




 本文介绍了深度神经网络在CPU/GPU平台上的高效处理方法,如矩阵乘法优化、FFT/Strassen/Winograd转换,以及针对稀疏性和精度降低的算法设计。章节详细探讨了批处理大小、数据重用、算法与硬件协同设计,涵盖了深度卷积、灵活性和可扩展性,以及其他平台如DNN加速器和新兴技术。
本文介绍了深度神经网络在CPU/GPU平台上的高效处理方法,如矩阵乘法优化、FFT/Strassen/Winograd转换,以及针对稀疏性和精度降低的算法设计。章节详细探讨了批处理大小、数据重用、算法与硬件协同设计,涵盖了深度卷积、灵活性和可扩展性,以及其他平台如DNN加速器和新兴技术。
阅读总结
深度神经网络的高效处理(硬件)《Efficient Processing of Deep Neural Networks》读书笔记
原书:《Efficient Processing of Deep Neural Networks》Vivienne Sze, Yu-Hsin Chen, Tien-Ju Yang, Joel S. Emer(Morgan&Claypool Publishers - Synthesis Lectures On Computer Architecture)出版时间:Jun 2020
作者 MIT Vivienne Sze.
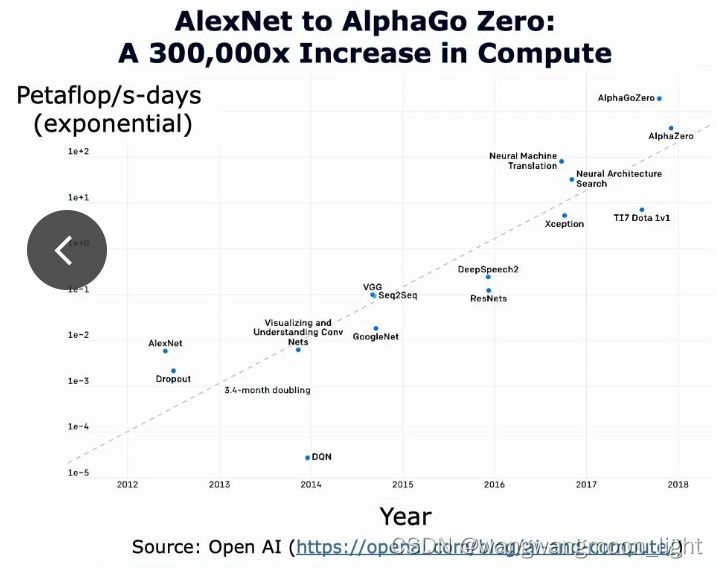

Batch Size
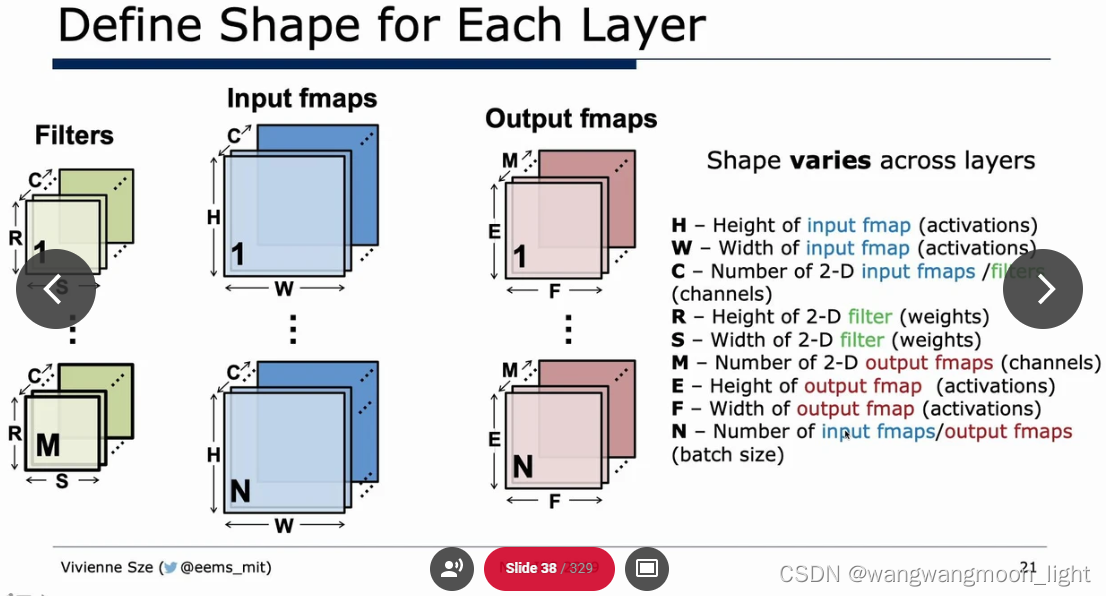
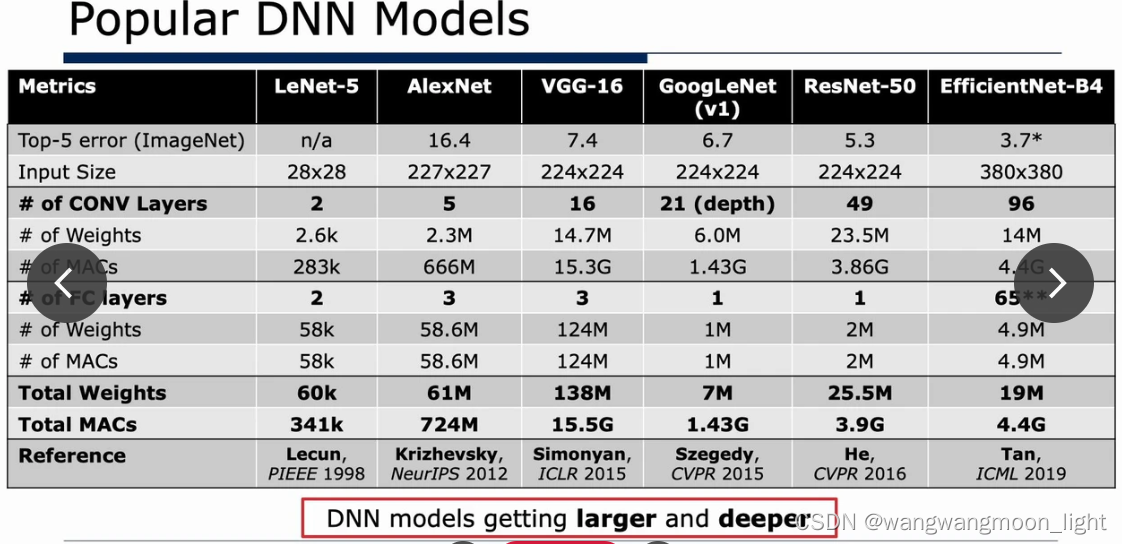

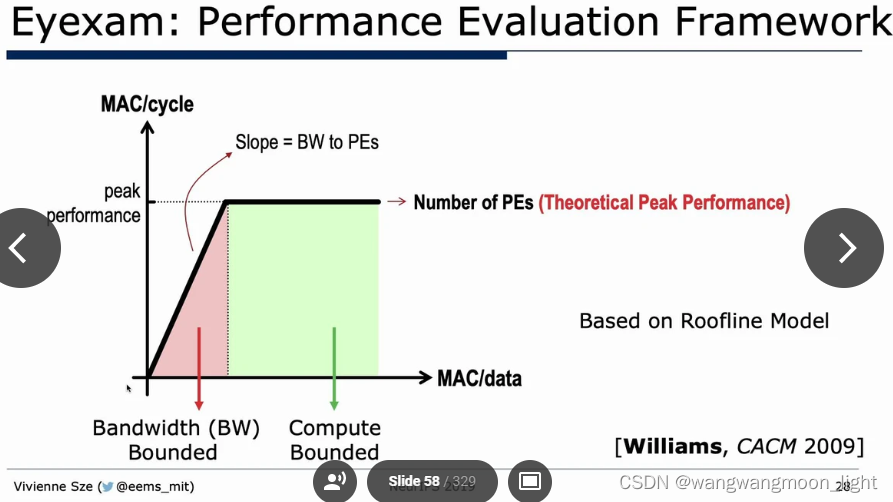
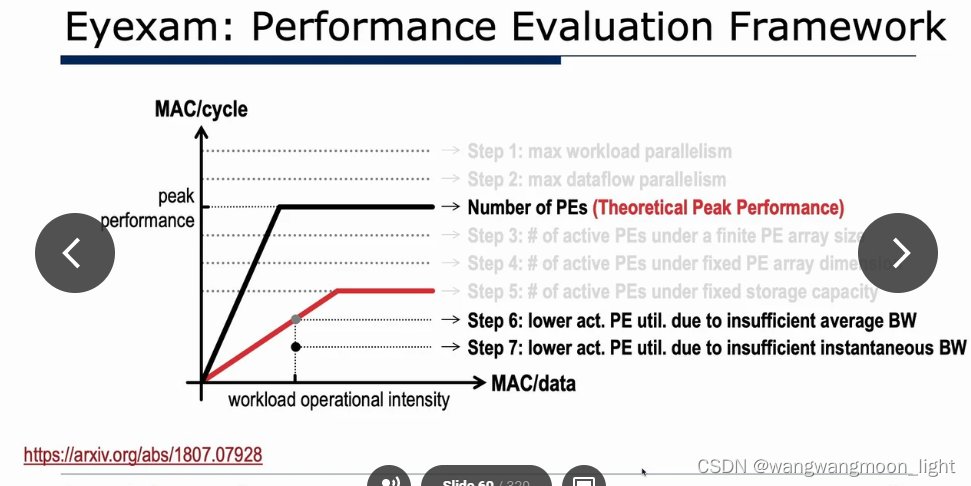
