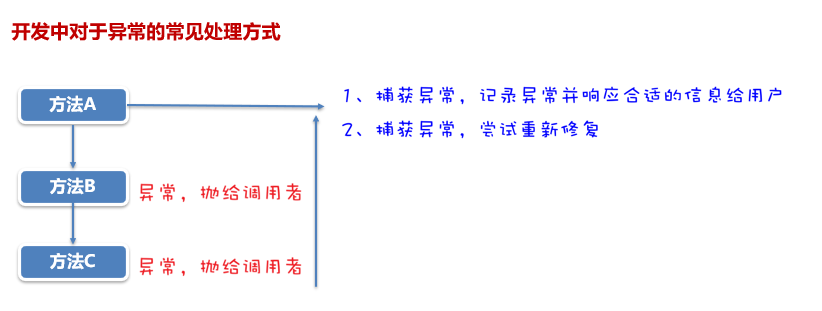
异常的处理
最外层集中捕获处理

day06-集合进阶
集合是一种容器,用来装数据的,类似于数组,但集合的大小可变,开发中也非常常用
分类
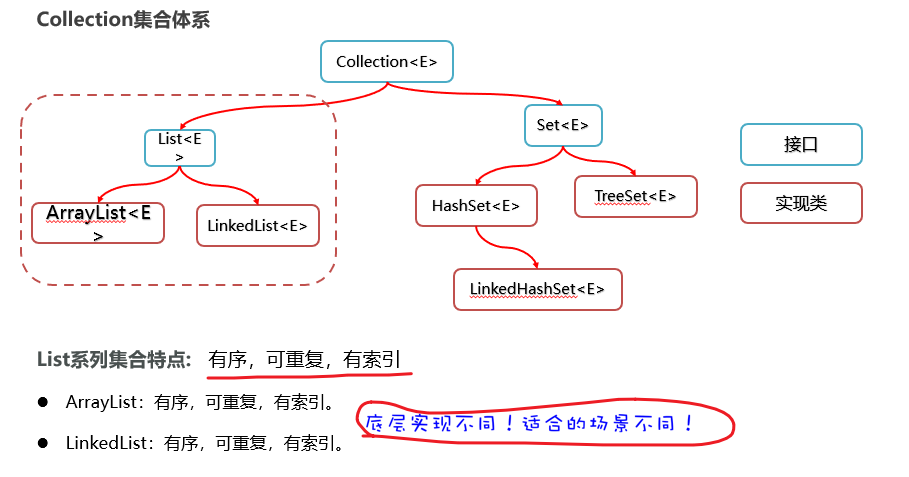
分为:单列集合和双列集合

单列Collection集合体系
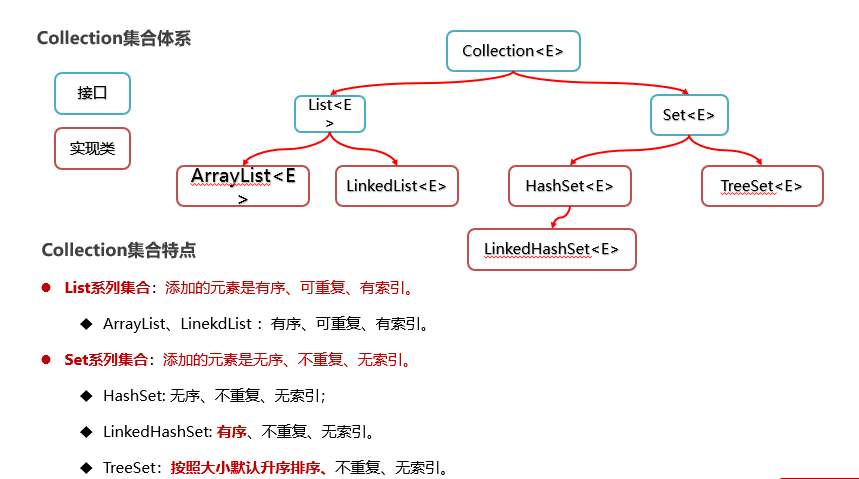
**有序:**先加的在前面,后加的在后面
**可重复:**元素可以重复
**有索引:**可以根据索引取数据
Collection的常用方法(list和set的通用功能)

Collection的遍历方式(list和set的通用功能)
总览:共三种方法
public static void main(String[] args) {
Collection<String> list = new ArrayList<>();
//1.迭代器
Iterator<String> iterator = list.iterator();
//2.增强for循环
for (String s : list) {
}
//3.forEach方法
list.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
迭代器
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("aa");
list.add("bb");
list.add("cc");
list.add("dd");
System.out.println(list);
// [aa, bb, cc, dd]
// it初始在0位置,取完再后移
//list.iterator():得到这个集合的迭代器对象:每次调用都会new一个迭代器对象。
//因为Iterator是接口不能创建对象,所以使用成员内部类(private class Itr implements Iterator<E> )实现Iterator接口。成员内部类可以访问外部类对象的成员变量
Iterator<String> it = list.iterator();
// System.out.println(it.next());//
// System.out.println(it.next());
// System.out.println(it.next());
// System.out.println(it.next());
//使用循环改进
while(it.hasNext()){
System.out.println(it.next());
}
}

