




 本文详细介绍了 UTF-8 编码规则及其在 Objective-C 中的实现方法,包括如何计算字符串长度及获取指定索引处的字符。通过深入解析 UTF-8 的存储方式,帮助开发者理解并正确处理包含中文等非 ASCII 字符的字符串。
本文详细介绍了 UTF-8 编码规则及其在 Objective-C 中的实现方法,包括如何计算字符串长度及获取指定索引处的字符。通过深入解析 UTF-8 的存储方式,帮助开发者理解并正确处理包含中文等非 ASCII 字符的字符串。
一 UTF8存储规则
UTF8是Unicode编码的实现之一,相似的还有UTF16,UTF32等等.Unicode编码是为了解决ascii不能表示世界所有国家字符的设计的,它的编码统一是2个字节,如果是ascii字符则会加上一个0字节.但是用它来编码那么内存中的ascii字符都要用两个字节,一个英文文档大小要加倍,所以就有了UTF8来解决这一总是.
UTF8编码是一种变长的编码方式,用1到4个字节存储1个字符,ascii字符依然用1个字节存储,非ascii字符就将Unicode中的编码通过转码规则存储.
具体转码规则,可以百度,大体是 一个n字节的Unicode字符,转换成UTF8从右向左存放,一个字节存放6位,高的两位是10,最高位的字节前n位为1,第n+1们为0 ,最高位的字节1的个数最少是2(2个字节),最多是4(4个字节),ascii字符是0.
所以一个UTF8字符串,如果某个字节的最高为0,说明这个字节存放的是ascii字符,如果某个字节的高位 连续的1的个数不为0,那1的个数就是这个字符存储的字节数
注:下面的两个方法实现代码只适用于大端存储格式(低地址存放高字节)
二 length
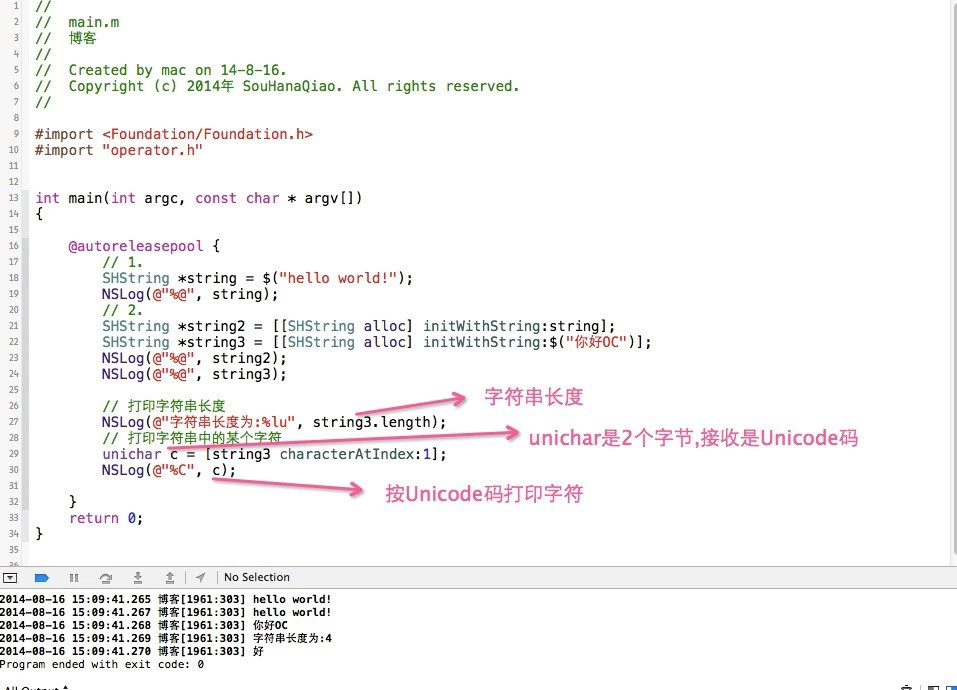
了解了上面的UTF8编码规则写一个获取字符串字符个数的方法就清晰明了了.
// 判断是否是Unicode字符(非ascii字符),参数2为存储的字节数,适用于大端存储格式
- (BOOL)isUnicode:(const char)c andByteCount:(NSUInteger *)byteCount
{
int i = 0;
for (i = 7; (c >> i) & 1; i--);
if (i == 7) { // 是ascii 字符
*byteCount = 1;
return NO;
}
*byteCount = 7 - i; // 字节数
return YES;
}
// 字符串的长度
- (NSUInteger)length
{
char *p = (char*)_string;
NSUInteger count = 0; // 当前字符个数
NSUInteger byteCount = 0; // 当前字符的字节数
while (*p) // 默认是从字符的高地址读起
{
//int i = 0;
//for (i = 7; (*p >> i) & 1; i--); // 查找当前字节(是否有UTF-8的非ascii字符)
BOOL isUnicodeChar = [self isUnicode:*p andByteCount:&byteCount];
// 当前字符为 字母
if (/*i == 7*/isUnicodeChar == NO)
{
count++; // 字符个数加1
p++; // 指向下一个字节
} else if (/*i < 7*/isUnicodeChar == YES) // 当前字符为 汉字(或非ascio字符)
{
