




【机器学习-14】-逻辑回归 vs. Softmax回归:核心公式与解题指南
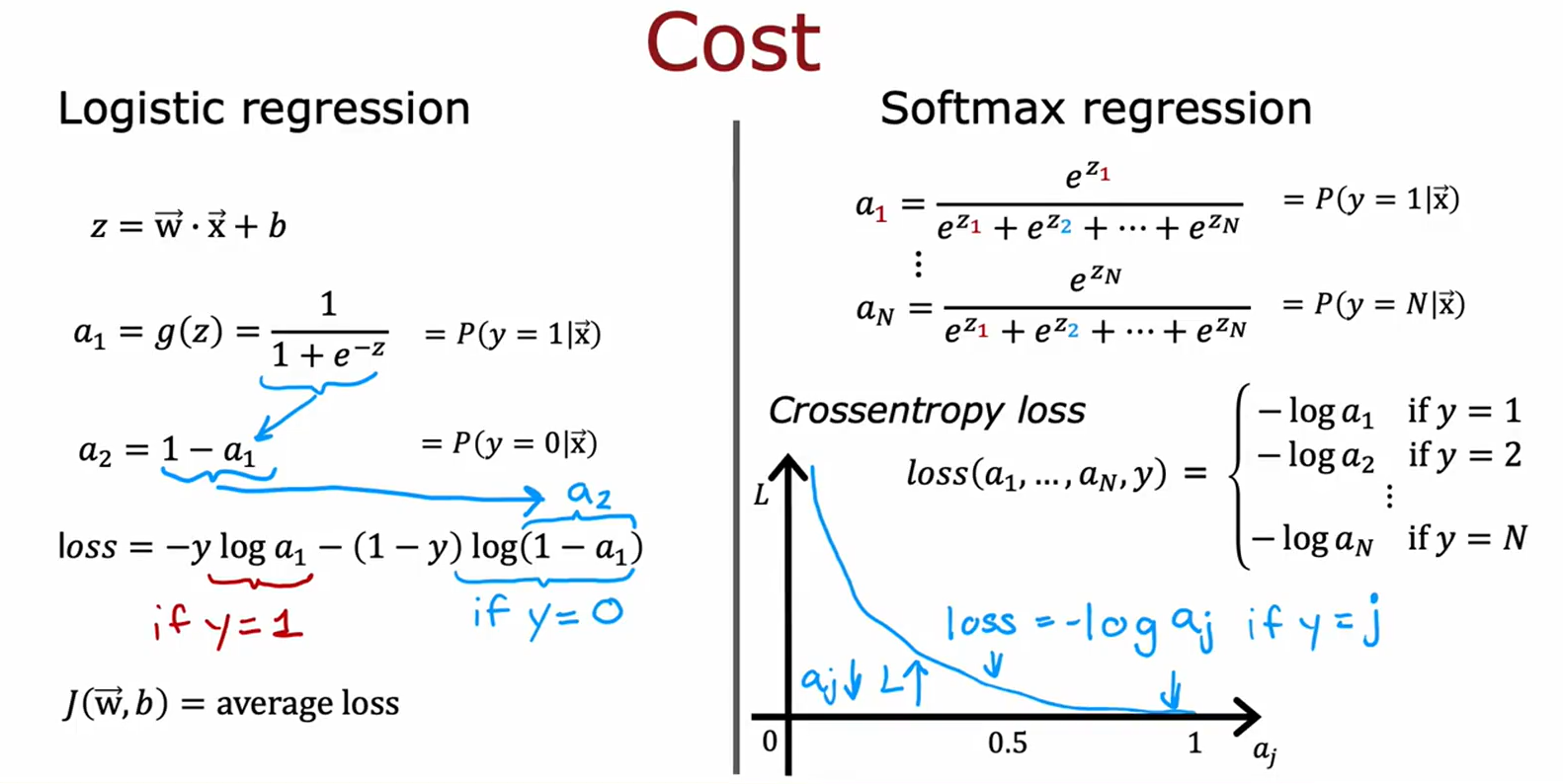
1. 逻辑回归(Logistic Regression)
适用场景:二分类问题(如判断肿瘤恶性/良性)
核心公式:
z=w⋅x+b(线性组合)a1=g(z)=11+e−z=P(y=1∣x)(Sigmoid函数)a2=1−a1=P(y=0∣x)\begin{align*} z &= \mathbf{w} \cdot \mathbf{x} + b \quad \text{(线性组合)} \\ a_1 &= g(z) = \frac{1}{1 + e^{-z}} = P(y=1 \mid \mathbf{x}) \quad \text{(Sigmoid函数)} \\ a_2 &= 1 - a_1 = P(y=0 \mid \mathbf{x}) \end{align*}za1a2=w⋅x+b(线性组合)=g(z)=1+e−z1=P(y=1∣x)(Sigmoid函数)=1−a1=P(y=0∣x)
解题步骤:
- 计算线性得分 z=w⋅x+bz = \mathbf{w} \cdot \mathbf{x} + bz=w⋅x+b。
- 通过Sigmoid函数将 ( z ) 映射为概率 ( a_1 )。
- 设定阈值(如0.5)判定类别:
• 若 a1≥0.5a_1 \geq 0.5a1≥0.5,预测 ( y=1 );否则 ( y=0 )。
2. Softmax回归(Softmax Regression)
适用场景:多分类问题(如手写数字识别,4个类别)
核心公式:
zj=wj⋅x+bj(第j类的线性得分)aj=ezj∑k=1Nezk=P(y=j∣x)(Softmax函数)\begin{align*}
z_j &= \mathbf{w}_j \cdot \mathbf{x} + b_j \quad \text{(第j类的线性得分)} \\