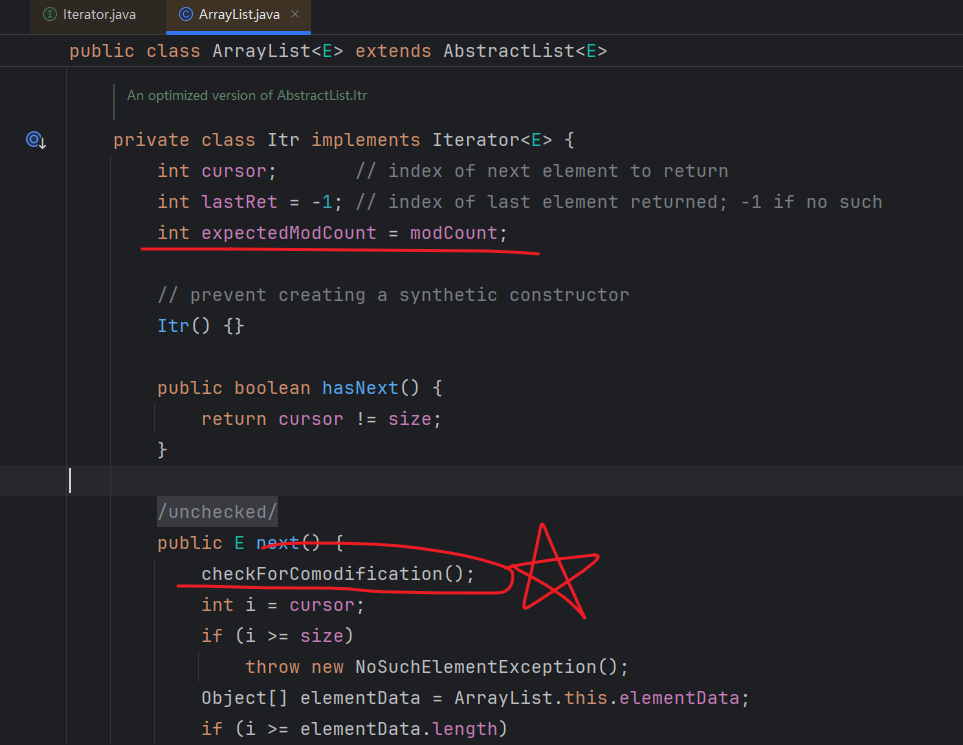
ArrayList中的Iterator的实现类:cursor(游标)变量初始化为0,调用next()方法时候,是先取cursor位置的数据,再cursor+1指向下一个数据。
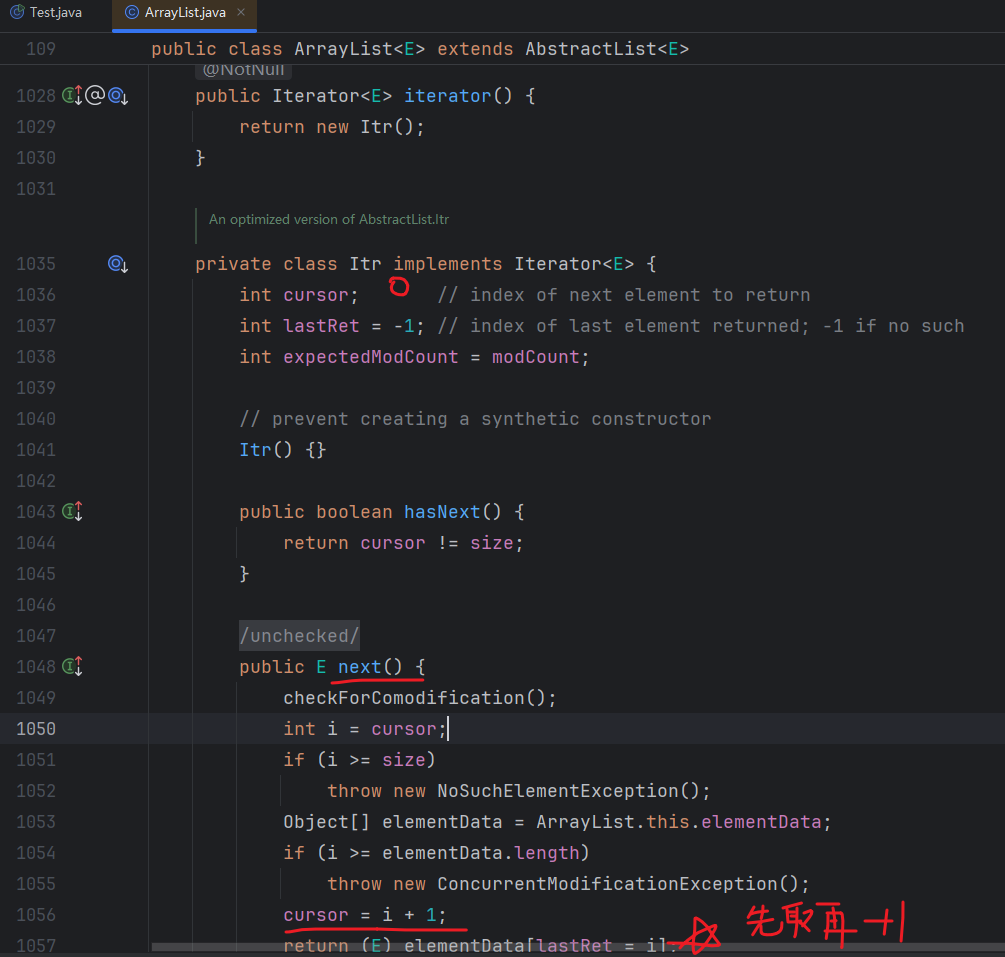
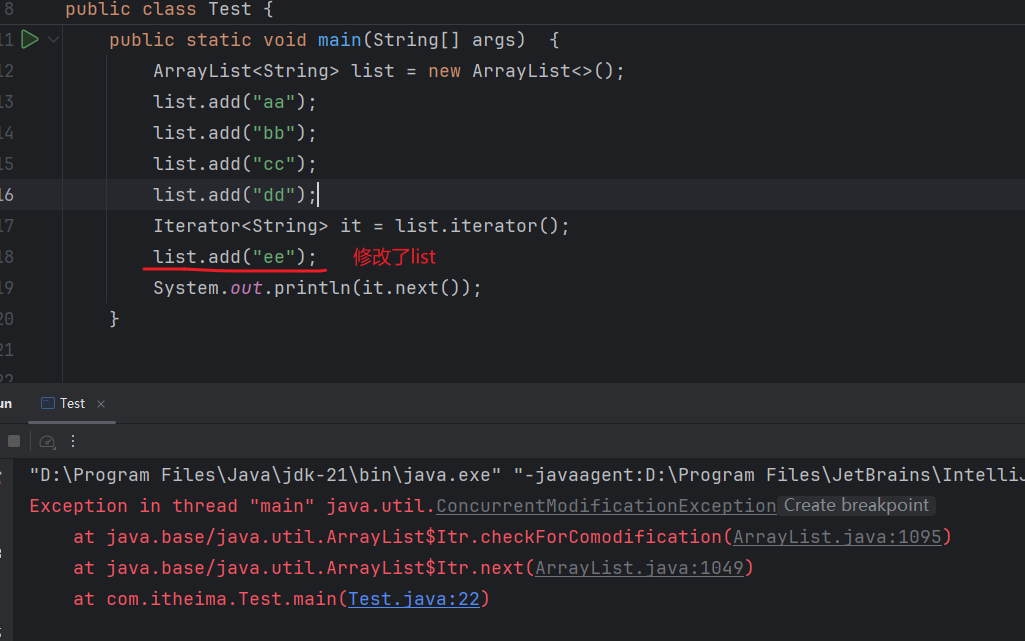
如果在遍历list时修改原list需要注意:
如果在得到 Iterator 后,又使用 list.add("ee") 或者list.remove(xxx)等方法修改了列表结构。之后,使用迭代器遍历,就会触发 ConcurrentModificationException,因为 Iterator 是“快速失败(fail-fast)”的,它检测到列表在迭代过程中被修改,就会抛出异常以避免不一致的状态。
增强for循环
增强for可以用来遍历集合或者数组(Java 的数组之所以可以使用增强 for 循环来遍历,是因为 Java 语言规范中专门为_数组和实现了 Iterable 接口_的对象,内置了增强 for 的支持)。
增强for遍历集合,本质就是迭代器遍历集合的简化写法
注意:修改增强for中的变量值不会影响到集合中的元素

