



(2 封私信) 你的ChatBI(问数)准确率不到50%?带你深度拆解90%准确率的高德ChatBI案例 - 知乎
以"上周用户导航UV是多少"为例,模型需要理解:
- 导航UV是什么?对应哪个字段?
- 时间范围如何定义?

高德团队设计了四层元数据:
1. 业务域层,快速定位场景
识别这是导航业务、搜索业务还是路况业务。
2. 表结构层,提供数据基础
表业务含义、字段取值范围、关联关系(决定多表查询准确性)。
3. 业务知识层,处理专业术语和"黑话"
像"导航UV"这种导航业务特有概念,没有专门解释,模型可能理解成网站导航。
4. 通用知识层、标准化常用概念
数据分析常用概念、时间格式定义。
用户提问后,大致会经过下面5步,来得到生成sql需要的上下文:
- 分析指标项,识别所属业务域
- 分析查询对象和筛选条件,在业务域范围内确定需要的表和字段
- 匹配业务知识,根据指标项找到对应的业务解释
- 标准化通用概念,如时间条件的标准取值
- 上下文生成,将以上信息与用户问题一起给模型生成SQL
高德方式:业务域 + 表结构 + 业务知识 + 通用知识 + 用户问题 → 模型生成SQL
为了降低查询复杂度,通常把多张相关表的字段,构建成一张物理宽表,查询时直接查单表,避免复杂关联。
高德团队提出了“虚拟宽表”的思路
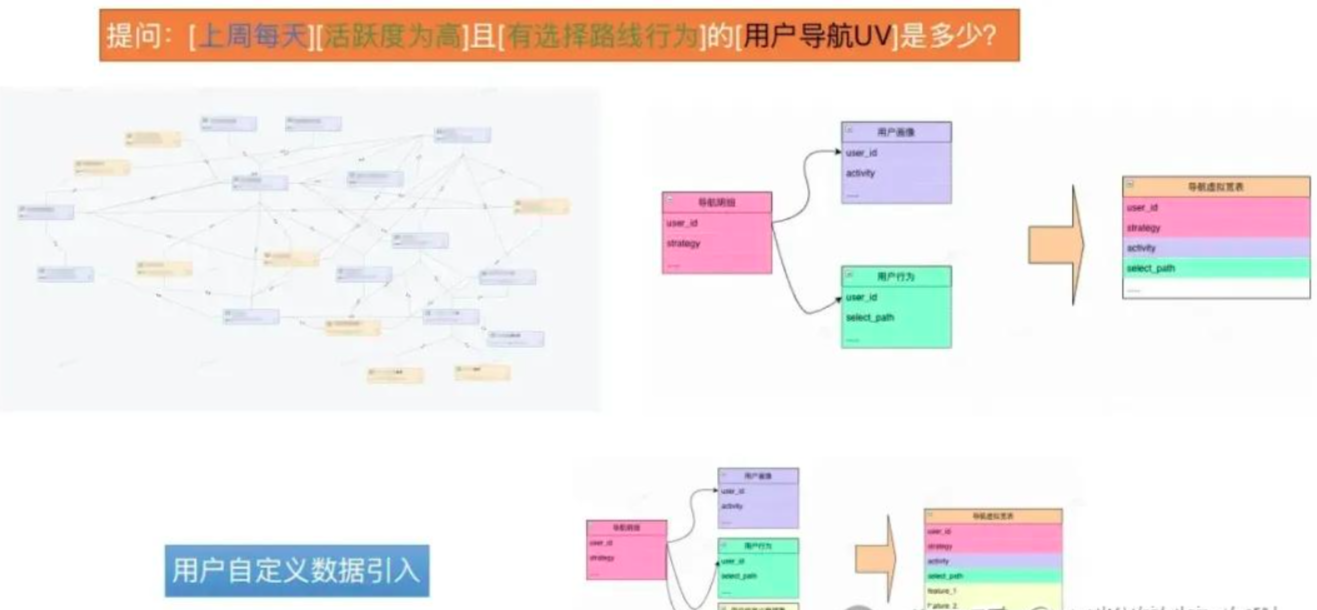
把"多张底表怎么拼、口径怎么取、权限怎么控"预先写成可查询的"视图"。
虚拟宽表带来的优势很明显:
1. 不用自己写复杂join、最新分区、去重逻辑
2. 口径统一,大家都用同一套视图,统计标准一致
3. 行列权限与脱敏内置到视图中,统一控制
4. 底表变更或接入自定义特征,只改视图即可
5. 需要时,仍可对热点查询进行物化提速
比如,用户问:“最近7天各导航策略的活跃用户数?”