a_j &= \frac{e^{z_j}}{\sum_{k=1}^N e^{z_k}} = P(y=j \mid \mathbf{x}) \quad \text{(Softmax函数)}
\end{align*}zjaj=wj⋅x+bj(第j类的线性得分)=∑k=1Nezkezj=P(y=j∣x)(Softmax函数)
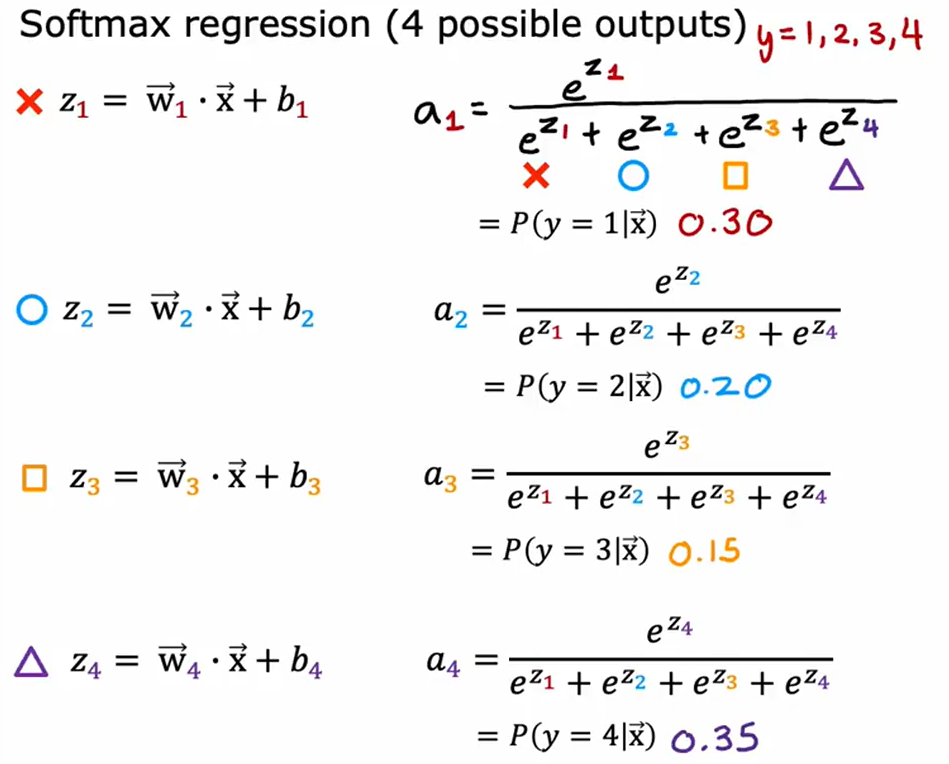
特性:
• 所有类别概率之和为1(∑j=1Naj=1\sum_{j=1}^N a_j = 1∑j=1Naj=1)。
• 输出概率最大的类别为预测结果。
解题步骤:
- 对每个类别计算线性得分 zjz_jzj。
- 通过Softmax函数归一化为概率分布 ( a_j )。
- 选择概率最大的 ( a_j ) 对应的类别。
• 逻辑回归损失函数(二元交叉熵):
loss=−yloga1−(1−y)log(1−a1) \text{loss} = -y \log a_1 - (1 - y) \log(1 - a_1)loss=−yloga1−(1−y)log(1−a1)
• Softmax回归损失函数(多元交叉熵):
loss=−logaj\text{loss} = -\log a_jloss=−logaj(( j )为真实类别标签)
3. 关键对比
| 特性 | 逻辑回归 | Softmax回归 |
|---|---|---|
| 输出类别数 | 2(二分类) | ( N )(多分类) |
| 激活函数 | Sigmoid | Softmax |
| 概率归一化 | a1+a2=1a_1 + a_2 = 1a1+a2=1 | ∑j=1Naj=1\sum_{j=1}^N a_j = 1∑j=1Naj=1 |
| 参数数量 | 1组权重 ( \mathbf{w} ) | ( N ) 组权重 ( \mathbf{w}_j ) |


















 2502
2502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









