






 本文深入解析XGBoost算法,涵盖CART树原理、损失函数、分裂节点算法、正则化及对缺失值处理等核心内容,并探讨XGBoost的优化策略与参数设置。
本文深入解析XGBoost算法,涵盖CART树原理、损失函数、分裂节点算法、正则化及对缺失值处理等核心内容,并探讨XGBoost的优化策略与参数设置。
目录
1.CART树
CART树(分类与回归树),可以用于分类也可以用于回归。其内部节点特征的取值为“是”和“否”,节点的左分支取值为“是”,节点de的右分支取值为“否”。对于回归树使用平均误差最小化准则,对于分类树使用ji基尼指数最小化准则。


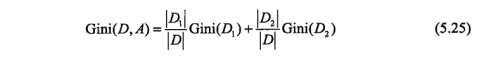
2.算法原理
xgb就是Tree Ensemble。xgb就是K棵树的累加。



在这里 插入泰勒公式
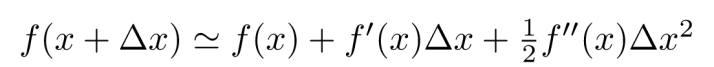
在这里![]() 是
是![]() ,
,![]() 是
是![]() ,可以想成在原来损失函数
,可以想成在原来损失函数![]() 的基础上添加
的基础上添加![]() 使损失函数更小。
使损失函数更小。

讲完了训练过程,需要讲一下正则项

另外xgb可以评估每个树的得分



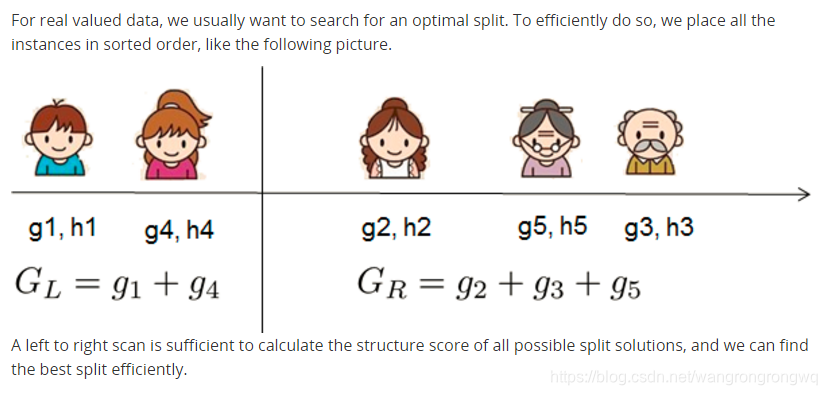
因为可以评估每棵树的得分,所以可以枚举出所有的树,然后计算每棵树的得分,然后保留得分最高的树,但是实际中这样的操作是不现实的,所以xgb尝试优化树的每层。计算将该节点分裂的得分,然后将该节点分裂之后的得分与没有将该节点分裂的得分做差,从而来判断是否分裂该节点。

3.损失函数
3.1logistic损失函数
3.2对数损失函数
3.3平方误差损失函数
4.分裂节点算法
前面提到过,XGBoost每一步选能使分裂后增益最大的分裂点进行分裂。而分裂点的选取之前是枚举所有分割点,这称为精确的贪心法(Exact Greedy Algorithm).当数据量十分庞大,以致于不能全部放入内存时,Exact Greedy 算法就会很慢。因此XGBoost引入了近似的算法。即对每一个特征进行「值」采样。原来需要对每一个特征的每一个可能分割点进行尝试,采样之后只针对采样的点(分位数)进行分割尝试,这种方法很明显可以减少计算量,采样密度越小计算的越快,拟合程度也会越差,所以采样还可以防止过拟合。


