




【机器学习-06】-学习率的选择
系统地解释了梯度下降算法(Gradient Descent)的核心概念及其关键参数——学习率(α)的作用,具体内容可总结如下:
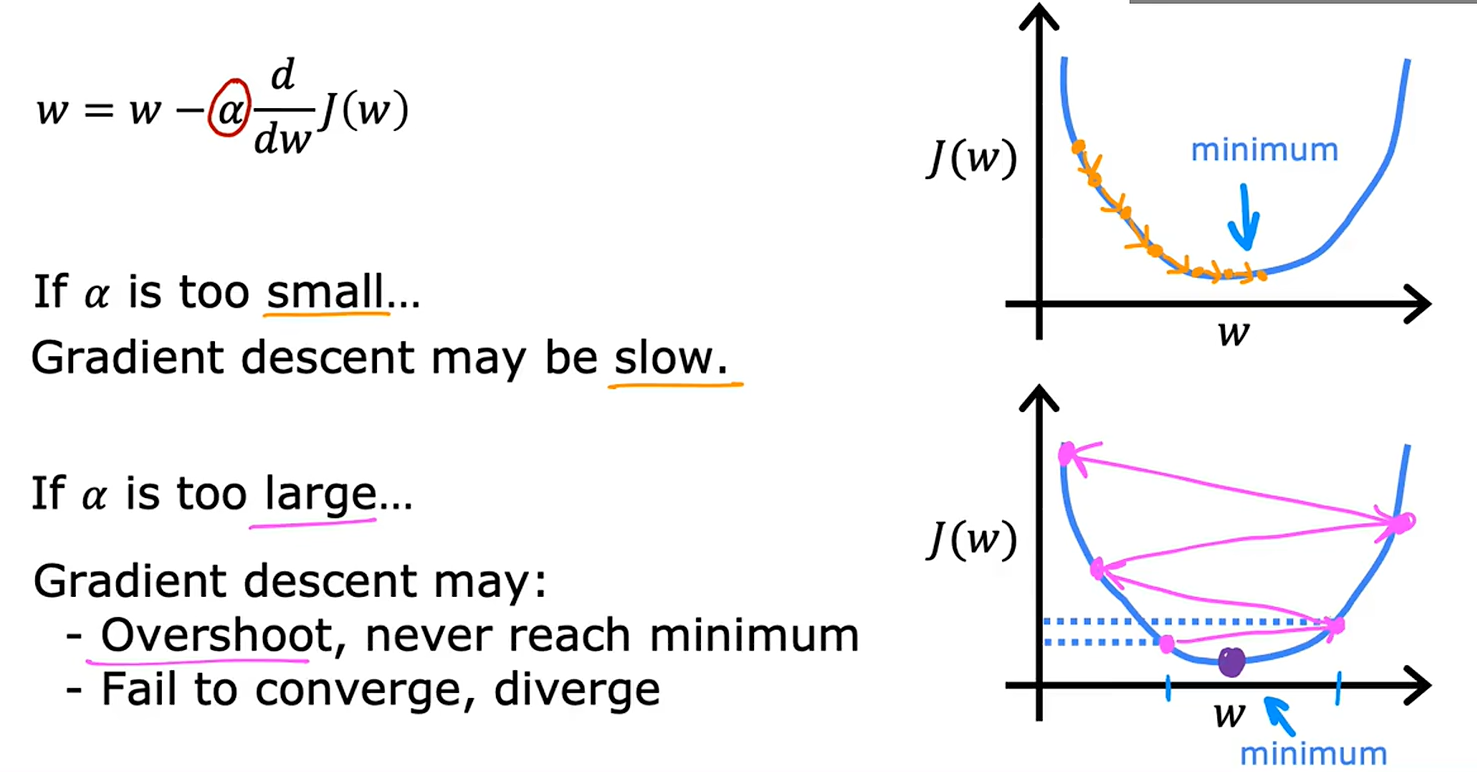
1. 学习率(α)对优化过程的影响(第1张图)
• 核心公式:参数更新规则
w
=
w
−
α
d
d
w
J
(
w
)
w = w - \alpha \frac{d}{dw} J(w)
w=w−αdwdJ(w)
• 通过调整参数 ( w ) 沿损失函数 ( J(w) ) 的负梯度方向移动,逐步逼近最小值。
• 学习率的作用:
• α过小:收敛速度慢,需要多次迭代才能接近最小值(如图中缓慢下降的路径)。
• α过大:可能导致优化过程不稳定,表现为:
◦ 越过最小值(overshoot)。
◦ 无法收敛甚至发散(如震荡或偏离最小值的路径)。