public static void main(String[] args) {
Collection<String> list = new ArrayList<>();
list.add("aa");
list.add("bb");
list.add("cc");
list.add("dd");
System.out.println(list);
for (String s : list) {
System.out.println(s);
}
}

Lambda表达式遍历集合(forEach方法)
基于增强for循环实现,同时可以用Lambda表达式简化代码
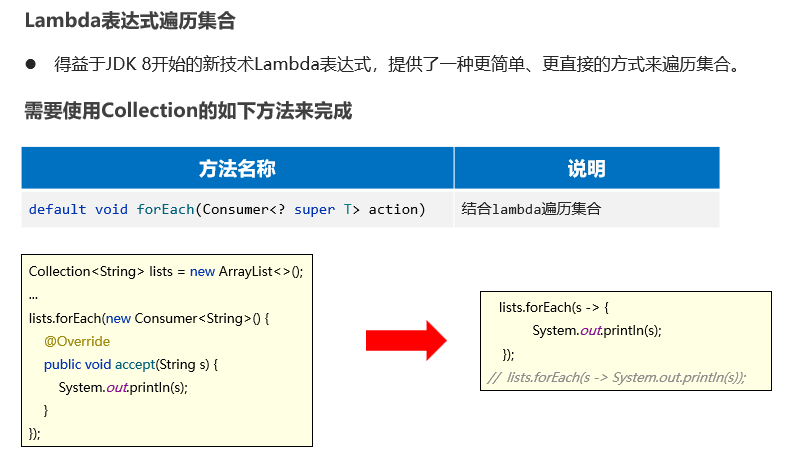
public static void main(String[] args) {
Collection<String> list = new ArrayList<>();
list.add("aa");
list.add("bb");
list.add("cc");
list.add("dd");
System.out.println(list);
list.forEach(new Consumer<String>() {
@Override
public void accept(String s) {//s:遍历到的元素
System.out.println(s);
}
});
}
Collection类的forEach方法源码如下(ArrayList对此方法进行了重写):
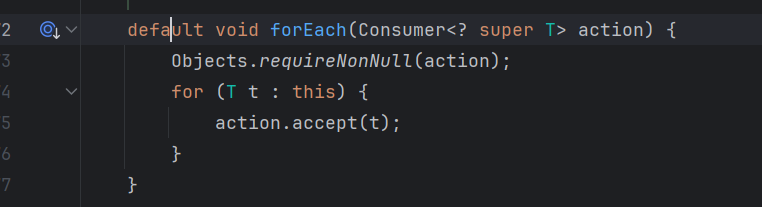
典型对象回调思想
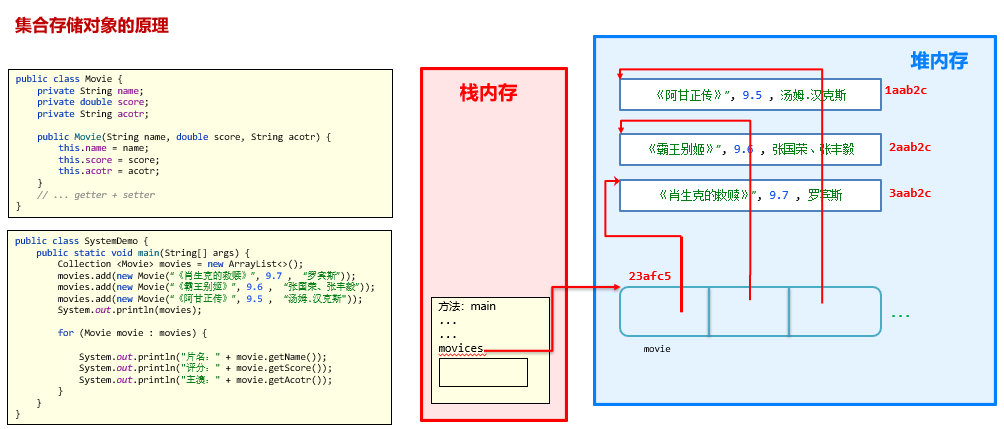
集合存储对象的原理
存储的是对象的地址
集合的并发修改异常(遍历删除时)
迭代器遍历
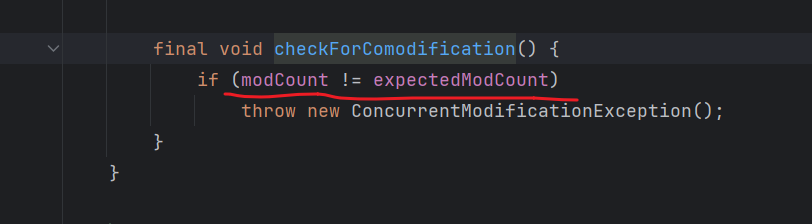
迭代器遍历中,每一次调用next取数据的时候,都会检查都没有修改。
如果使用迭代器遍历,并用集合删除数据,会出现并发修改异常ConcurrentModificationException
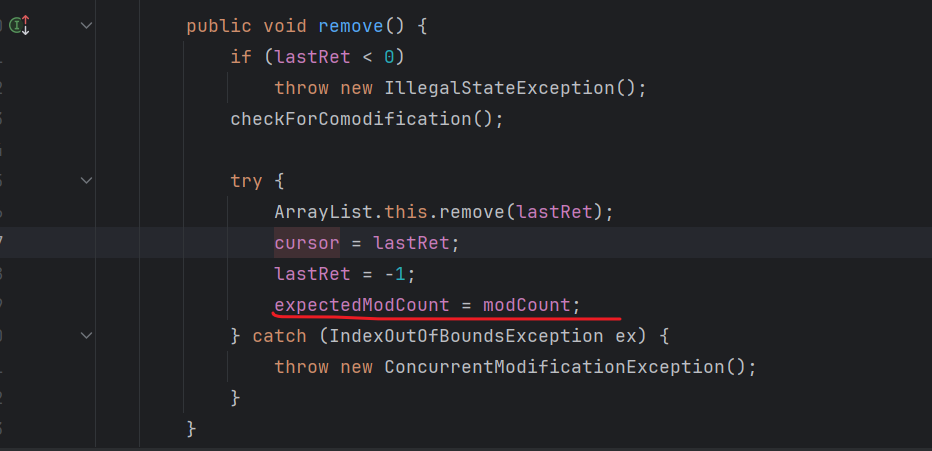
解决方法:必须调用迭代器自己的删除方法**.remove()**,才不会出现报错
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("aa");
list.add("bb");
list.add("cc");
list.add("dd");
Iterator<String> it = list.iterator();
while (it.hasNext()) {
String name = it.next();
if(name.contains("c")){
// list.remove(name);//运行时报错
it.remove();//必须调用迭代器自己的删除方法**.remove()**
}
}
System.out.println(list);
}
.remove()
增强for循环
增强for循环在遍历时删除也会报错,因为增强for循环本质是迭代器,且无法解决(因为拿不到迭代器)
Lambda表达式遍历集合
也会报错。因为也是基于增强for的方式
遍历并删除的总结
- 如果遍历并删除collection集合,要用迭代器。
- 如果是Arraylist等带索引的集合,也可以用for循环遍历索引,每次删除退一步,或者从后倒着遍历并删除!
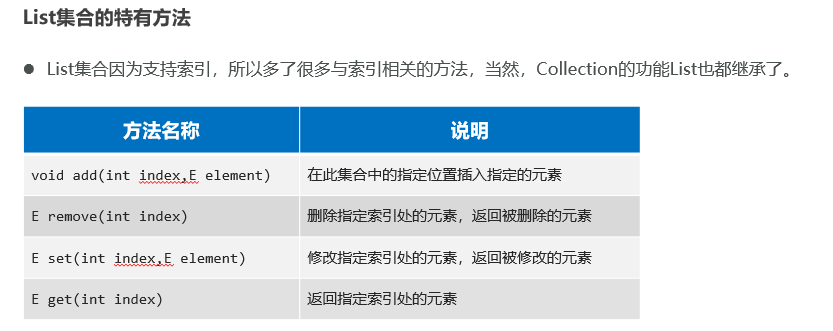
List集合(特有功能)
List集合因为支持索引,所以多了很多与索引相关的方法,当然,Collection的功能List也都继承了。
遍历方式:四种