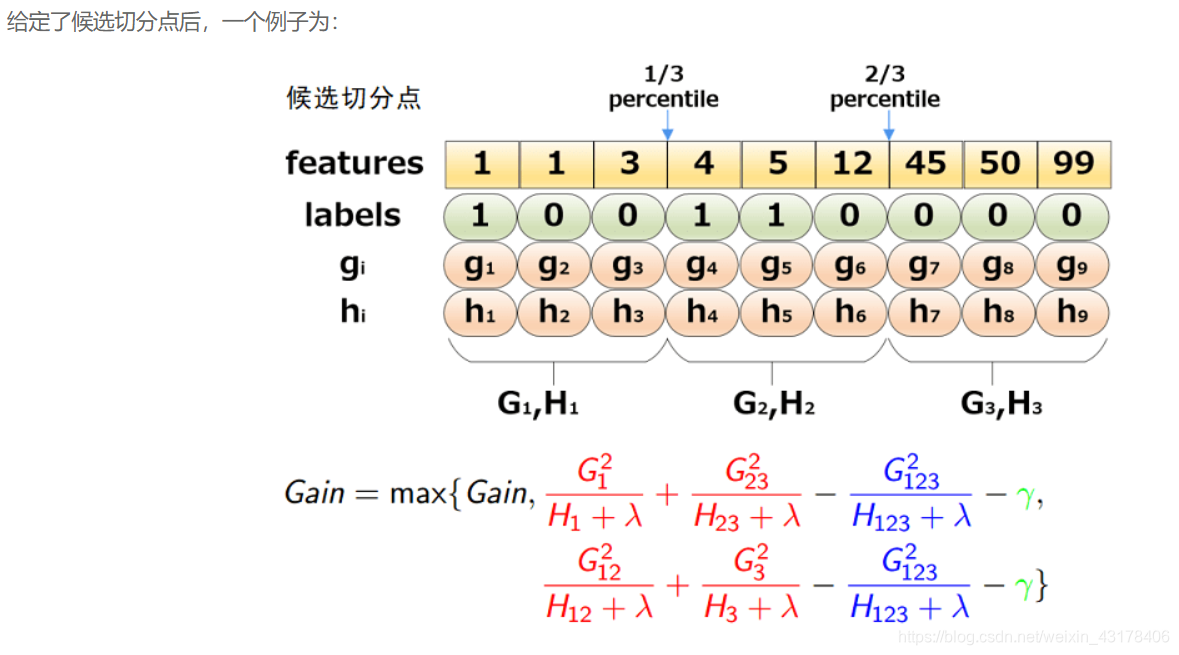
那么,现在有两个问题:
1.如何选取候选切分点Sk={sk1,sk2,⋯skl}呢?(即选择特征的哪些分位数作为备选的分裂点呢?)
2.什么时候进行候选切分点的选取?
针对问题2:
第二个方法执行采样的方式有两个,一种是global模式,一种是local模式。global模式是执行树生成之前采一次样,后面不再更新( 学习每棵树前, 提出候选切分点);local模式是每次split之后都再次进行一次采样(每次分裂前, 重新提出候选切分点)。不同的模式和不同的采样密度带来的效果如下图: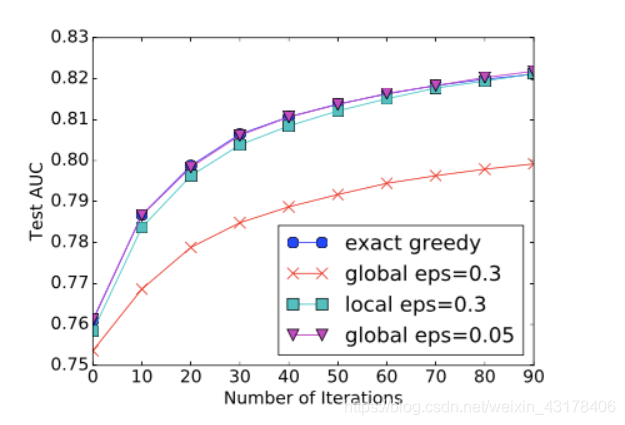
桶的个数等于 1 / eps, 可以看出:
全局切分点的个数够多的时候,和Exact greedy算法性能相当。
局部切分点个数不需要那么多,因为每一次分裂都重新进行了选择。
下面对第一个问题进行解答,选择哪些候选切分点。
对于问题1,可以采用分位数,也可以直接构造梯度统计的近似直方图等。
简单的分位数就是先把数值进行排序,然后根据你采用的几分位数把数据分为几份即可。而XGBoost不单单是采用简单的分位数的方法,而是对分位数进行加权(使用二阶梯度h),称为:Weighted Quantile Sketch。PS:上面的那个例子采用的是没有使用二阶导加权的分位数。