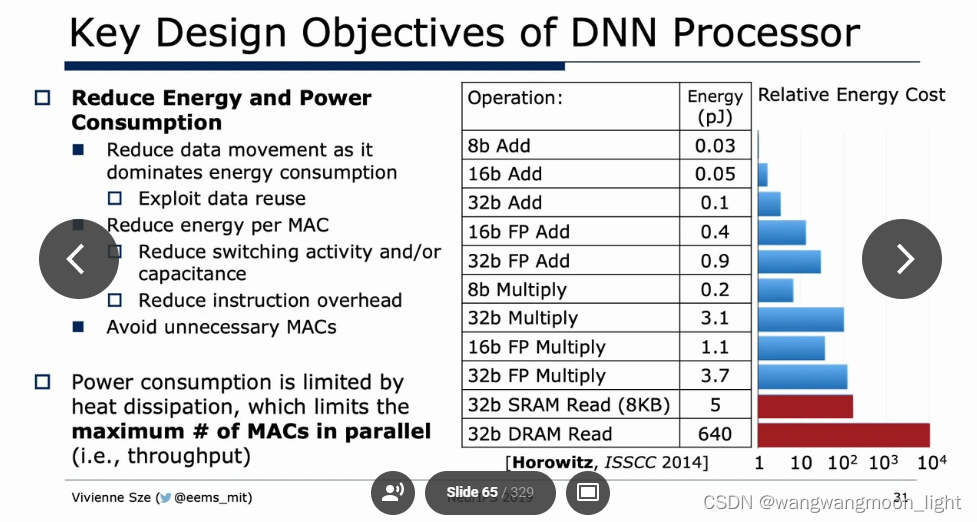




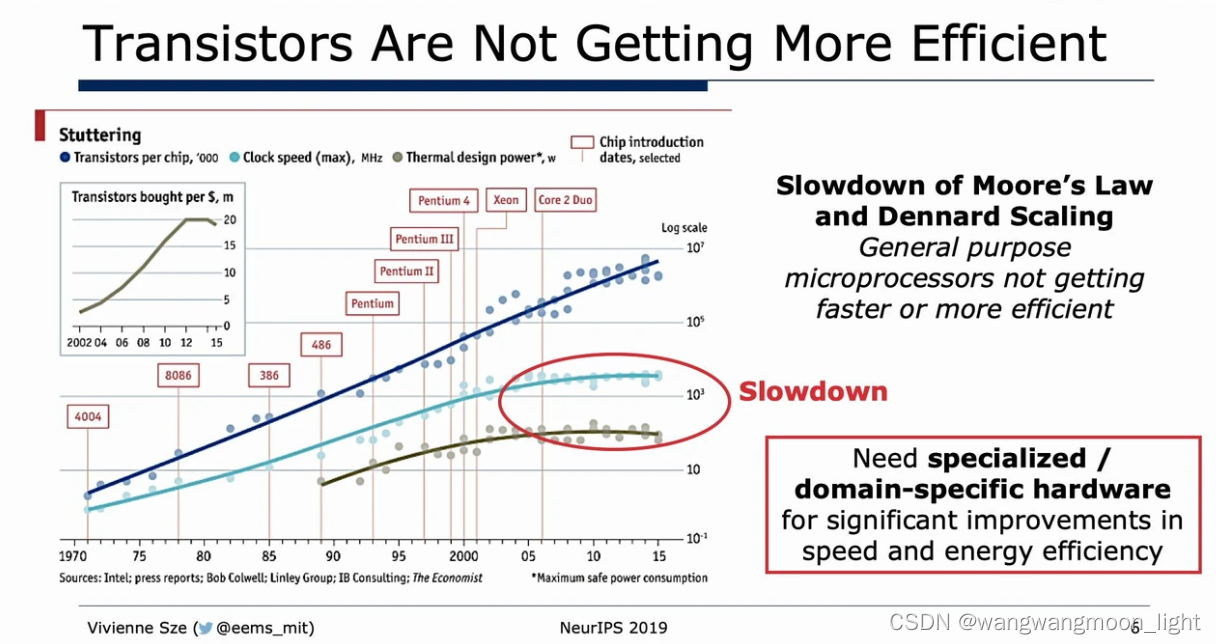
一、CPU && GPU Platform

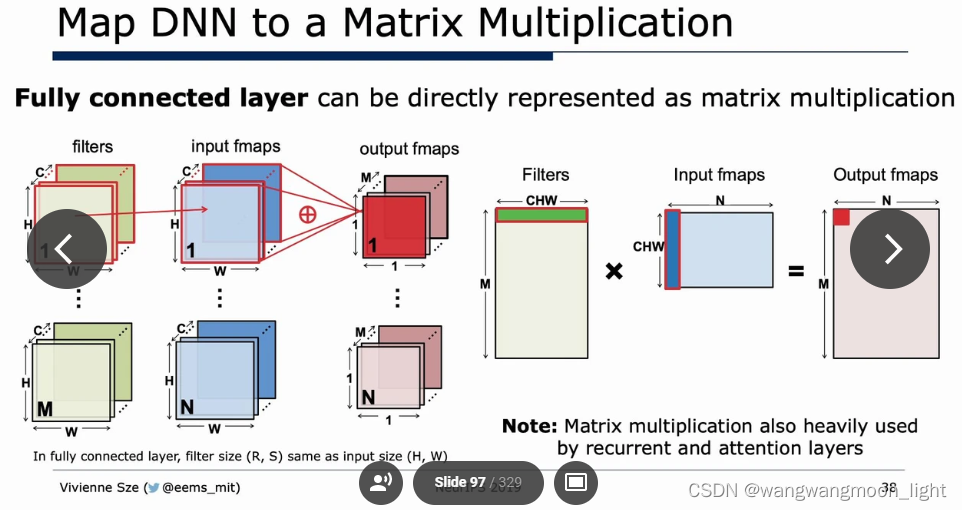
全连接层可以直接转为矩阵乘:
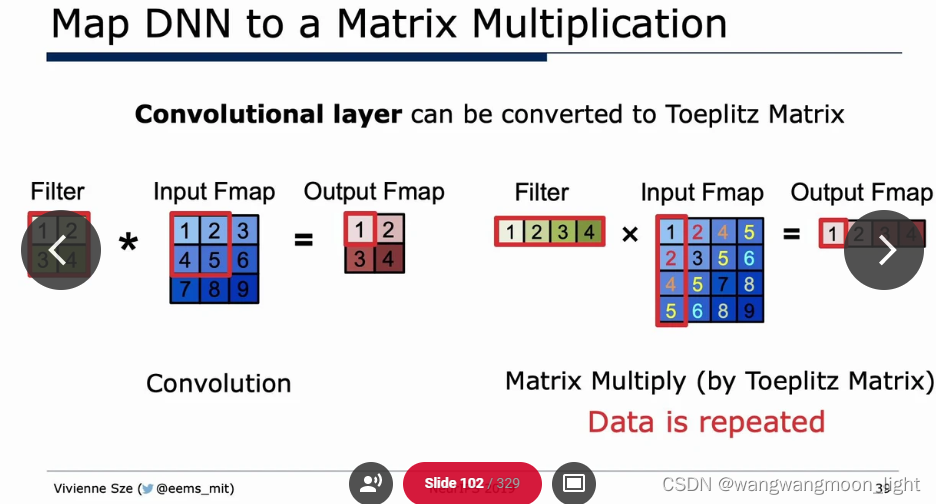

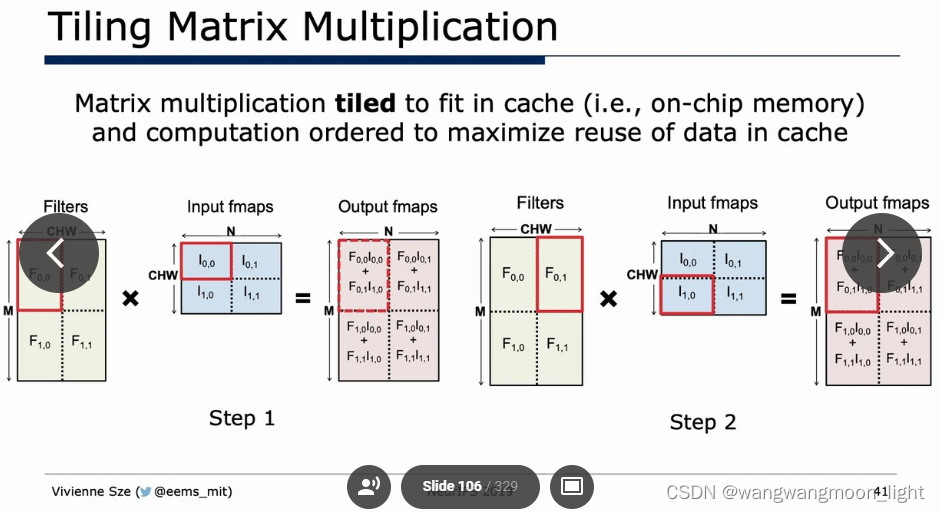
高斯算法:

FFT/Strassen/Winograd:



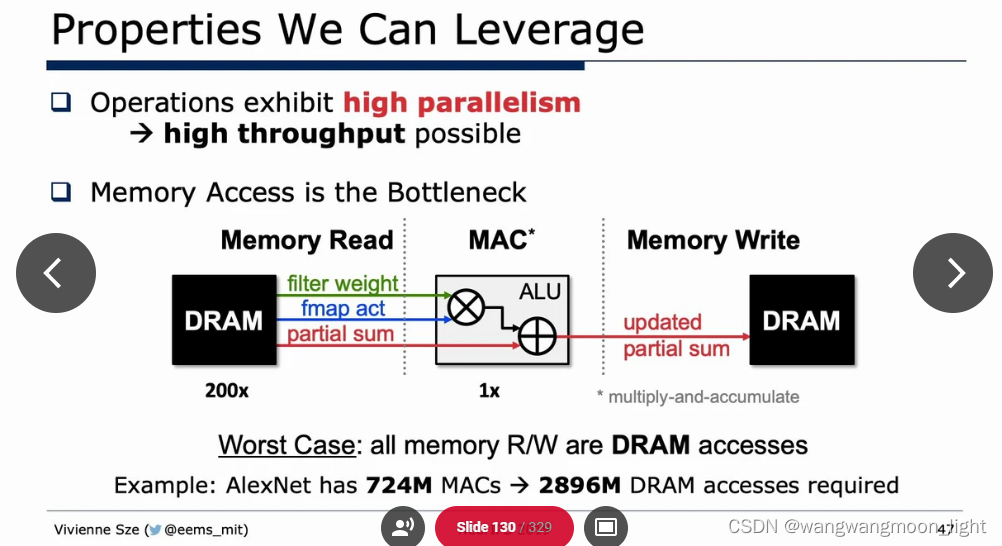
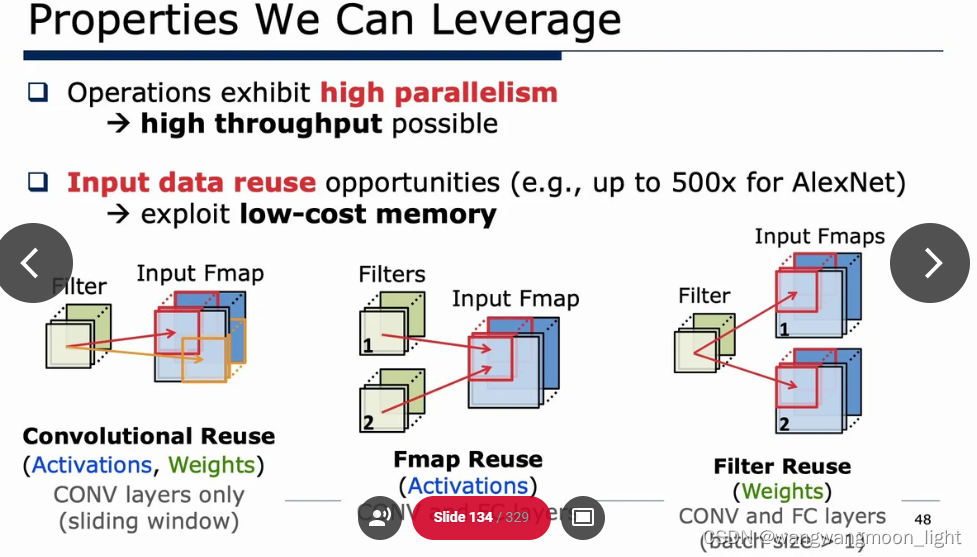
Properties We Can Leverage:
四份数据需要 RW, 所以下述倍数为4.