除了collection集合都有的三种,还有for循环索引遍历
for (int i = 0; i < list.size(); i++) {
//xxxxxxxxxx
}
ArrayList和LinekdList的区别:

ArrayList
底层原理
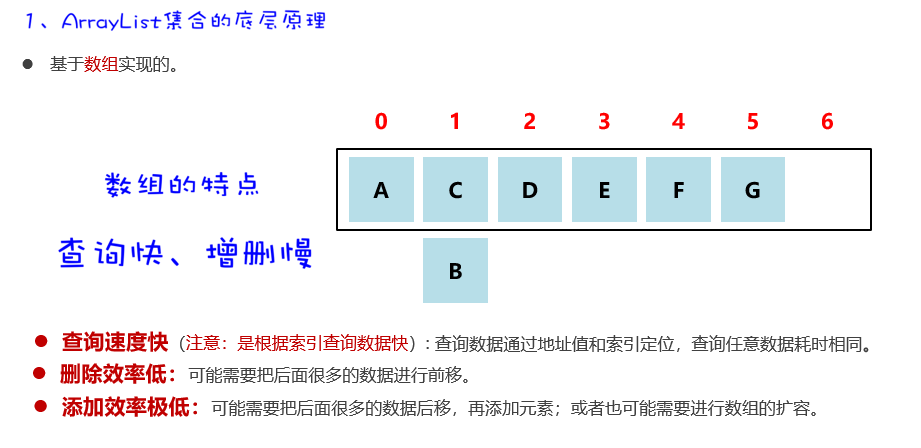
- 基于数组实现
- 根据索引查询数据快:可以通过地址和索引直接定位元素,查询任意索引处的数据耗时相等
- 增删慢
使用流程:
- 利用无参构造器创建的集合,会在底层创建一个默认长度为0的数组
- 添加第一个元素时,底层会创建一个新的长度为10的数组
- size变量记录当前元素的个数和下次存入的位置
- 存满时,会扩容1.5倍
- 如果一次添加多个元素(使用
.addAll()方法),1.5倍还放不下,则创建数组的长度以实际为准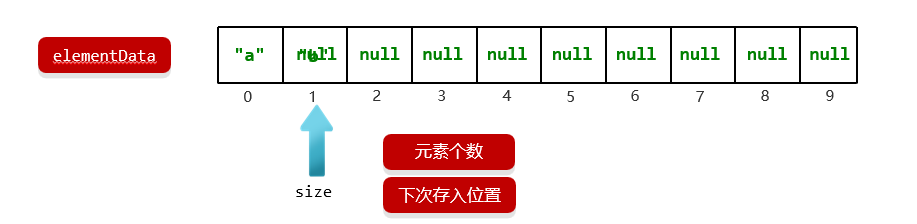

应用场景:

源码
modCount:记录修改次数

elementData:实际存储元素的数组

起始大小size:0

如果用无参构造器创建集合:初始是空数组
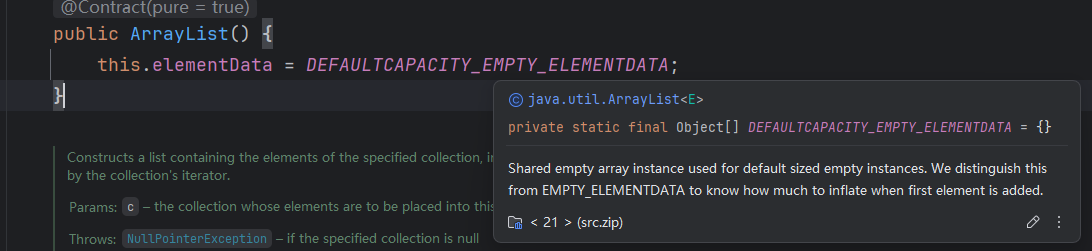
第一次添加数据会扩容:添加时修改次数modCount+1。
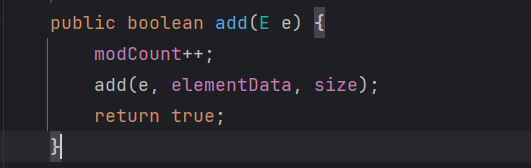
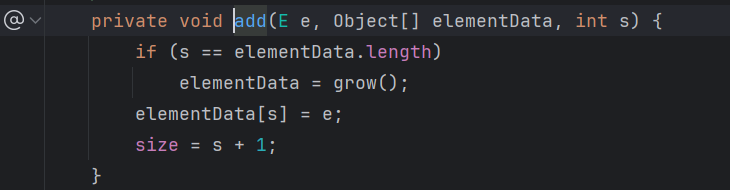
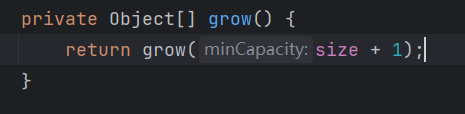
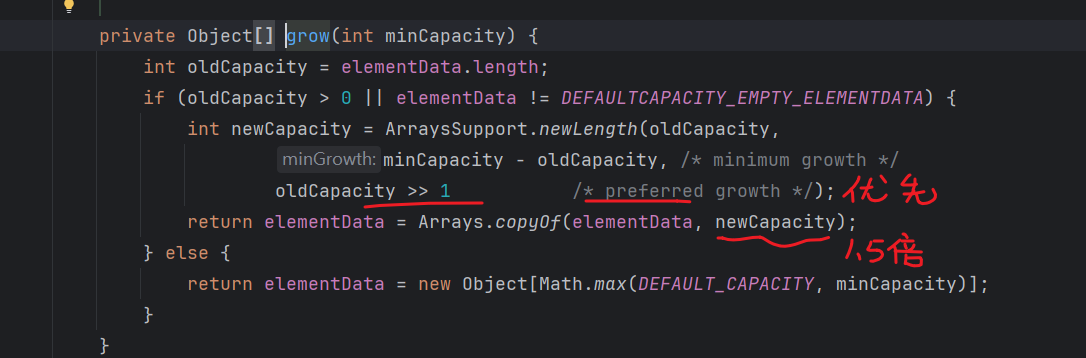
默认容量:10

remove方法
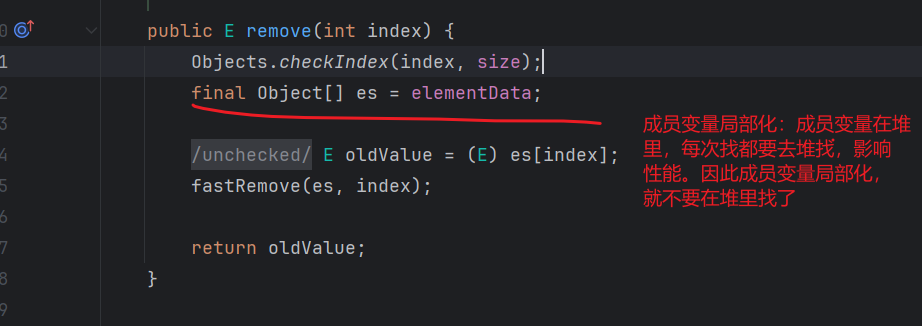
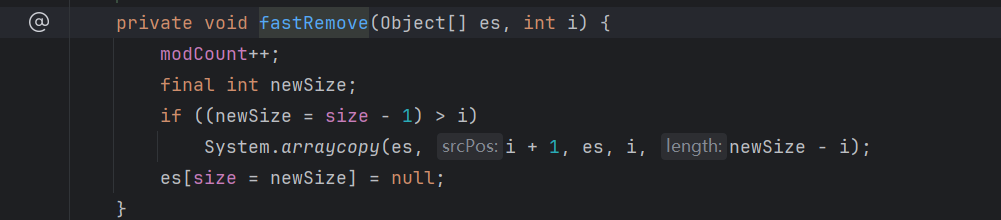
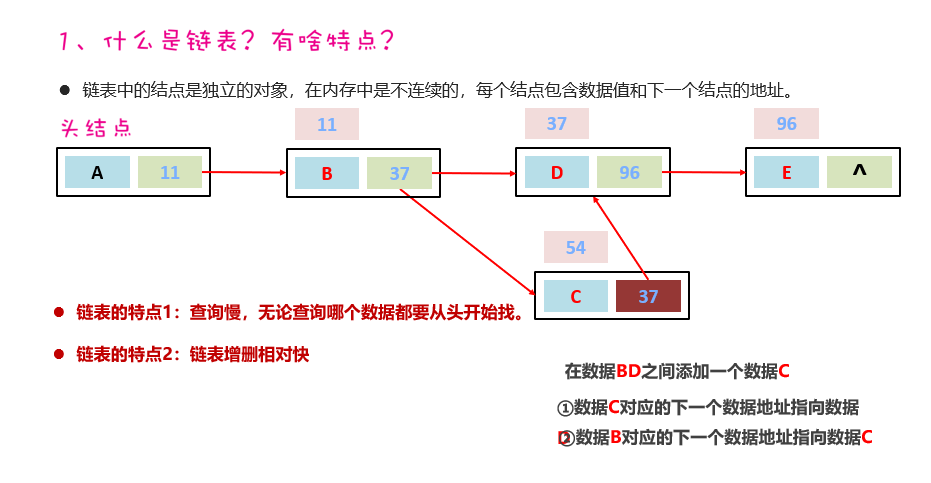
LinekdList
底层基于双链表实现
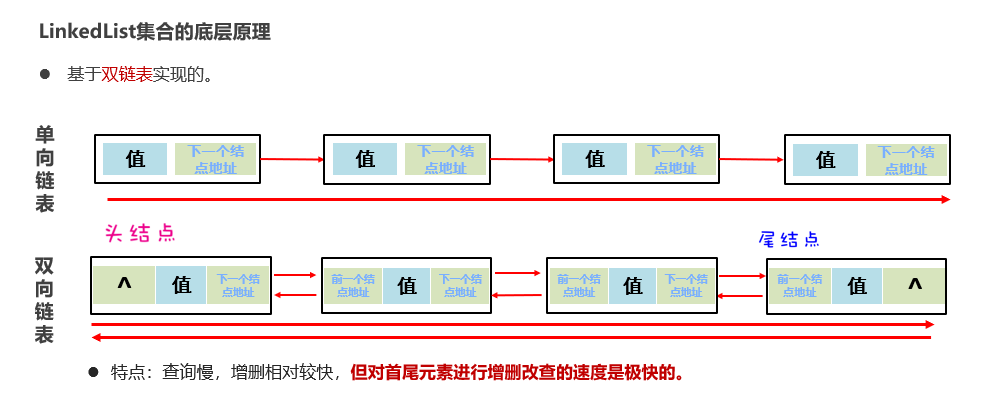