CREATE VIEW vw_nav_virtual_wide AS
SELECT
a.user_id, a.strategy, a.ds,
p.activity, -- 从用户画像取活跃度
b.select_path, -- 从用户行为取选择路径
c.custom_label -- 预留自定义特征挂接点
FROM nav_detail a
LEFT JOIN user_profile p ON a.user_id = p.user_id
LEFT JOIN user_behavior b ON a.user_id = b.user_id
LEFT JOIN custom_features c ON a.user_id =c.user_id;--灵活扩展点AI只需要生成下面这个简单的单表查询sql
SELECT strategy, custom_label, COUNT(DISTINCT user_id) AS dau
FROM vw_nav_virtual_wide
WHERE ds >= current_date - 7 AND custom_label IS NOT NULL
GROUP BY strategy, custom_label;如果要对宽表添加新业务字段,单独更新custom_features 表即可,
视图会自动包含新字段,无需改底表或重新建模。
相比物理宽表,虚拟宽表避免了:大规模冗余存储、变更响应慢、数据治理困难。
这就是高德90%准确率的第四个思路:“一个完美平衡'物理宽表简单但同步困难'和'关联查询灵活但生成困难'的方案。”
元数据、虚拟宽表等基础设施就绪后,高德开始了ChatBI的三阶段演化之路。

第二阶段:引入单Agent + 设计原子工具
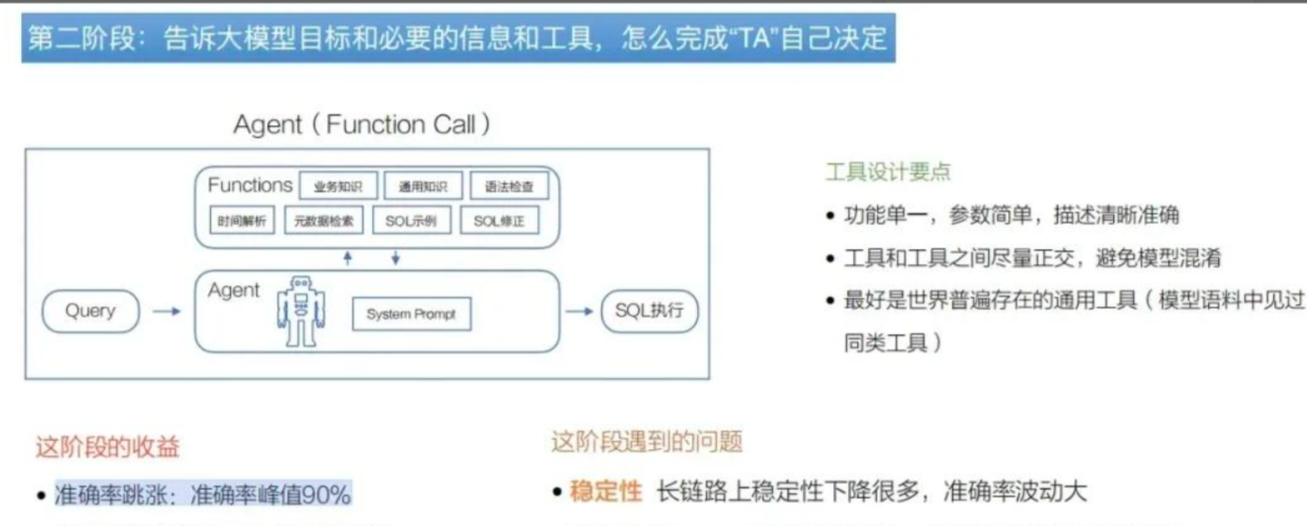
模型只负责任务理解、规划和工具选择,具体执行逻辑由各个工具负责。
不过仍有痛点:
复杂问题导致工具调用链路变长,准确率峰值波动;
原子工具的提示词依然会膨胀;