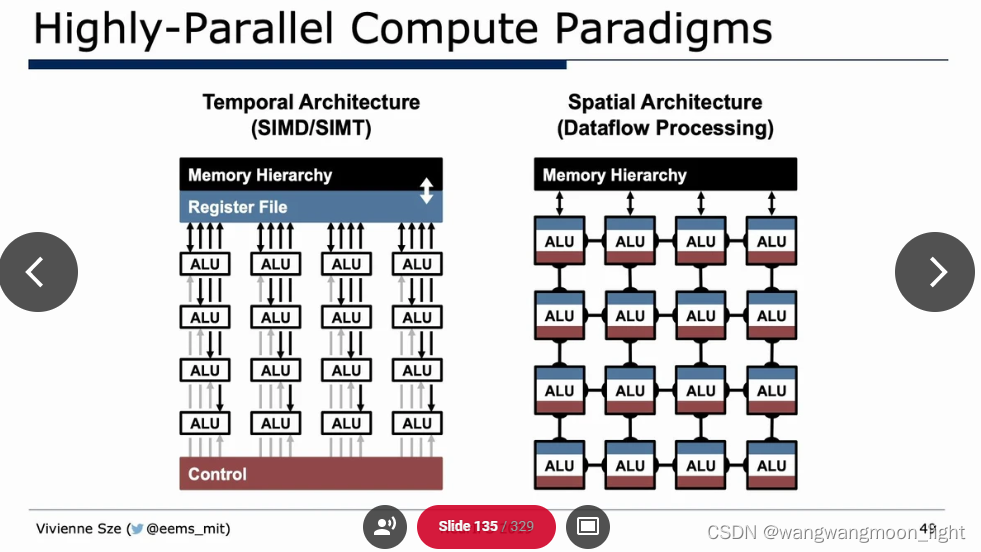
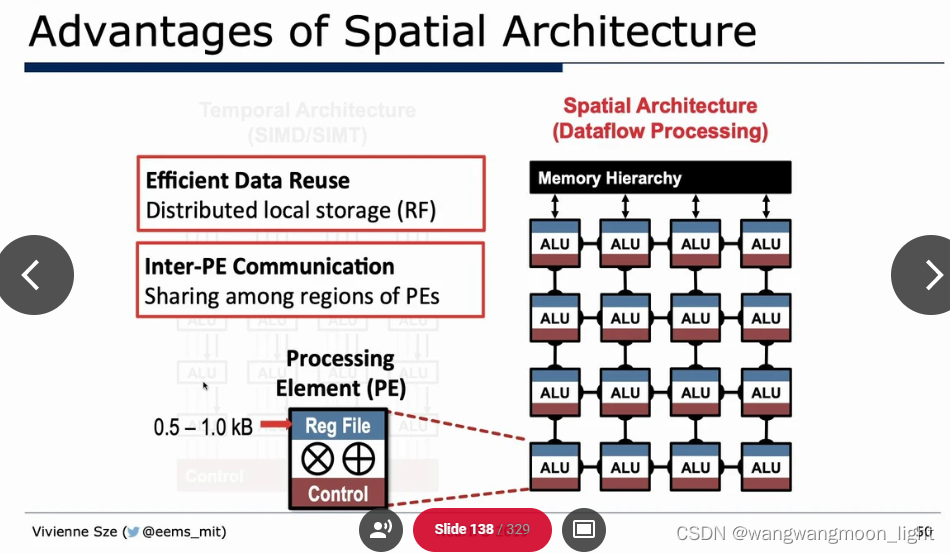
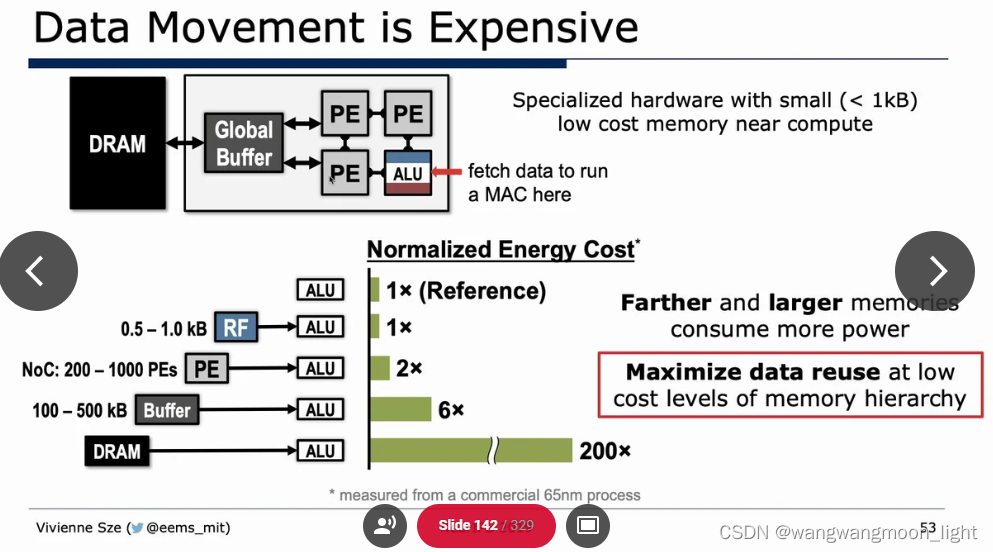

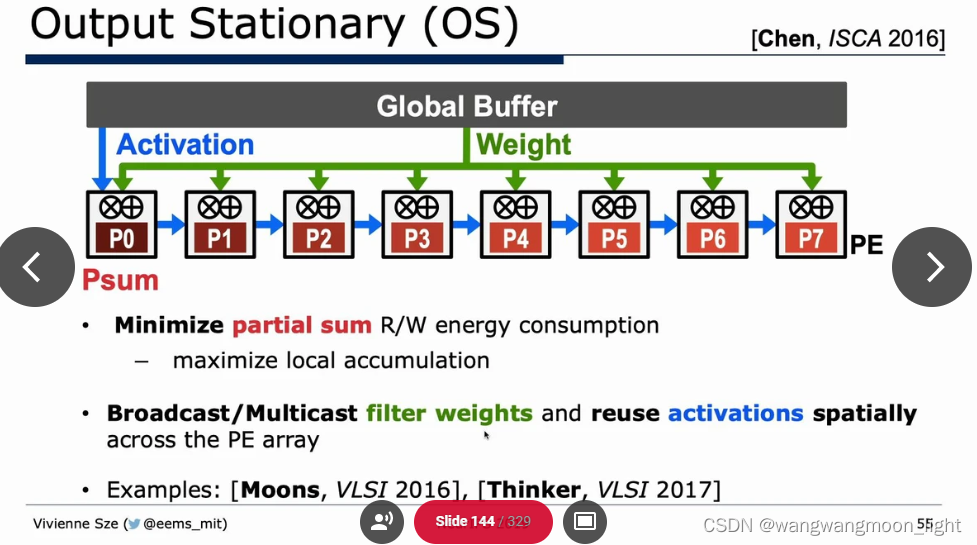
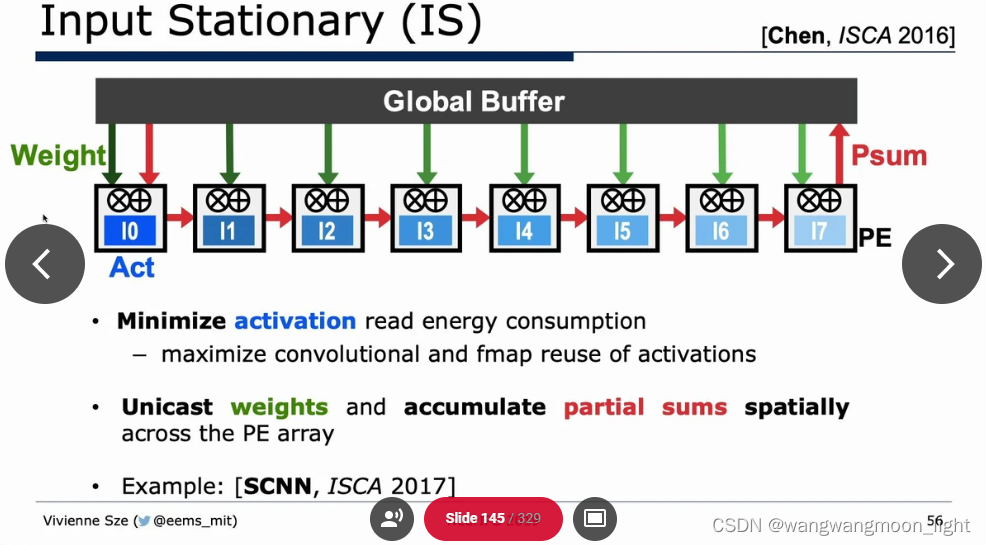