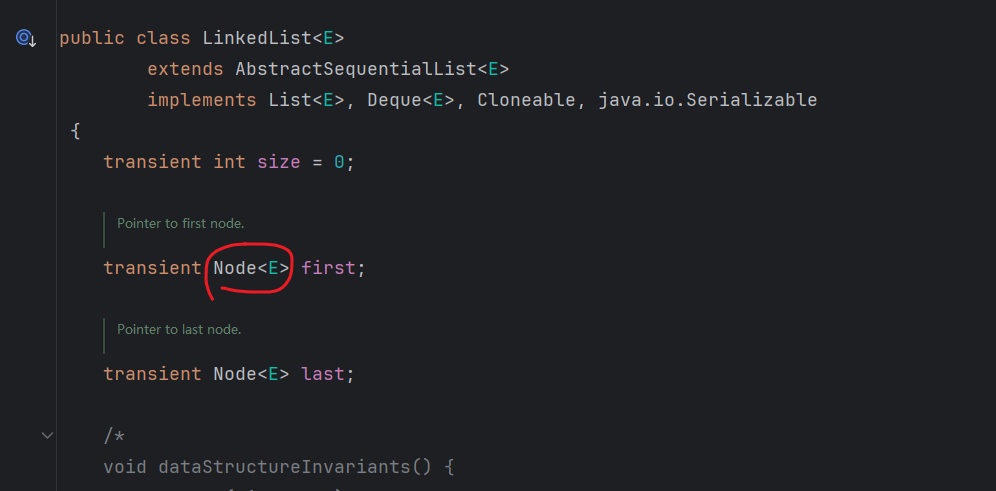
源码:
LinkedList的应用场景之一:可以用来设计队列
LinkedList<Integer> queue = new LinkedList<>();
queue.addLast(1);
queue.addLast(2);
queue.addLast(3);
queue.addLast(4);
System.out.println(queue);
System.out.println(queue.removeFirst());
System.out.println(queue.removeFirst());
LinkedList的应用场景之一:可以用来设计栈
LinkedList<Integer> stack = new LinkedList<>();
stack.addFirst(1);
stack.addFirst(2);
stack.addFirst(3);
stack.addFirst(4);
System.out.println(stack);
System.out.println(stack.removeFirst());
System.out.println(stack.removeFirst());
也可以用pop和push方法:
手写链表
package com.itheima;
import java.util.ArrayList;
import java.util.StringJoiner;
public class MyLinkedList<E> {
private int size = 0;
Node<E> first;//头指针
public boolean add(E e){
//第一个节点
//或者是后面的节点
Node<E> newNode = new Node<>(e,null);
//判断这个节点是否是第一个节点
if(first == null){
first = newNode;
}
else{
//把这个节点加入到当前最后一个节点的下一个位置
//找到最后一个节点对象
Node<E> temp = first;
while(temp.next !=null){
temp = temp.next;
}
temp.next = newNode;
}
size++;
return true;
}
@Override
public String toString() {
StringJoiner sj = new StringJoiner(",","[","]");
Node<E> temp = first;
while(temp!=null){
sj.add(temp.item.toString());
temp = temp.next;
}
return sj.toString();
}
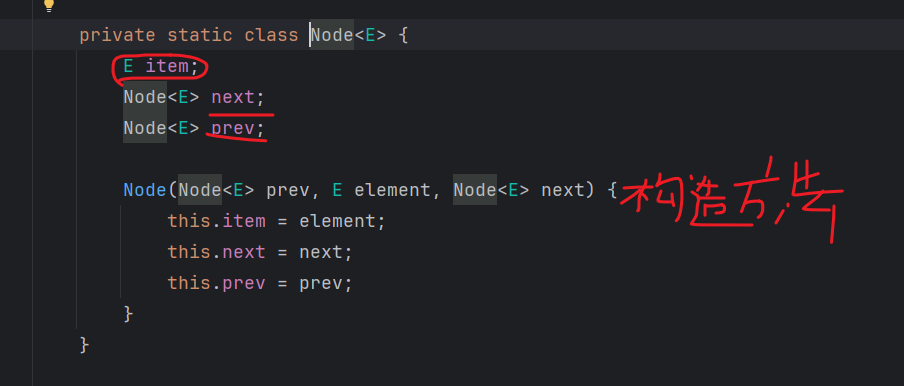
public static class Node<E>{
E item;
Node<E> next;//下一个节点的地址
public Node(E item, Node<E> next) {
this.item = item;
this.next = next;
}
}
}
、、、、、、、、、、、、、、、、、、、、、、、、、、、、、
public class Test {
public static void main(String[] args) {
MyLinkedList<String> list = new MyLinkedList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
System.out.println(list);//[aaa,bbb,ccc]
}
}
Set集合
Set系列集合的底层就是基于Map实现的,只是Set集合中的元素只要key数据,不要value数据而已。
Set基本上没有特有功能,都是Collection的提供的功能
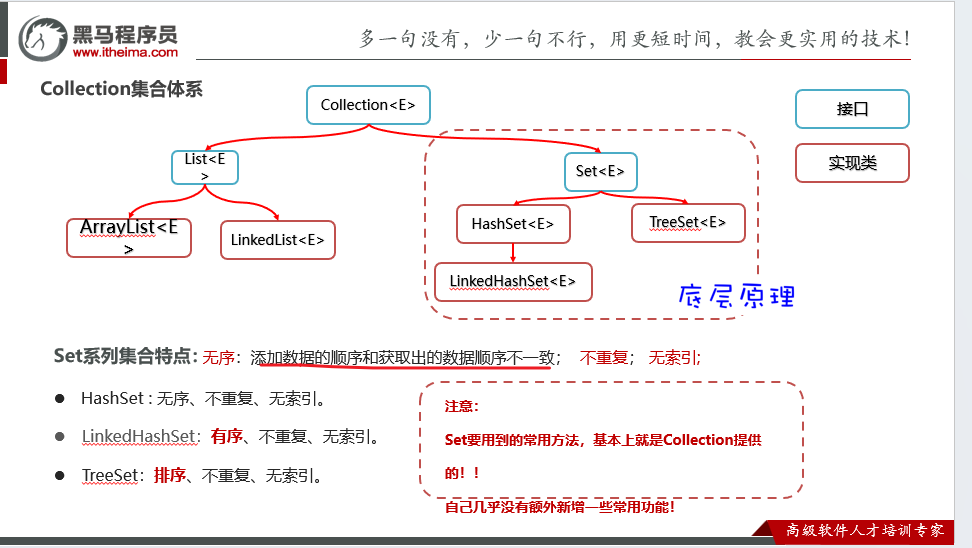
LinkedHashSet 有序:插入顺序和遍历顺序相同
HashSet