count++; // 字符数加1
p += /*(7 - i)*/ byteCount; // 指向下一个字符(跳过7 - i个字节)
}
}
return count;
}二 CharacterAtIndex:
这个方法实现要先通过一个循环找到第index个字符的首地址,再将这个字符的UTF8编码转换成Unocode编码,转码算法是根据首字节(高字节,大端格式)中1的个数进行,如果没有1,说明是ascii字符直接返回该字节的值,如果有n个1,就从第0位依次读取到第 8 - n - 1(-1是因为连续的1后面有个0不用读取)位,此后的 n-1 个字节都从 第 0 位读取到 第 5 位共 6 位,
将这些读取到的 位组成的二进制数 转换成十进制数就是Unicode码
- (unichar)charActerAtIndex:(NSUInteger)index
{
char *p = (char *)_string;
unichar num = 0; // 要返回的ascii值或unicode值
NSUInteger newIndex = 0; // 当前下标
//NSUInteger bit = 0; // 表示位数
NSUInteger byteCount = 0; // 字节数
BOOL isUnicodeChar; // 是否是ascii字符
while (newIndex != index) // 找到第index个字符(可能包含非ascii字符)
{
//for (bit = 7; (*p >> bit) & 1 ; bit--); // 判断当前字节是什么字符
isUnicodeChar = [self isUnicode:*p andByteCount:&byteCount];
if (/*bit == 7*/ isUnicodeChar == NO) { // 是ascii字符
p++;
newIndex++;
}
else if (/*bit < 7*/ isUnicodeChar == YES) // 不是ascii字符
{
p += /*7 - bit*/ byteCount; // 跳过 7 - bit 个字节数
newIndex++;
}
}
// 此时p已经指向了第index个字符的首地址
// 找到当前字符的ascii值或unicode值
//for (bit = 7; (*p >> bit) & 1 ; bit--);
isUnicodeChar = [self isUnicode:*p andByteCount:&byteCount];
if (/*bit == 7*/ isUnicodeChar == NO)
{
num = *p;
} else if (/*bit < 7*/ isUnicodeChar == YES)
{
NSUInteger Byte = /*7 - bit*/ byteCount; // 字节数
NSUInteger i = 8 - /*(7 - bit)*/ byteCount - 1; // 首个字节(最高字节)
NSUInteger d = 16;
while (Byte)
{
for (int j = (int)i; j >= 0; j--)
{
num += ((*p >> j) & 1) * pow(2, d--);
}
i = 5;
Byte--;
p++;
}
}
return num;
}

















 1481
1481


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