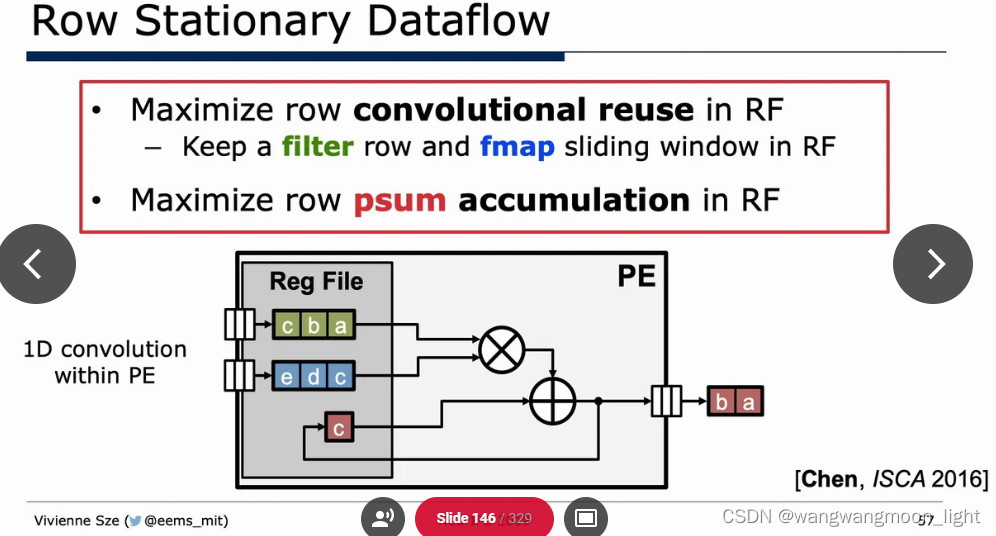
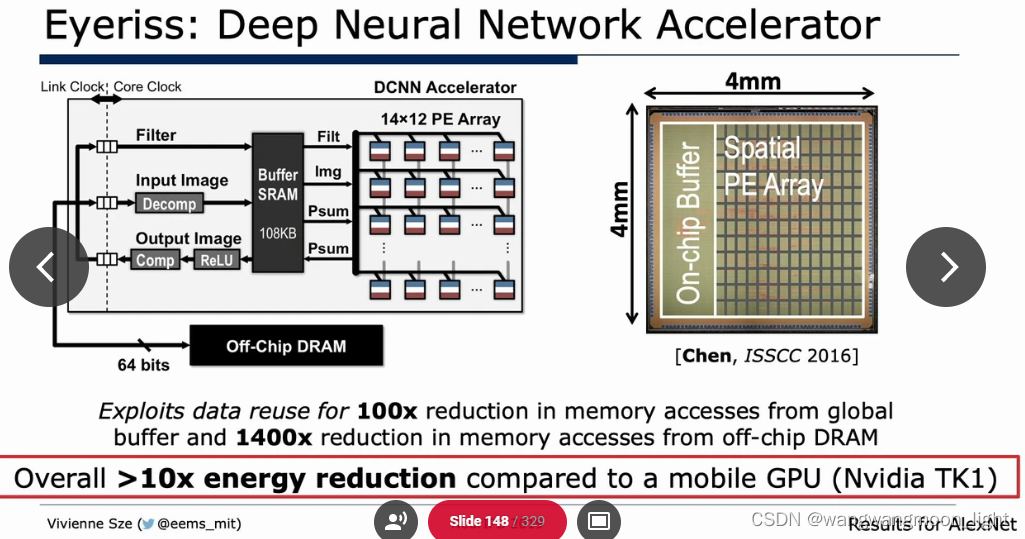
Algorithm & Hardware Co-Design:

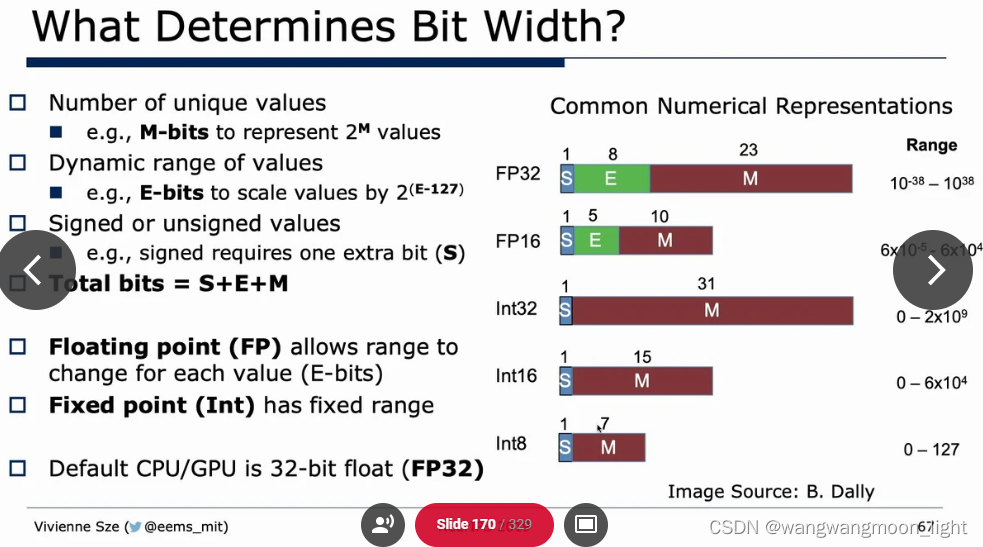
Reduce Precision:
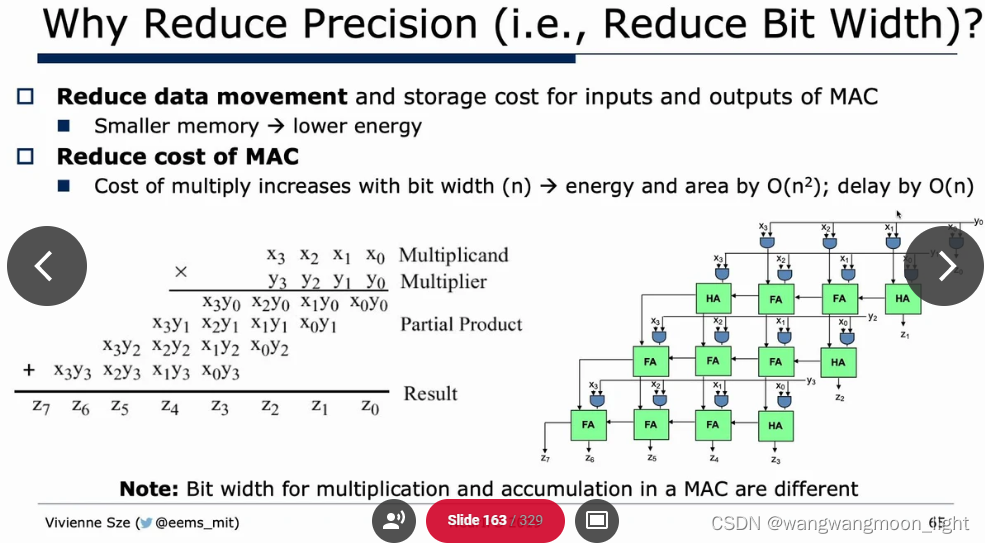




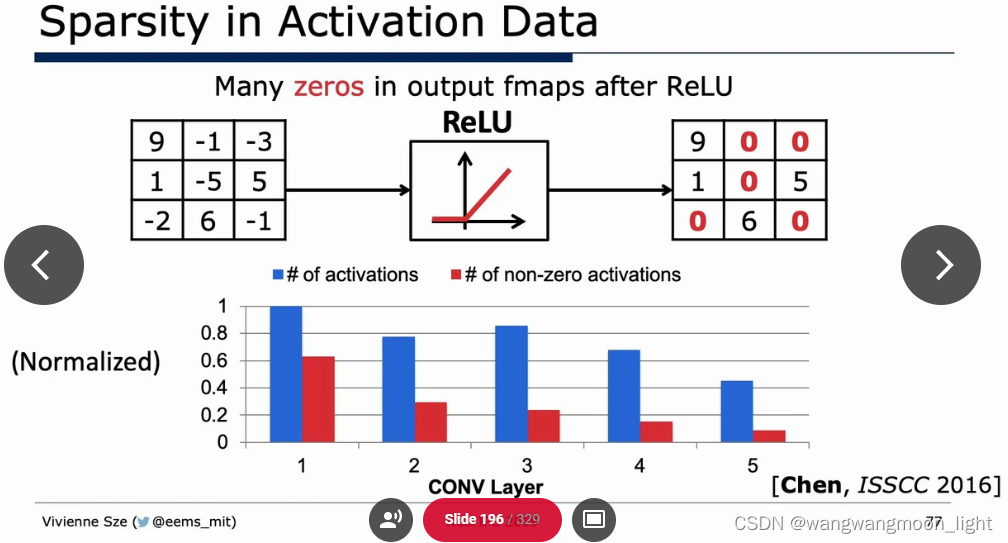
Sparsity:

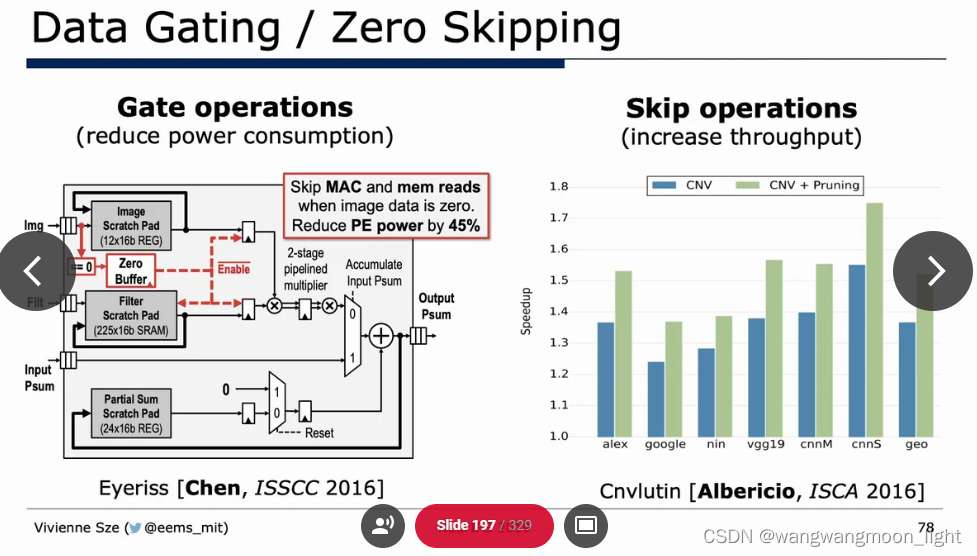
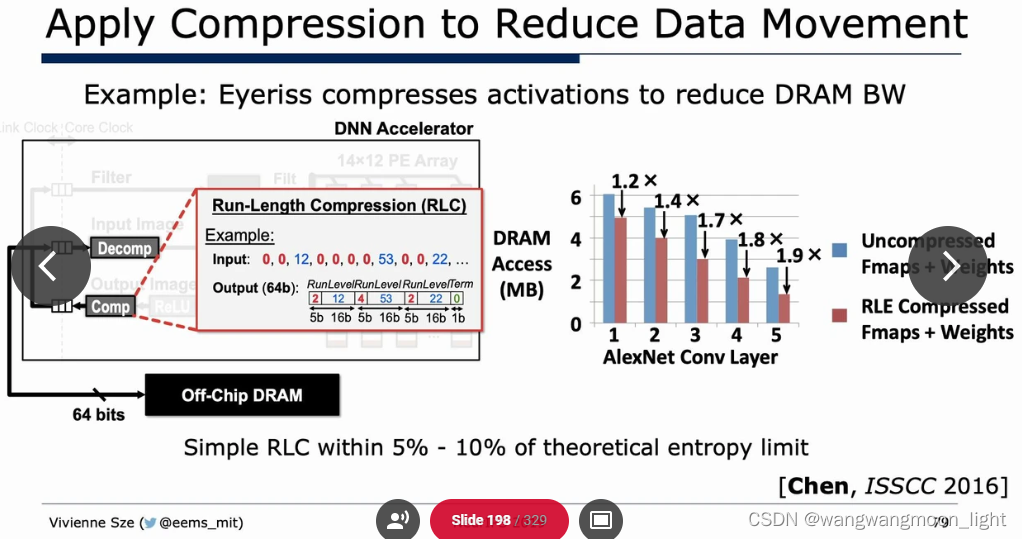
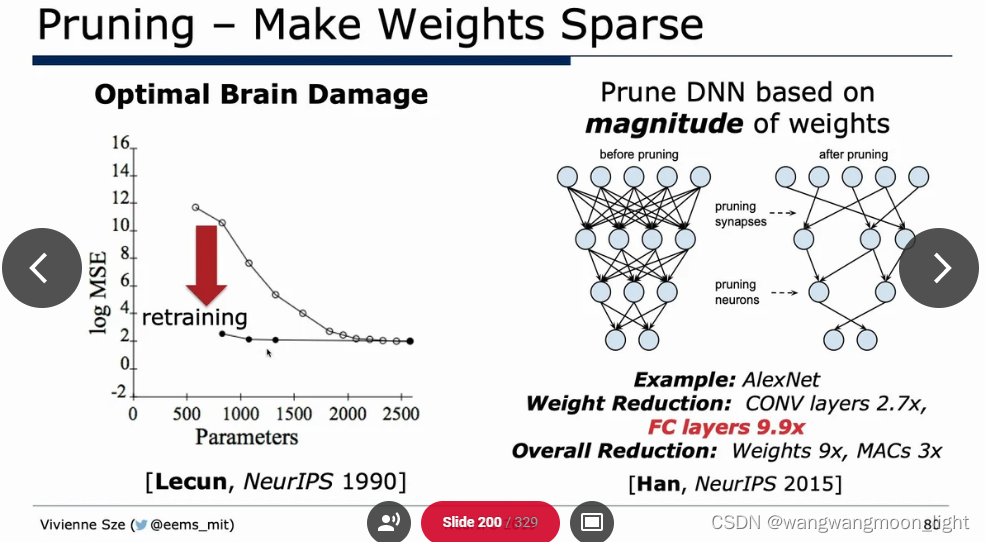