哈希值:就是随机数。可以保证不同对象的随机数大概率不一样
底层原理

哈希表是一种增删改查数据性能都较好的结构。
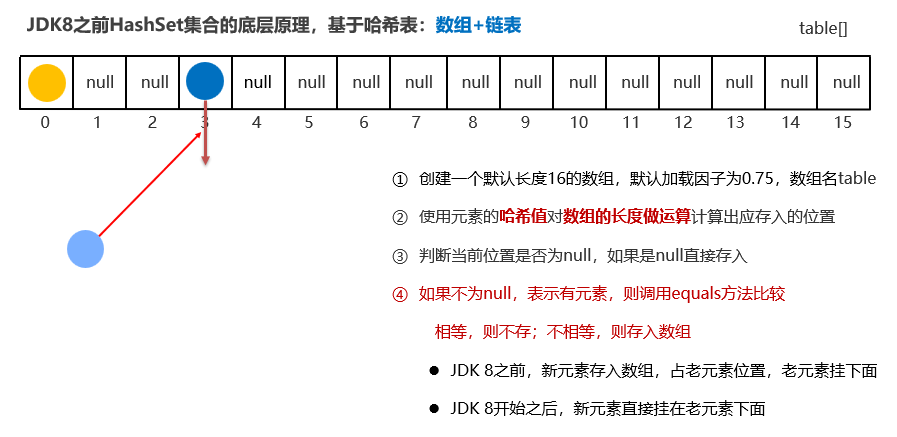
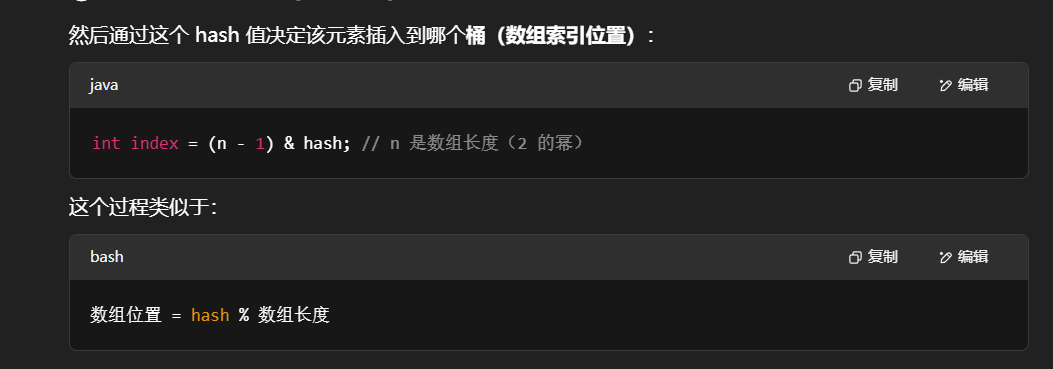
根据哈希值计算存入的位置(类似于取模):
加载因子:

如果数组存满到12个时,这时有些链可能较长了,就会扩容成两倍:即32,然后重新迁移数据。每次扩容原先的两倍。
JDK8开始,当链表长度超过8,且数组长度>=64时,自动将链表转成红黑树
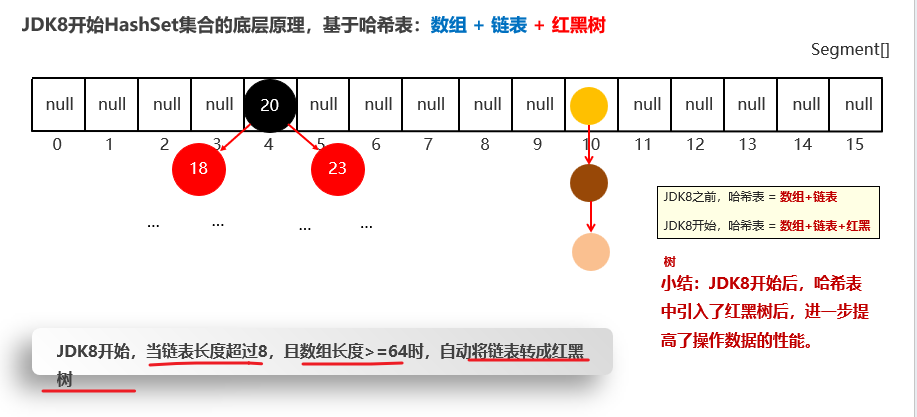
红黑树(Red-Black Tree)不是严格意义上的平衡二叉树(Strictly Balanced Binary Tree),它是一种**“近似平衡”**的二叉搜索树(BST)。
(根叶黑,不红红,黑路同)
深入理解HashSet集合去重复的机制
先拿待插入元素的hashcode计算插入的数组的位置,如果位置为空,就直接插入。如果该位置有其他元素,就比较哈希值。如果哈希值不相等,就不是重复元素,直接插入。如果哈希值相等(可能存在哈希碰撞),最后用equals比较是否真的相等:如果相等则不插入,不相等则插入。

