




 本文详细介绍了如何在Elasticsearch中配置IKAnalyzer的扩展字典和停止词字典,通过自定义my.dic文件实现特定词汇不分词,确保如'王者荣耀'等专有名词的完整性。
本文详细介绍了如何在Elasticsearch中配置IKAnalyzer的扩展字典和停止词字典,通过自定义my.dic文件实现特定词汇不分词,确保如'王者荣耀'等专有名词的完整性。
在Elasticsearch的安装目录下找到文件IKAnalyzer.cfg.xml,内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom/mydict.dic;custom/single_word_low_freq.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">custom/ext_stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
<entry key="ext_dict">custom/mydict.dic;custom/single_word_low_freq.dic</entry>
这行中定义了扩展分词,即哪些词汇不拆分,标签中配置的是文件路径,默认在custom文件夹下,自定义扩展分词的时候首先在custom文件夹下新增一个文件my.dic,将文件的路径添加到以上标签如下:
<entry key="ext_dict">custom/my.dic;custom/mydict.dic;custom/single_word_low_freq.dic</entry>
注意事项:
1.定义的my.dic文件必须使用无BOM的UTF-8编码保存的文件。如果不确定什么是无BOM的UTF-8编码,最简单的方式就是用Notepad++编辑器打开,Encoding->选择 Encoding in UTF-8 without BOM,然后保存。若Notepad++没有该编码,则如下操作即可:
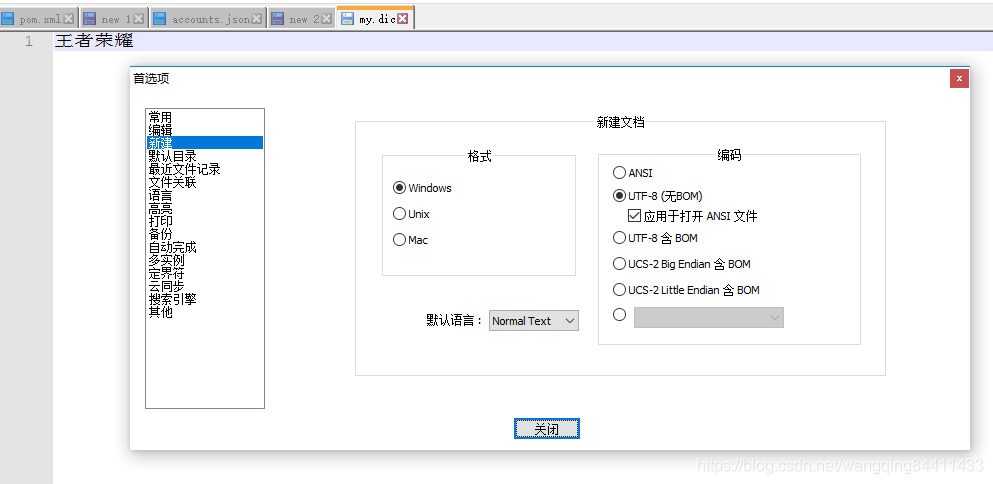
2.建议不要使用记事本等其他方式打开,否则会修改编码的方式,使扩展分词失效
案例如下:
在没有配置扩展分词前:
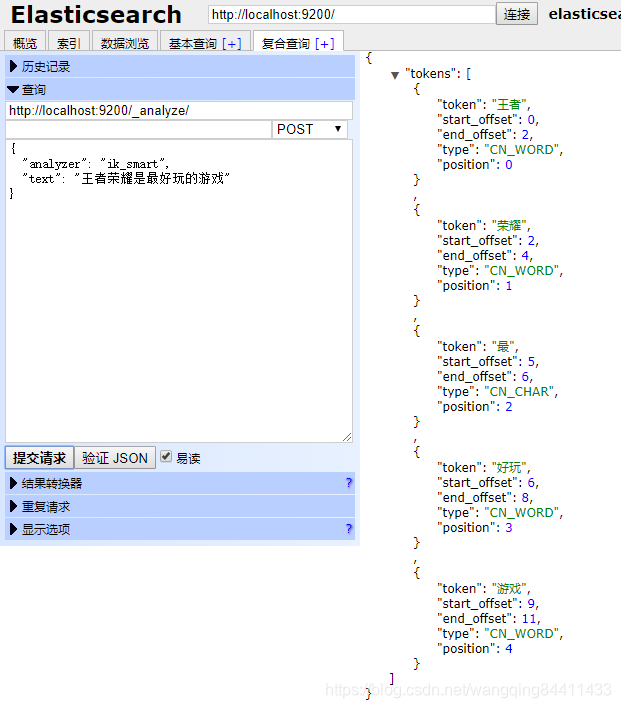
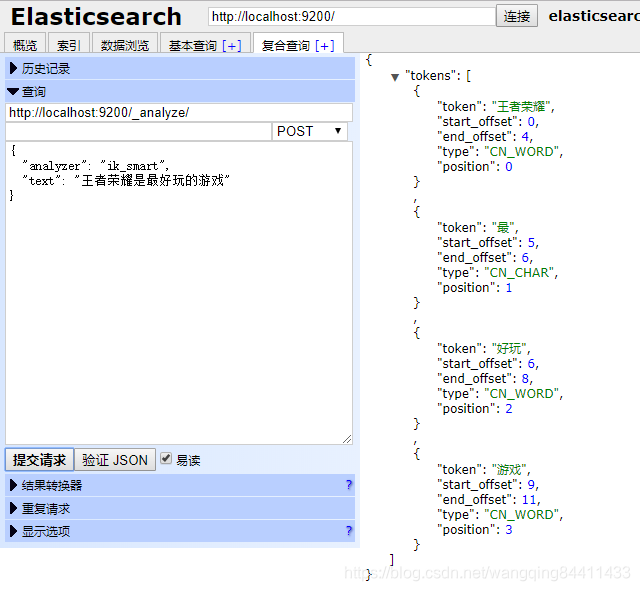
中文ik分词词库里面将“王者荣耀”是分开的,但是我们又不愿意将其分开则可以使用扩展分词,按照上面的步骤配置,文件如下:
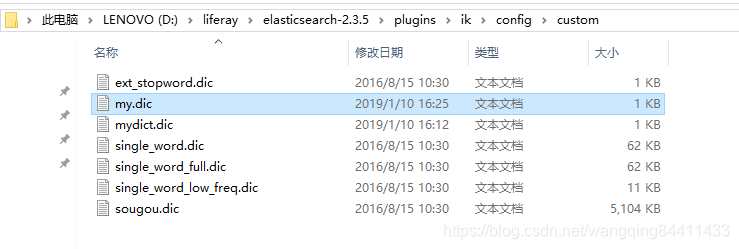
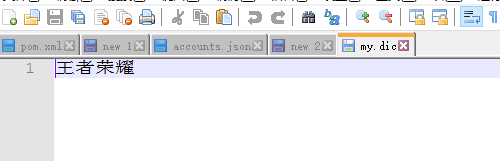
重启ES,查询结果如下:


















 2238
2238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