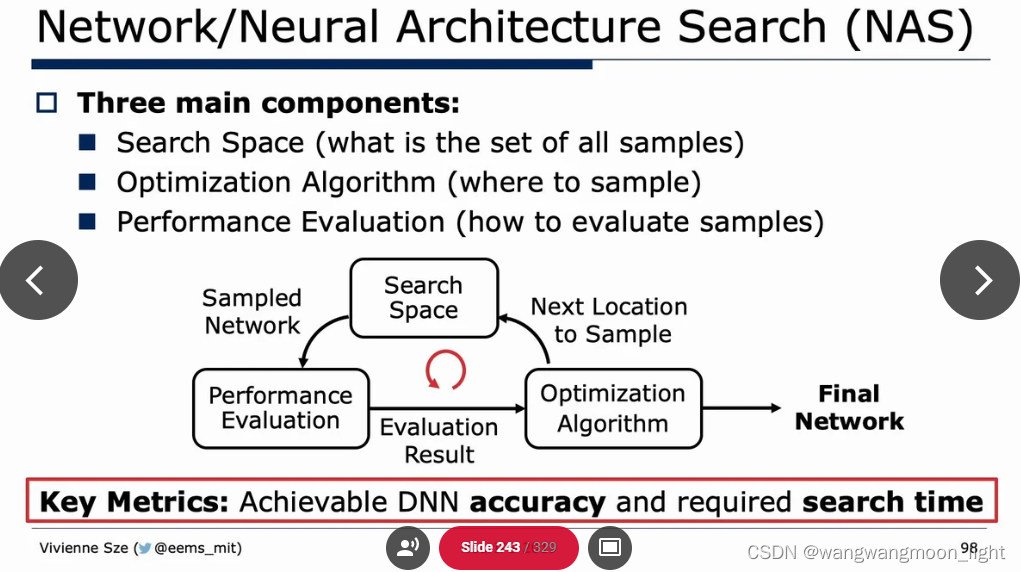
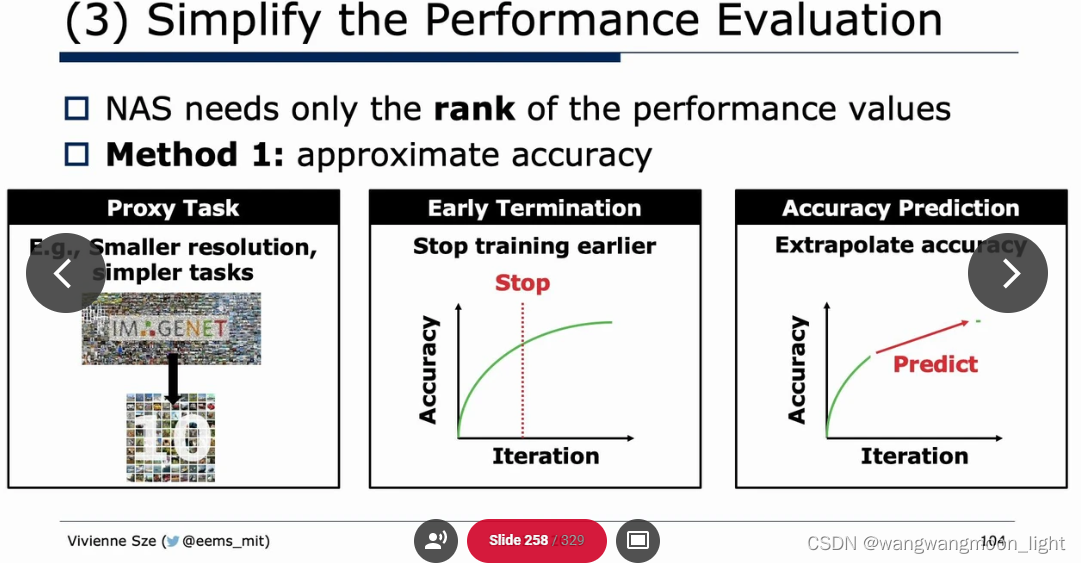
Efficient network architecture:
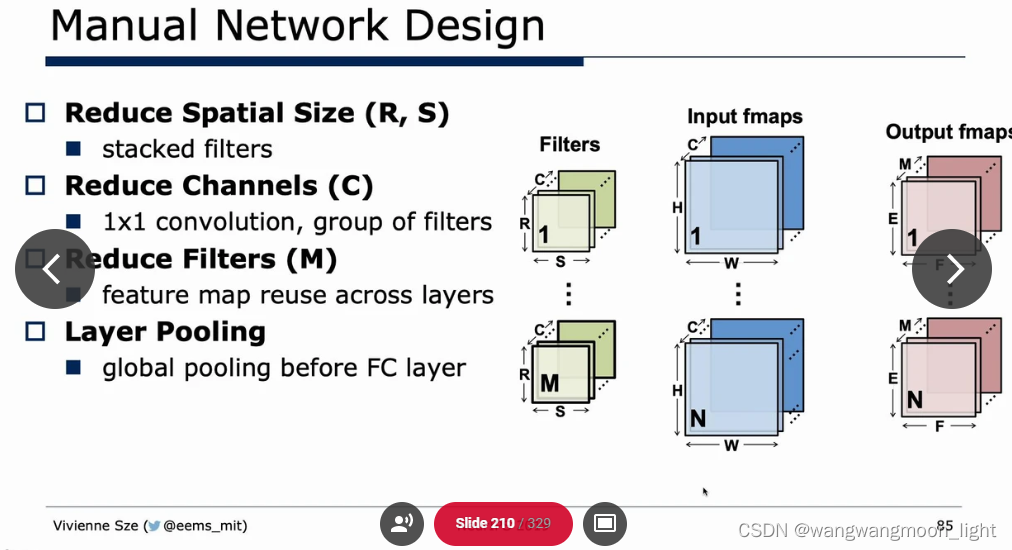
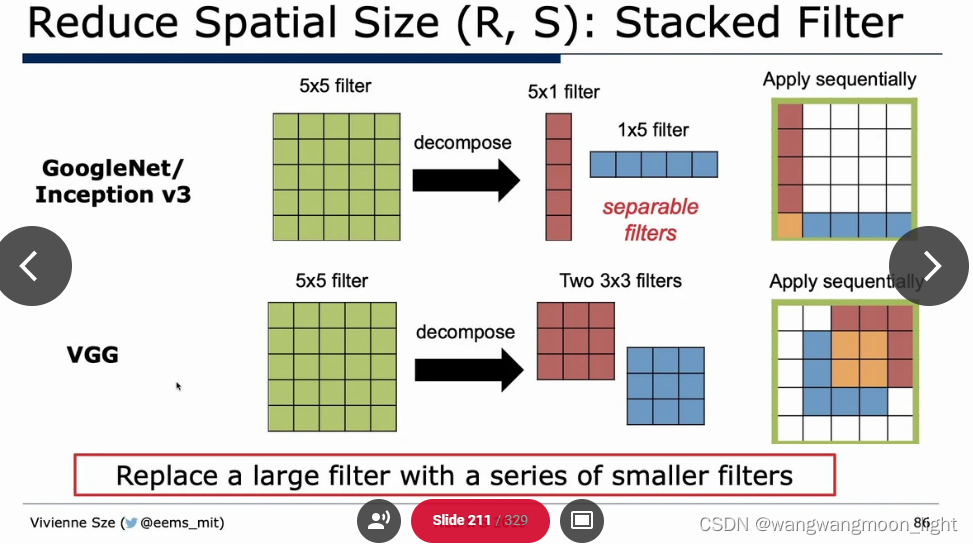