如果希望Set集合认为2个内容一样的对象是重复的,
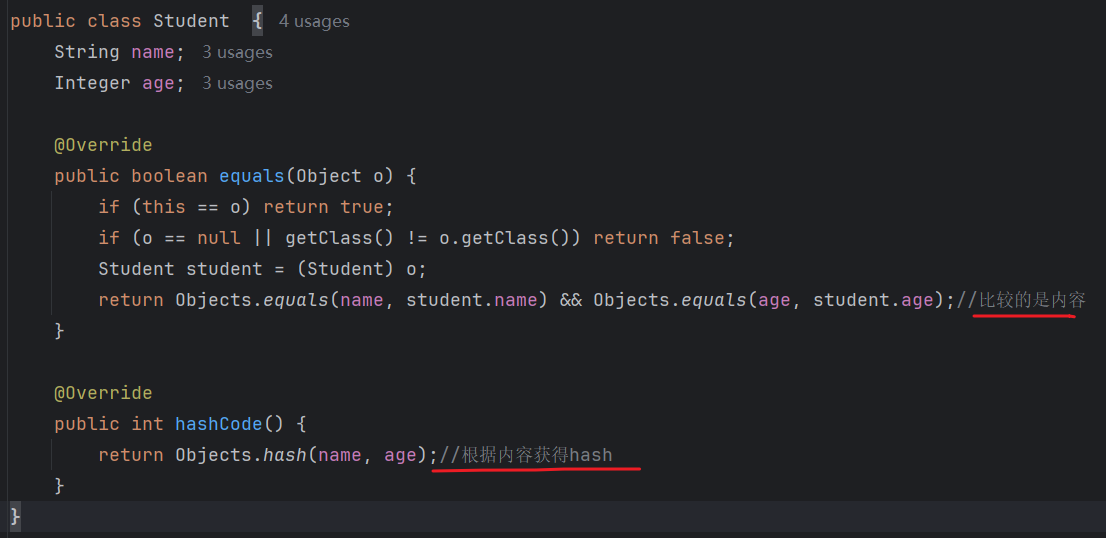
必须重写对象的hashCode()和equals()方法(同时重写,直接自动生成即可)

重写hashCode()和equals()方法的例子:
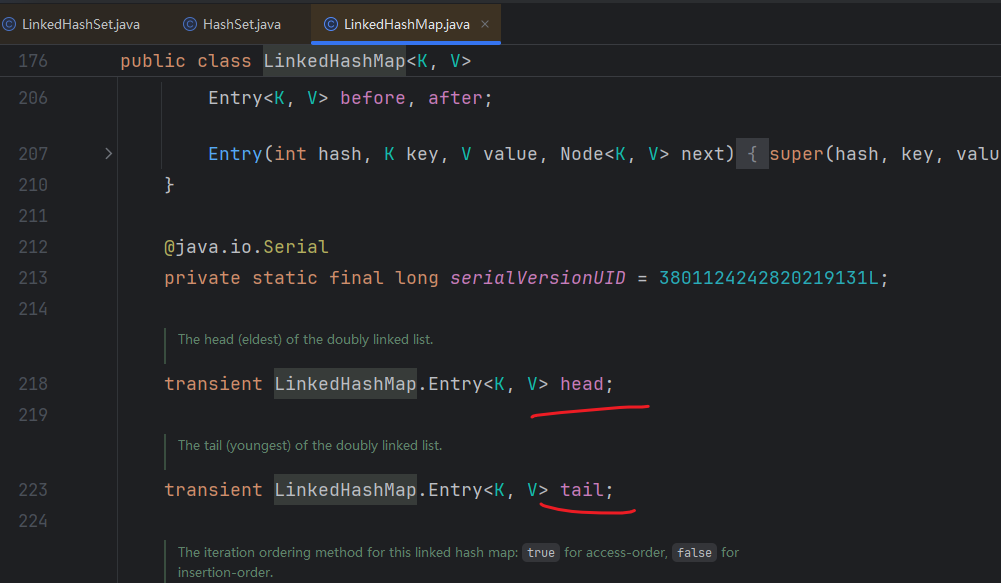
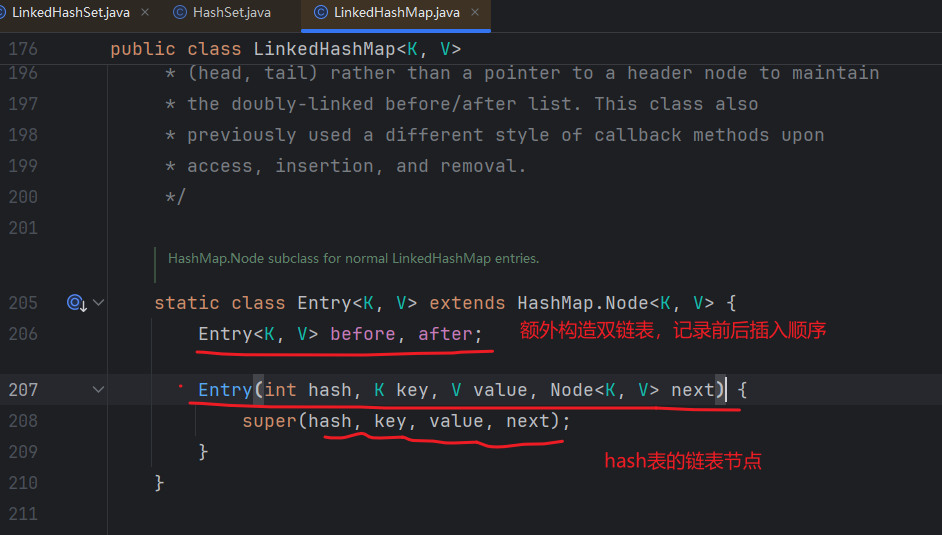
LinkedHashSet
有序(插入顺序就是遍历顺序),不重复,无索引

LinkedHashSet基于LinkedHashMap实现。有头指针和尾指针:
TreeSet
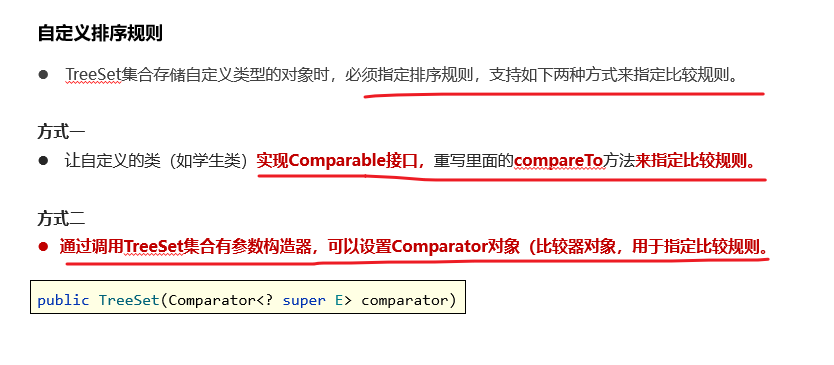
可排序:默认升序排序。底层基于红黑树实现

!!!!TreeSet集合存储自定义类型的对象时,必须指定排序规则,支持如下两种方式来指定比较规则:

List和Set集合每种集合的使用场景总结



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