对规划与参数一致性要求上升,稳定性需要继续优化。
这个阶段每个工具只负责自己的逻辑,且工具错误在工具间被隔离,端到端准确率峰值突破到90%,但也常有波动。
第三阶段:设计分子化工具+引入多Agent

----------------------------------------------------
在“设计分子化工具+引入多Agent”这个语境中,Agent(智能体)通常指的是具备一定自主性、感知能力、决策能力和行动能力的软件实体。它不是指传统意义上的“代理”或“中介”,而是一种更高级、智能化的程序模块,能够独立或协作地完成特定任务。
具体来说,在这个系统设计中,Agent 的含义可以从以下几个层面理解:
1. 核心特征
一个典型的 Agent 具备以下特性:
- 自主性(Autonomy):能独立运行,不需要持续的人工干预。
- 反应性(Reactivity):能感知环境(如用户输入、系统状态、数据流)并做出响应。
- 主动性(Proactiveness):不仅能响应,还能主动发起行为以达成目标。
- 社会性(Social Ability):能与其他 Agent 或系统进行通信与协作。
2. 在“分子化工具”中的角色
“分子化工具”意味着将复杂功能拆解为细粒度、可复用、独立运行的“分子级”小工具或服务。每个工具可以被封装为一个 Agent,例如:
- 数据解析 Agent:负责解析输入的分子结构文件(如SMILES、SDF)。
- 性质预测 Agent:调用模型预测分子的物理化学性质(如溶解度、毒性)。
- 优化建议 Agent:根据预测结果提出结构优化方向。
- 文献检索 Agent:自动查找相关化合物的研究文献。
这些 Agent 各司其职,通过消息传递或API调用协同工作。
3. 多 Agent 系统(Multi-Agent System, MAS)的优势
引入多个 Agent 可以实现:
- 模块化与可扩展性:新增功能只需添加新 Agent,不影响整体架构。
- 并行处理:多个 Agent 可同时处理不同任务,提升效率。