• 图示:通过不同颜色的优化路径对比,直观展示了学习率选择的重要性。
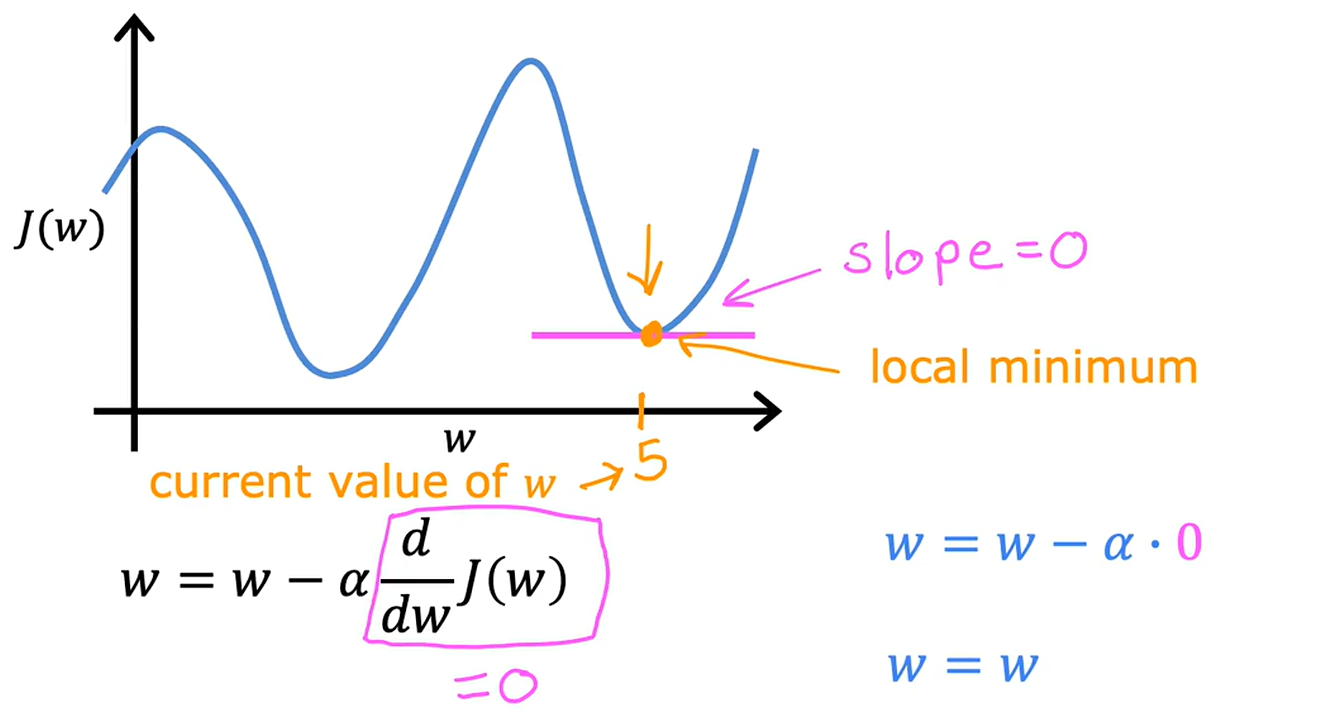
2. 局部最小值与梯度下降的收敛性(第2张图)
• 局部最小值:损失函数曲线上的一个低点(标注为 “local minimum”),此处梯度(斜率)为零(slope=0)。
• 固定学习率的可行性:
• 即使学习率α固定,梯度下降仍可能收敛到局部最小值,因为随着接近最小值,梯度
d
d
w
J
(
w
)
\frac{d}{dw} J(w)
dwdJ(w)逐渐减小,步长自然变小(如图中箭头逐渐缩短)。
• 关键点:在局部最小值处,梯度为零,参数 ( w ) 不再更新。
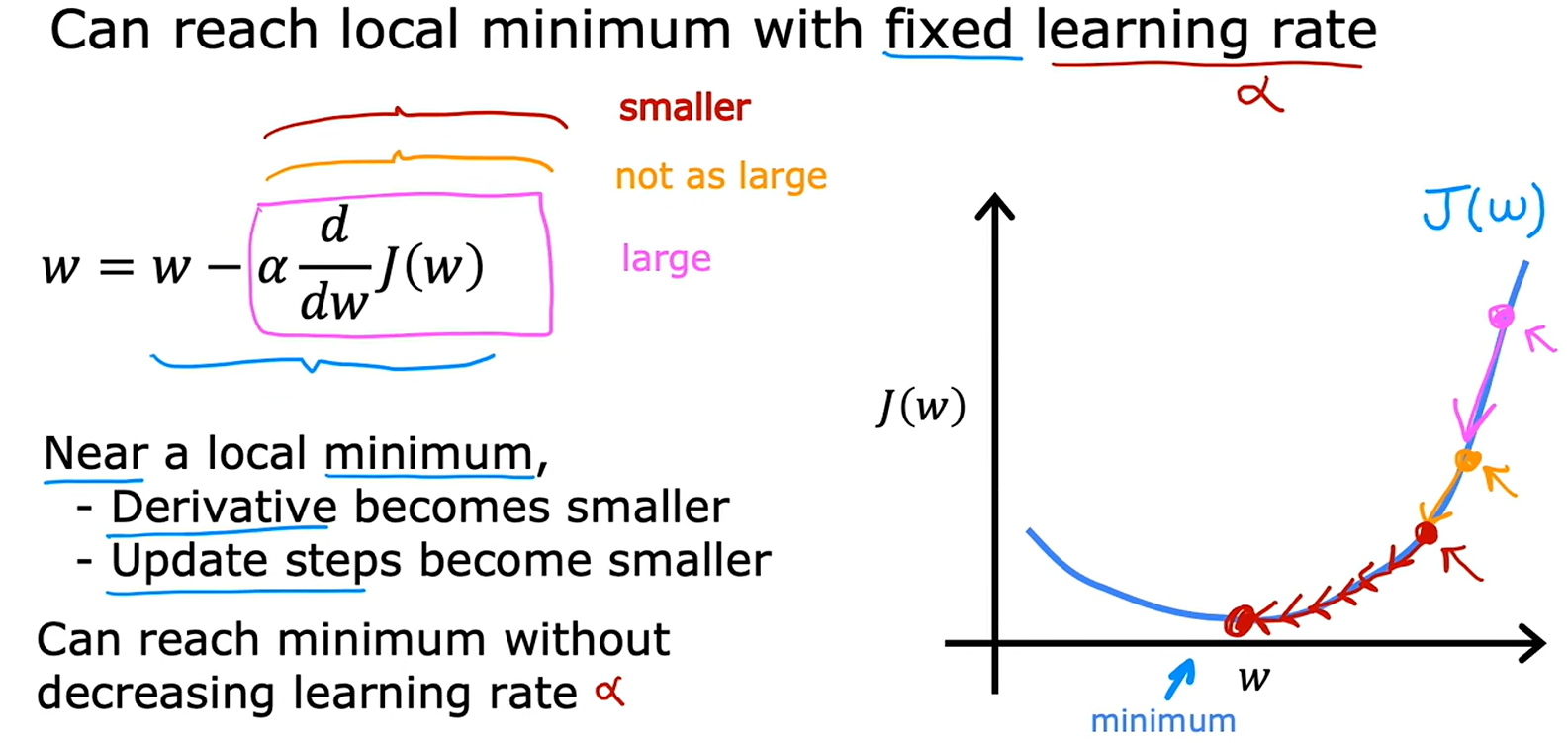
3. 固定学习率下的优化过程(第3张图)
• 动态调整步长:
• 初始阶段:梯度较大,参数更新步长较大(图中 “large” 箭头)。
• 接近局部最小值时:梯度变小,步长自动减小(图中 “smaller” 箭头),无需手动降低α。
• 结论:固定学习率在合理范围内仍可保证收敛,因为梯度本身会调节步长。
三幅图的整体关联
- 学习率的选择(第1张图)是梯度下降能否有效收敛的前提。
- 局部最小值(第2张图)是优化的目标,固定学习率下可通过梯度自适应达到。
- 优化过程的动态性(第3张图)解释了为何固定学习率在理论上是可行的——梯度变化自然控制了步长。
关键启示:
梯度下降的成功依赖于合理的学习率,但即使α固定,算法仍能通过梯度变化自适应调整步长,最终收敛到局部最小值(假设函数性质良好,如凸函数或平滑的非凸函数)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