Sparsity: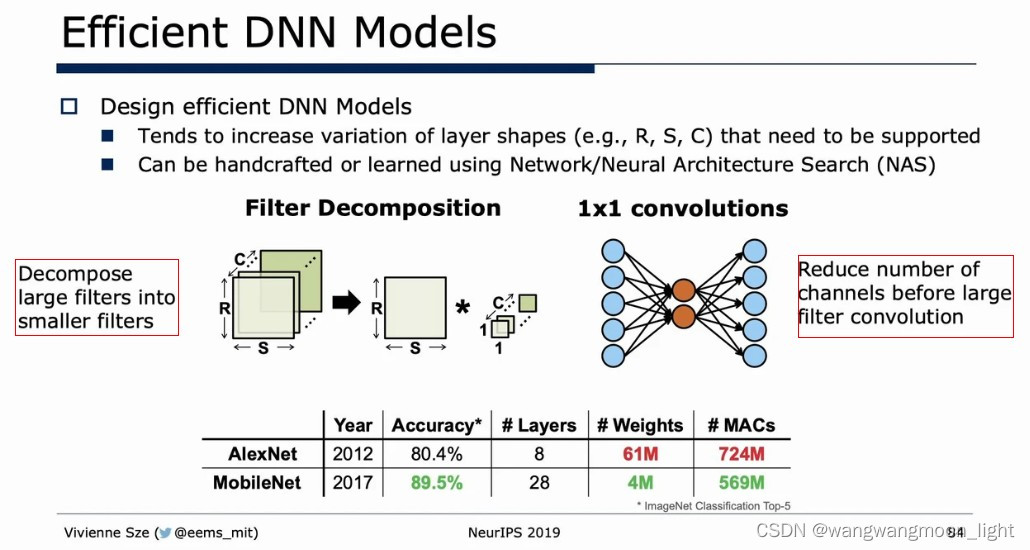
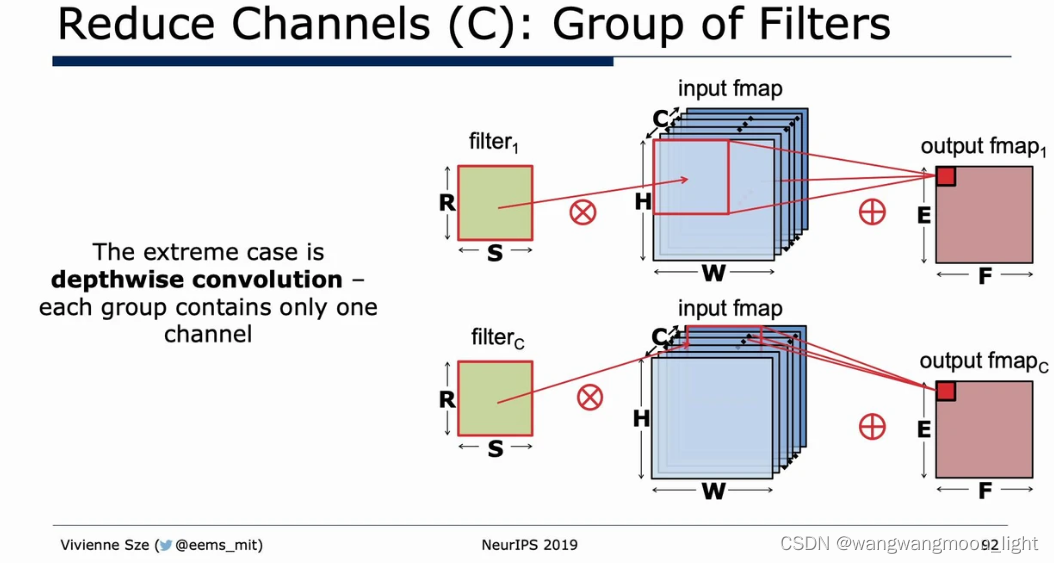
Depthwise convolution:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2158
2158




 到【灌水乐园】发言
到【灌水乐园】发言