- 容错性:某个 Agent 失效,系统仍可部分运行。
- 智能协作:通过协商、任务分配机制,实现复杂工作流自动化。
4. 技术实现形式
这些 Agent 可以是:
- 基于 LLM(大语言模型) 的智能体,理解自然语言指令并调用工具。
- 基于 规则或机器学习模型 的专用程序。
- 使用 Agent 框架(如 LangChain, AutoGPT, MetaGPT, CrewAI)构建的智能模块。
举个例子 🌰
设想一个药物设计平台:
- 用户输入:“帮我优化这个分子,降低毒性,保持活性。”
- 任务分解 Agent 将请求拆解为子任务。
- 毒性预测 Agent 和 活性预测 Agent 并行分析。
- 结构优化 Agent 提出修改建议。
- 决策 Agent 综合评估,输出最优方案。
整个过程由多个 Agent 协同完成,形成一个智能化、自动化的工作流。
✅ 总结:
这里的 Agent 指的是具备智能决策和执行能力的独立软件模块,它们在分子化工具架构中扮演“专家角色”,通过协作实现复杂任务的自动化与智能化。
------------------------------------------------------------------------------------------
将多个相关的原子级工具(元数据检索、语法检查、示例检索等)与特定提示词组合,封装成专门的SQL生成Agent。
这种方式的优势在于:
保持了调用多种工具的灵活性;
通过专门提示词降低单个Agent认知复杂度;
不再需要一个Agent掌握几十上百个工具;
让每个Agent专注使用相关的几个工具,分工更明确、出错率更低
同时,这个阶段设计了三种不同策略的SQL生成Agent,通过一个独立的SQL仲裁Agent选择最佳方案执行。
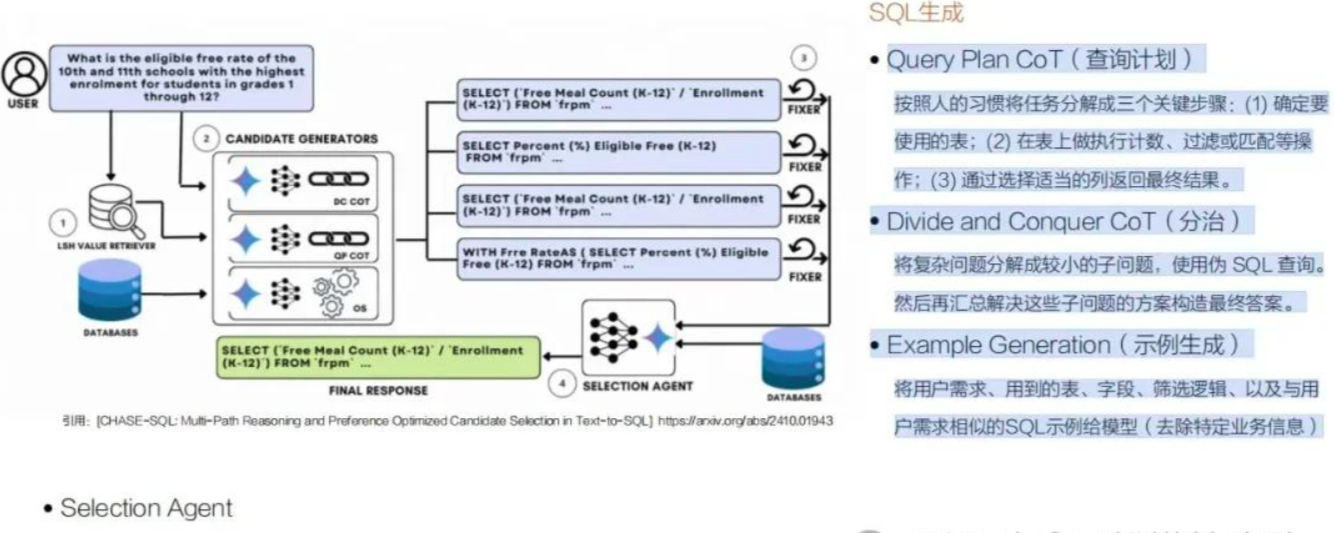
策略1:Query Plan CoT(查询计划)
按人的习惯将任务分解成三个关键步骤:
”确定要使用的表”、”在表上做计数、过滤或匹配操作“、”通过选择适当的列返回最终结果”。
策略2:Divide and Conquer CoT(分治)
将复杂问题分解成较小的子问题,先分别生成伪SQL查询(强调逻辑正确而非语义正确),然后组装起来生成最终可执行的SQL。
策略3:Example Generation(示例生成)
将用户需求、相关表字段、筛选逻辑,以及与用户需求相似的SQL示例给模型(去除特定业务信息)。
举个例子,用户问:"找出2023年北京客户的平均订单金额"
策略1:Query Plan CoT(查询计划)
1. 分析出需要 orders 表和 customers 表,通过 customer_id 关联;
2. 分析出需要过滤:city = '北京'、order_date 在2023年;
3. 分析出需要聚合:计算 total_amount 的平均值;
4. 分析出需要返回“平均订单金额”;
5. 生成SQL:
策略3:Example Generation(根据上下文+sql示例生成)
提供给模型的信息:
(1)用户的需求是要“计算特定城市特定年份的平均订单金额”
(2)相似SQL示例(去除具体业务信息)
最后,由一个仲裁Agent从三个不同策略的Agent分别生成的SQL中,选出一个最合适的来执行,而且这个独立的仲裁Agent只会选择一条最合理的sql,不会对这条sql做任何修改。
这就是高德90%准确率的第五个思路:“通过多个不同SQL生成Agent之间相互补充,将准确率峰值稳定在接近90%的状态。”
第一阶段:通过prompt + 数据基础设施建设,快速达到60分水平的ChatBI;
第二阶段:通过引入Agent和原子工具,拆解复杂prompt,降低错误率,达到90分峰值水平;
第三阶段:通过引入多Agent和分子工具,增加流程稳定性,降低Agent认知复杂度,将准确率稳定在峰值水平。
与其让AI攻克这10%,不如用人机协同。”
通过有限合理地提高人的参与度,来弥补这10%的问题。