5.正则化
前面的算法原理已经讲了正则化,但是xgb中的其他ca操作也会fa防止过拟合

另外分裂节点算法的算法2分裂-分裂节点的近似算法也会防止过拟合。
6.对缺失值的处理
有很多种原因可能导致特征的稀疏(缺失),所以当遇到样本某个维度的特征缺失的时候,就不能知道这个样本会落在左孩子还是右孩子。xgboost处理缺失值的方法和其他树模型不同。根据作者TianqiChen在论文[1]中章节3.4的介绍,xgboost把缺失值当做稀疏矩阵来对待,本身在节点分裂时不考虑缺失值的数值,但确定分裂的特征后,缺失值数据会被分到左子树和右子树呢?本文的处理策略是落在哪个孩子得分高,就放到哪里。如果训练中没有数据缺失,预测时出现了数据缺失,那么默认被分类到右子树。具体的介绍可以参考:
7.xgb的其他优化
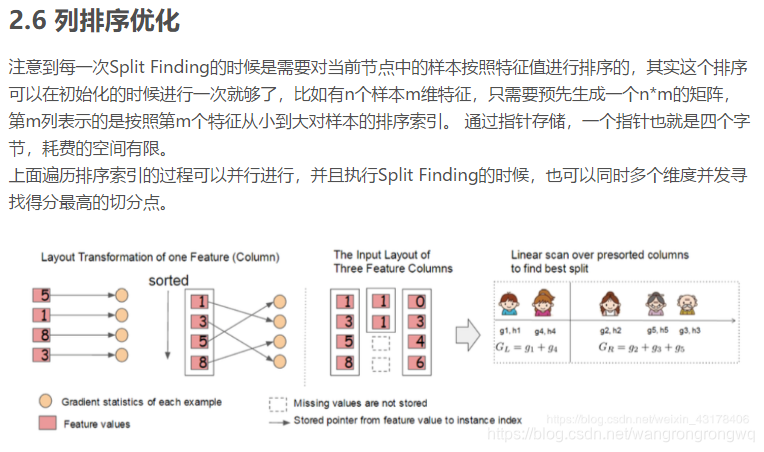
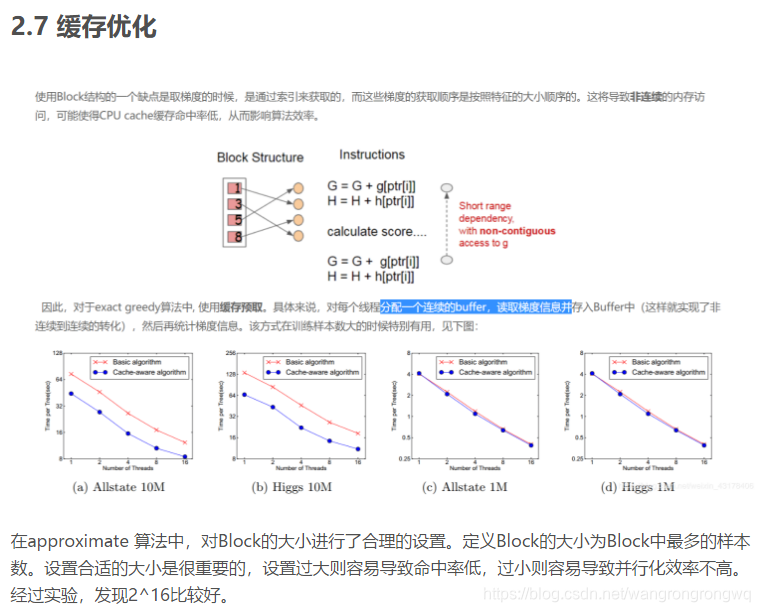
8.xgb参数
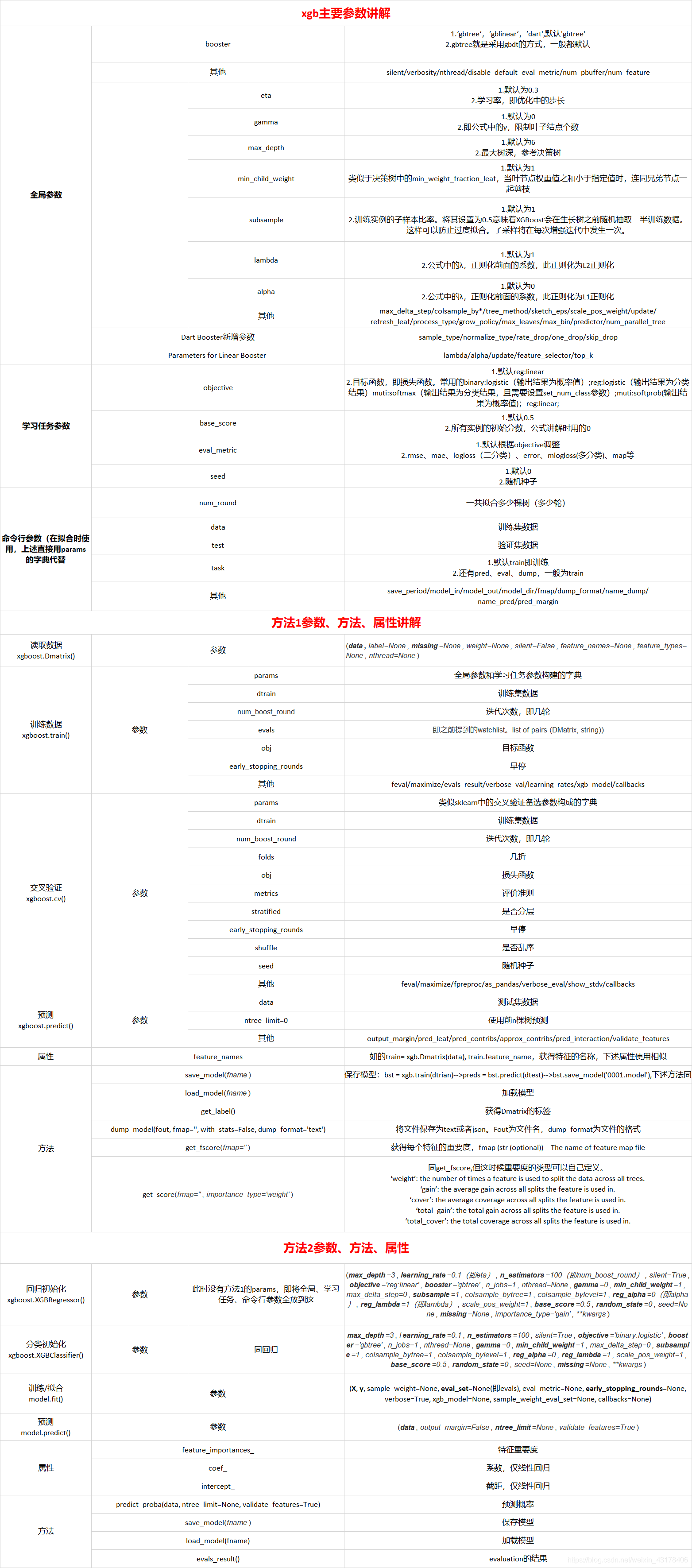
9.xgb常问面试问题
https://blog.youkuaiyun.com/weixin_43178406/article/details/86706979
参考资料
https://blog.youkuaiyun.com/weixin_43178406/article/details/86706979
https://xgboost.readthedocs.io/en/latest/tutorials/model.html
陈天奇论文与ppt
https://www.cnblogs.com/wxquare/p/5541414.html
https://www.cnblogs.com/wkslearner/p/8672334.html
https://x-algo.cn/index.php/2016/07/24/xgboost-principle/
https://www.hrwhisper.me/machine-learning-xgboost/
https://blog.youkuaiyun.com/a819825294/article/details/51206410

















 1927
1927




 到【灌水乐园】发言
到【灌水乐园】发言