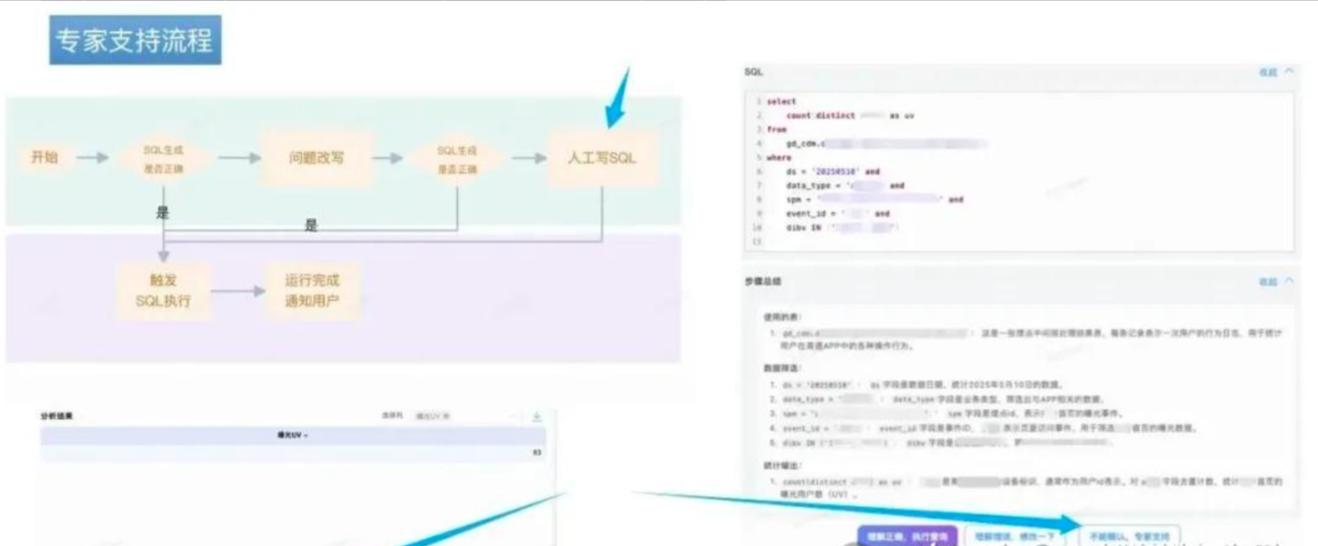
首先,在用户输入前,提供“提问助手引导”,从源头减少奇怪的问题输入;
然后,在回答过程中,给出SQL的逻辑解释,让用户明白SQL是在干什么;
最后,在产出结果后,提供人工介入通道,用户无法判断SQL准确性或对结算结果有疑义时,可以申请人工介入,确保用户总是能走完需求闭环,同时收集用户反馈数据,为系统持续优化提供素材。
Graph-RAG + NER,优化召回精准度
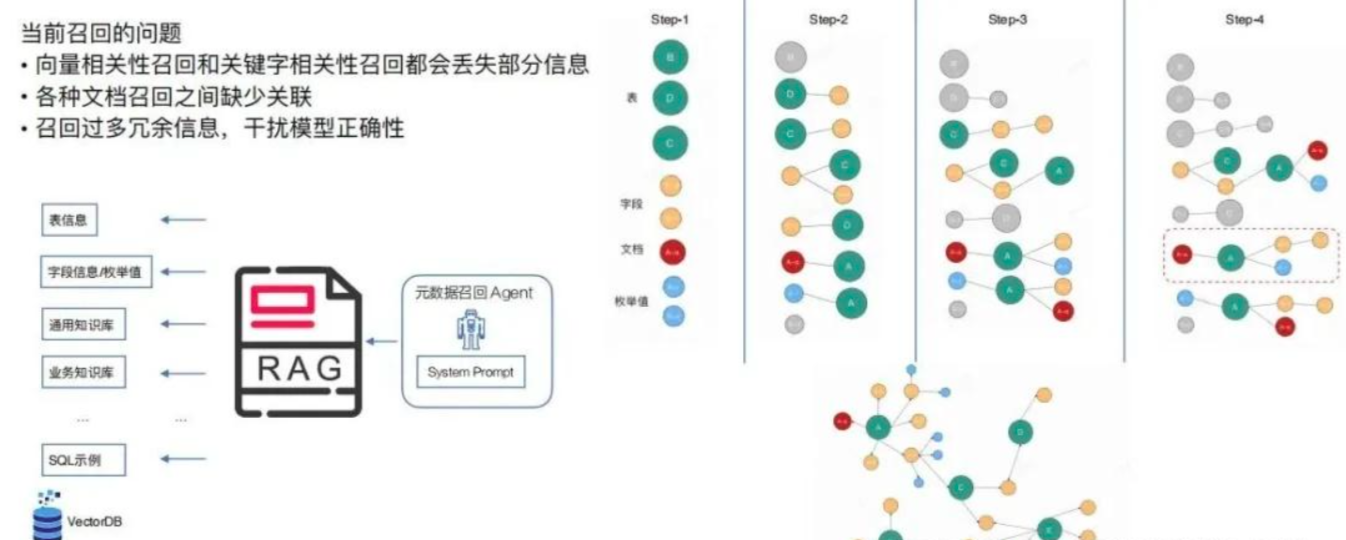
首先,在系统建设阶段,需要用NER(命名实体识别)对所有的知识文档进行信息要素抽取。
包括数据库表结构、字段说明、业务文档、SQL示例等等,从中提取出各种实体,比如表名、字段名、指标名、业务概念这些。
然后,基于这些实体之间的关系来构建知识图谱。
比如,某个字段属于哪张表、某个指标需要哪些字段来计算、不同业务术语之间是同义词关系等等,这样就把原本分散的知识片段通过实体和关系连接成一个网络。
当用户提问的时候,系统再次使用NER从问题中识别出关键实体。
比如,用户说"北京近7天新用户复购率",就能识别出"北京"、"近7天"、"新用户"、"复购率"这些关键实体。
接着,就是在已经构建好的知识图谱中,以这些问题实体为起点进行搜索。
这个搜索过程是分轮进行的。
第一轮:先找到这些实体在图中对应的节点;
第二轮:从这些节点向外扩展一跳,找到直接相关的其他实体。比如"新用户"会连接到"用户注册表"、"复购率"会连接到"订单表"等等。
第三轮:继续扩展,这时候可能会加入关系强度的过滤,只保留那些与用户问题强相关的知识片段。
第四轮:主要做质量控制,确保召回的知识既完整又干净。
最终形成一个知识图,喂给模型作为上下文信息。
方向二:预训练、微调、强化学习

















 159
159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









